quicklist是Redis定义的一个比较复杂的列表数据结构,它结合了ziplist和adlist的优点。也如注释所说,它就是一个ziplist的双向链表(A doubly linked list of ziplists)。
它在3.2版本后统一使用它作为对外暴露的列表(list)数据类型。
它也经常作为队列使用,支持如:
lpush,rpush,lpop,rpop等操作。当然也支持随机访问,不过需要遍历列表,如
lindex,linsert等。
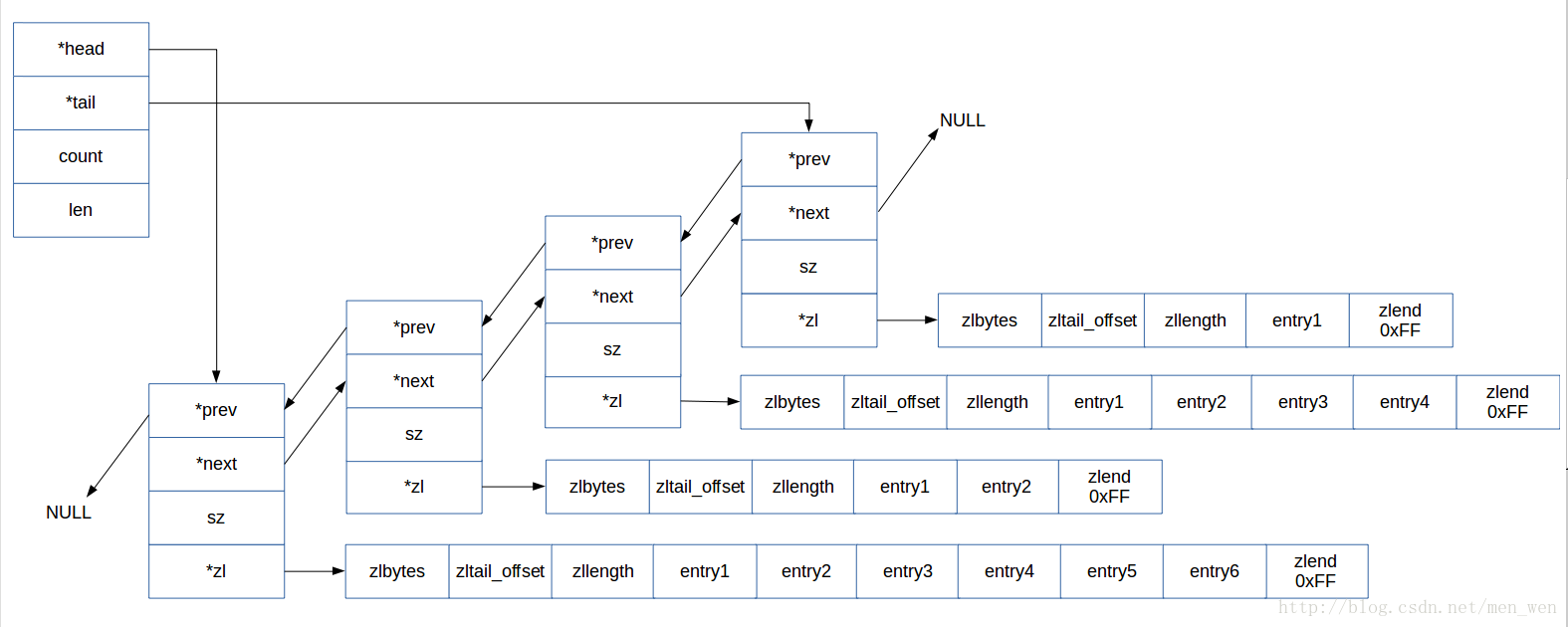
1. 定义
首先定义quicklist的节点quicklistNode,从节点中可以知道:
quicklist是一个双向链表- 每个节点也保存了一个
ziplist列表
typedef struct quicklistNode {
struct quicklistNode *prev; // 前一个节点
struct quicklistNode *next; // 后一个节点
unsigned char *zl; // ziplist列表. ziplist可能被压缩,那么它是一个quicklistZLF指针
unsigned int sz; // zl指向的ziplist数据的大小,且一直表示压缩前的大小
unsigned int count : 16; // ziplist的数据项大小, 16-bit
unsigned int encoding : 2; // 表示编码制式,1:未压缩,2:被LZF算法压缩
unsigned int container : 2; // 表示节点保存的是数据还是ziplist,目前都是固定值2,即ziplist
unsigned int recompress : 1; // 表示前一个节点的ziplist是否被压缩
unsigned int attempted_compress : 1; // (只对测试有用)
unsigned int extra : 10; // 10-bit预留空间
} quicklistNode;
可知,每个节点保存的ziplist会被压缩,这个压缩的ziplist用quicklistZLF表示:
typedef struct quicklistLZF {
unsigned int sz; // 压缩后的数据长度
char compressed[]; // 压缩后的数据
} quicklistLZF;
最后就是整体的quicklist:
typedef struct quicklist {
quicklistNode *head; // 头节点
quicklistNode *tail; // 尾节点
unsigned long count; // 所有ziplist包含的数据项数
unsigned long len; // quicklistNode/ziplist个数
int fill : 16; // 每个ziplist最大数据项个数的值(若为正)或者最大字节数(若为负), 16-bit
unsigned int compress : 16; // 压缩深度,即列表两端各有compress个ziplist不被压缩,中间都被压缩;若值为0,那么所有的ziplist都不被压缩, 16-bit
} quicklist;
后面2项可由配置参数指定:
1
2
3
4
5
6
7
8
# 若fill > 0, 则每个ziplist最多存fill个数据
# 若fill < 0, 则每个ziplist的长度最大为2^(-(fill+1)) KB
# 默认-2, 即每个ziplist的长度最大为8KB
list-max-ziplist-size <fill>
# 若compress > 0, 则quicklist两端各有compress个ziplist不被压缩,中间全部压缩
# 默认0, 即所有ziplist都不压缩
list-compress-depth <compress>
quicklist同样支持迭代器,不过和其他列表大同小异,所以下文就不再叙述。
2. 列表创建
创建很简单,就是初始化一个双向列表,首尾都为空,并初始化一些配置参数:
quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist));
quicklist->head = quicklist->tail = NULL;
quicklist->len = 0;
quicklist->count = 0;
quicklist->compress = 0; // 默认compress = 0
