1. Introduction
Raft和现有的共识算法类似,但有新的功能:
- 使用更强形式的Leader(如日志只会从Leader流向Follower)
- 使用随机计时器选举Leader(只需在心跳时添加即可)
- 使用新的联合共识(joint consensus)方法,支持集群节点数量变化的场景
2. Replicated State Machines
实现:通常使用复制的副本日志
- 每个节点存储该日志,日志存储了一系列的指令,日志上指令的顺序就是该节点执行命令的顺序
- 每个节点的日志都是一样的,所以每个节点最后都会有一样的状态
共识算法的工作:维持这些复制的副本日志的一致
- 每个节点拥有一个共识模块,它接收客户端请求,将其追加到它的日志中
- 然后该共识模块和其它节点的共识模块通信,保证每份日志包含的内容最终是一样的(请求一样,顺序一样)
- 最后,每个节点按照日志处理请求,并讲结果返回给客户端
共识算法的要求:
- 在非拜占庭错误下,保证结果正确
- 在大多数节点可用下,保证算法可用
- 不依赖时序(?)保证日志的一致性,物理时钟错误或极端消息延迟只有在最坏情况下才导致可用性问题
- 通常情况下,一条指令只需要大多数节点响应一轮RPC调用即可完成,小部分慢节点不会影响整体性能
3. Paxos的问题
- 难以理解
- 没提供具体实现的基础,缺少细节(尤其是multi-Paxos),且对于构建系统不好,增加了复杂度
4. Raft
分为下面4个问题:
- Leader选举:已存在的Leader失效后,必须选举新Leader;
- 日志复制:Leader必须接受客户端的请求日志,将其复制到集群的其它节点,强迫它们接受Leader的日志;
- 安全性:算法保证正确,必须保证以下特性:
- 选举安全:至多一个Leader能在一个任期(term)内被选中;
- Leader Append-Only:Leader自身的日志只能向后追加;
- 日志匹配:若2个日志条目的位置(index)和任期(term)都相同,则该2个条目相同;若2个日志存在一个位置(index)和任期(term)都相同的日志项,那么这2个日志从头到该位置之间的条目都相同;
- Leader完整性:若某个任期(term)内一个日志条目被提交,在所有的更高任期号的Leader日志中,一定存在这个条目;
- 状态机安全:若节点已经将给定位置的日志条目应用到状态机中,则其它节点不会在该位置上应用不同条目。
- 成员变化:成员动态变化时,算法仍然有效。
4.1. Raft基础
4.1.1. 角色
- Leader:有且只有一个,处理请求
- Follower:只处理Leader和Candidate的请求(其它请求路由到Leader)
- Candidate:当集群选举新Leader时出现
角色转变可见下图: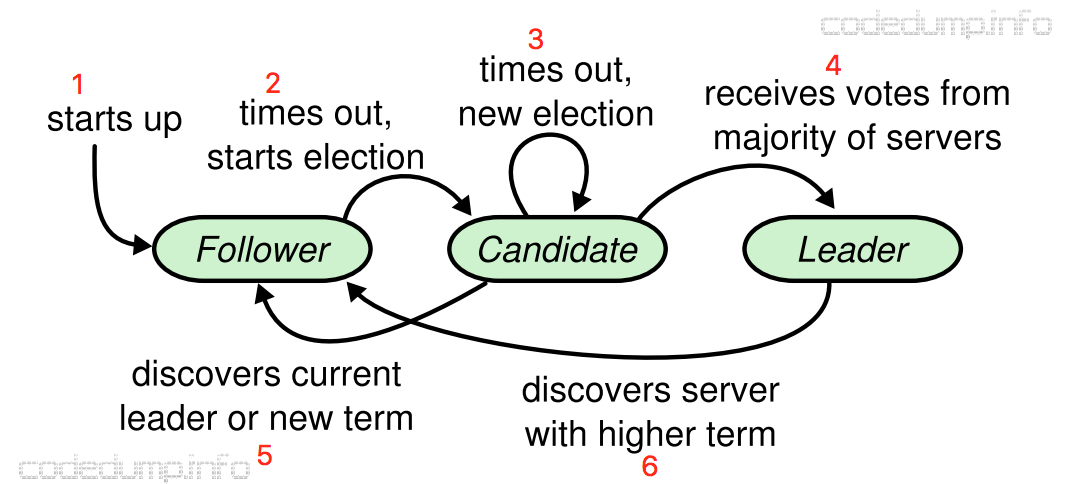
4.1.2. 任期(term)
- 每个任期最多只有一个Leader
- 任期号单调递增
- 每个任期都由Leader选举开始,有多个Candidate尝试成为Leader:
- 若一个Candidate成为Leader,则该任期剩余时间都是Leader
- 否则进行下一个任期的选举
任期实际上是一种递增的逻辑时钟:
- 每个节点存储当前的任期号,节点间交互时捎带这个任期号;
- 若节点收到请求(包括心跳)的任期号大于自己存储的,更新任期号到更大的值;且若节点是Candidate/Leader,会降级成Follower;
- 若节点收到的任期号小于自己存储的,拒绝请求。
4.1.3. RPC
共有3类RPC,前2个是必须的:
RequestVote:选举时由Candidate触发AppendEntries:复制日志时由Leader触发,且提供心跳功能InstallSnapshot:发送快照(日志压缩)时由Leader触发
若RPC没及时响应,则会重试。
4.2. Leader选举
初始状态:全是Follower。
触发选举:Follower在一定时间内(称作election timeout,随机生成)没收到Leader的请求,则开始选举(收到则计时会被重置)。
过程:首先递增自己本地的任期号,切换到Candidate角色,重置计时器,然后向集群的其它所有节点请求RequestVote,而自己将票投给自己,其它节点对该任期的投票只有一次,不会改变,且遵循”先来后到“原则。
以下情况下,Candidate角色会变化:
-
收到半数以上的其它节点的投票(包括自己),则Candidate $\rightarrow$ Leader
-
收到其它节点的
AppendEntries请求(如心跳),且任期号不比自己本地的小,即存在其它Leader,则Candidate $\rightarrow$ Follower;若任期号小于本地的,则拒绝请求。 -
Candidate也有election timeout。当Candidate在此期间,没出现上面2种情况,即选举输赢未知(通常在偶数节点集群下),则继续递增任期号,重新执行选举
为减少第三种情况的概率,election timeout都是随机在一个范围内决定的,因此可以减少split votes的概率
4.3. 日志复制
4.3.1. 主要流程
日志条目:index日志索引号(严格递增,初始为1),term任期号,command数据修改命令。
节点会维护2个日志索引号:
committedIndex:已提交日志的最大索引号,初始为0lastAppliedIndex:日志已应用到状态机的最大索引号,初始为0。可知lastAppliedIndex >= committedIndex。
正常流程:
- 客户端请求被路由到Leader,Leader收到请求,向本地日志添加新条目
- 添加日志结束后,Leader向其它节点发送
AppendEntries同步日志 - 日志复制成功(被同步到半数以上节点应答)后,Leader的
committedIndex指向最新成功的那条记录,此时可返回给应用层结果 - Leader可将日志应用到状态机中,
lastAppliedIndex指向committedIndex - Leader下一次给Follower的
AppendEntries请求中,会捎带committedIndex,Follower收到后会更新自己的committedIndex,此时Follower可应用日志条目到自己的状态机上
4.3.2. 日志不一致的解决方法
当Leader节点失效时,重新选举后,Leader的日志可能和其它Follower不一致。
解决方法:Leader节点的同步日志到Follower上,覆盖与Leader不一致的数据。
节点会额外维护2个日志索引号列表
nextIndex[]:下一次给每个Follower同步日志时的索引位置,初始化为Leader上一条日志的索引值+1matchIndex[]:每个Follower已提交的日志索引位置,初始化为0。可知,正常情况下nextIndex[i] = matchIndex[i] + 1,而极端情况下,等式可能不成立
解决过程:
-
Leader请求中捎带下面几条信息:
-
leaderCommitIndex:Leader已提交的且待同步的最大日志索引号 -
entries[]:待同步的日志项,即nextIndex[i]后的所有日志项,若不存在则为空,即退化成心跳 -
prevLogIndex:待同步项之前的最新的日志索引号 -
prevLogTerm:待同步项之前的最新的日志任期号此外还有
term和leaderId,可让Follower知道Leader是谁,用于实现重定向
-
-
Leader请求Follower
AppendEntries,Follower先检查prevLogIndex和prevLogTerm,若和自己本地的不匹配(如不存在或数据不一样),则返回失败通过该检查,可满足上述的”日志匹配“的属性要求,这可以通过归纳法证明。
-
若Follower通过检查,则再检查新加入的日志项和自己本地的日志项是否有冲突(即是否索引一样,内容不同),若有,则删除之后所有的。然后覆盖新的,并设置自己的
committedIndex = min(leaderCommitIndex, index_last_new_entry),返回成功,此后Follower可应用日志条目到状态机,更改自己的lastAppliedIndex -
Leader收到Follower的结果:
-
若成功,则更新对应Follower的
nextIndex和matchedIndex -
若失败,则递减对应Follower的
nextIndex值,并重试AppendEntries可优化递减次数,但没有必要,因为大量日志不一致的情况不太可能出现
-
4.4. 安全性
4.4.1. 选举限制
成为Leader需要半数以上节点的同意,同意的条件包括:
- 先来后到
- 选举的节点上的日志比本节点更加新(这样才能包含所有已提交的日志条目,保证”Leader完整性“,证明可用反证法,这里略)
实现时,再RequestVote请求中添加2个参数,类似于AppendEntries的检查:
lastLogTermlastLogIndex
若lastLogTerm更高,则日志更加新;若lastLogTerm == curTerm且lastLogIndex >= curIndex,则日志更加新。若日志更加新,则可以投票给该节点,否则必须拒绝。
这保证所有提交的日志条目都会在选举的Leader上,因此日志只会从Leader流向Follower。
4.4.2. 提交前面任期的日志条目
之前任期的日志不能通过半数以上的写入成功作为提交依据,只有当前任期的日志可以。
如图,(c) S1写入了大多数节点,但是是之前的任期,它在标识”提交“前宕机,可能导致数据覆盖:
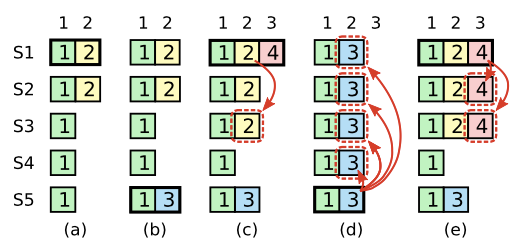
Raft中,Leader只有成功提交当前任期的日志(通过应答个数判断),才能保证Leader之前任期的日志也就被认为是提交成功。(注意斜体,对比(d)图)
满足这个条件,即(e),那么Leader S1之前任期(1和2,不含3,因为3不在S1之前任期的日志内,且3也没在大多数节点内)的日志都能提交,且S5不会成为Leader,之前的日志不会被覆盖。