quicklist->fill = -2; // 默认fill = -2
return quicklist;
}
3. 列表项的插入 & 删除
这部分代码说实话还是挺复杂的(涉及到ziplist的压缩、分割等等),但是整体逻辑还是较简单的。
对于插入:
- 根据指定位置,往前/往后插入,首先判断
ziplist是否能容下新数据 - 若容不下新数据,则可能需要
- 分割
ziplist(根据传入的offset分割),或者 - 创建新的
ziplist
- 分割
- 插入新数据
- 可能的话,需要压缩数据
- 更新元数据
对于删除
-
也是找到定位的点(这个定位点不能是被压缩的),执行
ziplist的删除 - 判断
ziplist是否为空,若空则需要删除quicklistNode - 必要时检查和解压缩被压缩的节点,更新元数据
4. 列表查找
给定一个下标,找对应的列表项。
代码也比较简单,所以略过,这里大致说一下流程:
- 首先根据下标,遍历到对应的
ziplistNode(通过它的count字段),取到它的ziplist - 然后在对应的
ziplist中遍历查找对应的项
时间复杂度就是$O(n) + O(m)$,$n$为ziplistNode个数,$m$为ziplist中元素个数。
5. 队列操作
quicklist常作为队列进行首尾节点的操作。
5.1. Push操作
Push操作定义在函数quicklistPush(quicklist *quicklist, void *value, const size_t sz, int where)中,支持两端推入:
void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
int where) {
if (where == QUICKLIST_HEAD) {
quicklistPushHead(quicklist, value, sz);
} else if (where == QUICKLIST_TAIL) {
quicklistPushTail(quicklist, value, sz);
}
}
这里挑选插入头部的函数,也是很简单的,代码和说明参考下面:
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
// 判断原有头的ziplist是否能容纳新数据
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
// 若能,则往这个ziplist头部添加(这里必引发一次memmove)
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(quicklist->head);
} else {
// 若不能
// 则创建新的quicklistNode和对应的ziplist
// 将数据插入ziplist,并将quicklistNode插入列表头部
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node);
// 这里将新quicklistNode插入到quicklist
// 这里可能会触发压缩
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
// 更新元数据
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
这里注意
likely(x)和unlikely(x)宏:#if __GNUC__ >= 3 #define likely(x) __builtin_expect(!!(x), 1) #define unlikely(x) __builtin_expect(!!(x), 0) #else #define likely(x) (x) #define unlikely(x) (x) #endif对于
likely(x),表示x很可能为真;对于unlikely(x),表示x很可能为假。这告诉编译器最有可能执行的分支,让CPU执行更好的分支预判优化,在流水线中减少重新取指令的次数,减少指令跳转,从而加快程序运行速度。
判断ziplist是否有余量在下面这个函数执行,主要还是检查大小和项数,另外即使fill > 0,ziplist的大小不能超过8KB:
REDIS_STATIC int _quicklistNodeAllowInsert(const quicklistNode *node,
const int fill, const size_t sz) {