4.5. Follower和Candidate失效
- Leader无限重试请求,直到成功
- Raft RPCs是幂等的,这意味着Follower会忽略之前处理过的
AppendEntries请求
4.6. 时序与可用性
时间要求:
broadcastTime$«$electionTimeout$«$MTBF。
broadcastTime是广播的平均时间,MTBF为单个节点失效的平均时间。
第一个不等式:防止Follower没收到心跳而再次选举。
第二个不等式:为了让系统稳定运行,当Leader失效时会在electionTimeout内不可用,这个比例要足够小。
一般electionTimeout在10ms到500ms之间。
5. 算法整理
这里直接拷贝论文的图,已经比较详细了:

证明”Leader完整性“:
反证法。
假设任期$t$时,Leader $T$提交了一个日志条目,但这个条目没有存储到未来的某个Leader上,设该Leader是$U$,对应任期是$u$,且$u$是最小的大于$t$的任期(即下一个Leader)。
我们假定$U$上不会产生$T$上刚刚提交的条目,但这会产生矛盾:
- 首先$T$产生的那条日志会存储到集群大部分节点上,而选举$U$也需要大部分节点的投票同意,这两个集合的交集必然非空,假设里面有一个元素,叫做$Voter$
- $Voter $收到$T$的
AppendEntries一定先于收到$U$的RequestVote,否则AppendEntries会失败- $Voter$必然存储了$T$的日志条目,因为Leader从不会删除条目,且Follower只会与Leader冲突时才会删除,显然没有冲突
- $Voter$投票给$U$,说明$U$的日志必须和$Voter$一样新或更加新:
- $U$日志最后一条的任期号和$Voter$一样,那么$U$的日志长度起码和$Voter$一样长。而现在$U$没有$T$的日志,$Voter$却有,这显然发生矛盾
- $U$日志最后一条的任期号比$Voter$的大,那么$U$成为领导人前,之前的领导人(也就是$T$)也必须包含那条任期号大的日志项(根据日志匹配原则),显然$T$没有,也发生了矛盾
综上,Leader完整性成立
6. 算法实现——RequestVote&AppendEntries
6.1. RequestVote
首先根据论文,定义好数据结构。
进入接口:
- 首先需要加锁,最后需要解锁和保存状态(利用
defer) - 进入后,首先要判断2个通用条件,这在任何RPC下都要使用
- 若请求
term小,直接拒绝 - 若请求
term大,自己转成FOLLOWER
- 若请求
- 然后要判断请求日志是否更加新,条件是:
- 若请求
term大,则更加新 - 若请求
term和本地一样,且请求index不小于本地,则更加新
- 若请求
- 满足更加新的条件下,自己的
voteFor必须是空或者请求的candidateId,才能投票给它。注意:投票成功的时候,需要重置election timer,视作心跳,这可由Go的channel实现。
代码如下:
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist()
reply.VoteGranted = false
// if request term is smaller, reject
if args.Term < rf.currentTerm {
reply.Term = rf.currentTerm
return
}
// general rule
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.role = FOLLOWER
rf.voteFor = -1
}
reply.Term = rf.currentTerm
lastLogIndex := rf.lastLogIndex()
lastLogTerm := rf.lastLogTerm()
// grant vote, convert to FOLLOWER & update voteFor
if lastLogTerm < args.LastLogTerm || (lastLogTerm == args.LastLogTerm && lastLogIndex <= args.LastLogIndex) {
// args.log is newer
if rf.voteFor == -1 || rf.voteFor == args.CandidateId {
rf.chanHeartBeat <- true // also see as a hb
reply.VoteGranted = true
rf.role = FOLLOWER
rf.voteFor = args.CandidateId
}
}
}
6.2. AppendEntries
首先根据论文,定义好数据结构。
进入接口:
-
首先需要加锁,最后需要解锁和保存状态(利用
defer) -
进入后,首先要判断2个通用条件,这在任何RPC下都要使用
- 若请求
term小,直接拒绝 - 若请求
term大,自己转成FOLLOWER
对于规则1,不应该认为请求是一个心跳
- 若请求
-
判断请求
prev日志是否包含在本地,只要判断请求的prevIndex是否大于本地的lastIndex:- 若大于,则表明请求的
prev日志不在本地,返回失败,让发送方回退重试 - 否则继续下面的操作
- 若大于,则表明请求的
-
判断
prev日志的term是否和本地的term冲突,获取prev日志对应index,和本地对应index的日志比较term- 若不相等,则冲突,返回失败,让发送方回退重试,并删除本地对应
index之后的所有日志(Figure 8) - 否则继续下面操作
- 若不相等,则冲突,返回失败,让发送方回退重试,并删除本地对应
-
插入日志,到这里,请求的结果是成功的
-
若请求的
leaderCommit比本地大,将本地的commitIndex赋上min(rf.lastLogIndex, args.leaderCommit)
此外,为了让回退更快,可返回一个NextIndex,这样发送方失败后,直接回退到这个位置即可。
代码实现:
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
// Your code here (2A, 2B).
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist()
// if request term is smaller, reject
reply.Success = false
if args.Term < rf.currentTerm {
// outdated, not a heartbeat
reply.Term = rf.currentTerm
return
}
rf.currentTerm = args.Term
// receive hb to restore the timer
rf.chanHeartBeat <- true
// general rule
if args.Term > rf.currentTerm {
rf.role = FOLLOWER
rf.voteFor = -1
}
// args contains larger index that not contained in this follower, reject
if args.PrevLogIndex > rf.lastLogIndex() {
reply.NextIndex = rf.lastLogIndex() + 1
return
}
var baseIdx = rf.log[0].LogIndex
if args.PrevLogIndex > baseIdx {
curPrevLogTerm := rf.log[args.PrevLogIndex-baseIdx].LogTerm
// term not match, delete following logs, return and try next time
if curPrevLogTerm != args.PrevLogTerm {
rf.log = rf.log[args.PrevLogIndex-1-baseIdx:]
return
}
}
if baseIdx <= args.PrevLogIndex {
rf.log = append(rf.log, args.Entries...)
reply.Success = true
}
// final rule
if args.LeaderCommit > rf.commitIndex {
var commitIdx = rf.lastLogIndex()
if commitIdx > args.LeaderCommit {
commitIdx = args.LeaderCommit
}
rf.commitIndex = commitIdx
rf.chanCommit <- commitIdx
}
}
6.3. 发送请求
发送请求后,RPC会收到一个响应,这时候需要根据响应做出修改(注意上锁):
- 对于所有RPC响应:
- 若响应的
term大于本地的term,转成FOLLOWER
- 若响应的
- 对于
RequestVote:- 若被投票认可,则需要计数,这时就可以检查计数是否超过半数,若超过,则变成
LEADER,这样可更加快地转变角色
- 若被投票认可,则需要计数,这时就可以检查计数是否超过半数,若超过,则变成
- 对于
AppendEntries:- 若成功,则更新
nextIndex和matchIndex,数值要根据请求参数决定,而不是本地日志长度决定 - 若失败,将
nextIndex递减(不能减到0),或者若有优化,则根据返回的nextIndex回退
- 若成功,则更新
6.4. 提交和应用日志
由于同步接收AppendEntries回复比较耗时,所以可以用另一种方式实现:
- 对于
LEADER,则可以周期性扫描哪些日志需要提交和应用,这可在周期性心跳中解决 - 对于
FOLLOWER,则可以在应用日志的时候,通知一个goroutine去提交