if (unlikely(!node))
return 0;
int ziplist_overhead;
// 计算ziplist项的prevlen占用的长度
if (sz < 254)
ziplist_overhead = 1;
else
ziplist_overhead = 5;
// 计算ziplist项的encoding占用的长度
if (sz < 64)
ziplist_overhead += 1;
else if (likely(sz < 16384))
ziplist_overhead += 2;
else
ziplist_overhead += 5;
// 新的ziplist的长度
unsigned int new_sz = node->sz + sz + ziplist_overhead;
// 首先,当fill为负数时,是否超过容量大小(默认-2,所以是likely)
if (likely(_quicklistNodeSizeMeetsOptimizationRequirement(new_sz, fill)))
return 1;
// 然后,当fill为正数时,首先ziplist大小不能超过SIZE_SAFETY_LIMIT 8KB
else if (!sizeMeetsSafetyLimit(new_sz))
return 0;
// fill为正数时,检查ziplist的项的个数
else if ((int)node->count < fill)
return 1;
else
return 0;
}
5.2. Pop操作
Pop操作定义在函数quicklistPop(quicklist *quicklist, int where, unsigned char **data, unsigned int *sz, long long *slong):
int quicklistPop(quicklist *quicklist, int where, unsigned char **data,
unsigned int *sz, long long *slong) {
unsigned char *vstr;
unsigned int vlen;
long long vlong;
if (quicklist->count == 0)
return 0;
// 具体的Pop操作,把数据拷贝一份,并将拷贝后数据的指针赋给vstr
int ret = quicklistPopCustom(quicklist, where, &vstr, &vlen, &vlong,
_quicklistSaver);
if (data)
*data = vstr;
if (slong)
*slong = vlong;
if (sz)
*sz = vlen;
return ret;
}
// 这是数据拷贝函数,将data指向的长度尾sz的数据拷贝到新的内存区块上
// 新内存区块是内部malloc的
REDIS_STATIC void *_quicklistSaver(unsigned char *data, unsigned int sz) {
unsigned char *vstr;
if (data) {
vstr = zmalloc(sz);
memcpy(vstr, data, sz);
return vstr;
}
return NULL;
}
最后进入下面的函数:
int quicklistPopCustom(quicklist *quicklist, int where, unsigned char **data,
unsigned int *sz, long long *sval,
void *(*saver)(unsigned char *data, unsigned int sz)) {
unsigned char *p;
unsigned char *vstr;
unsigned int vlen;
long long vlong;
int pos = (where == QUICKLIST_HEAD) ? 0 : -1;
if (quicklist->count == 0)
return 0;
if (data)
*data = NULL;
if (sz)
*sz = 0;
if (sval)
*sval = -123456789;
quicklistNode *node;
// 取quicklist的头/尾节点
if (where == QUICKLIST_HEAD && quicklist->head) {
node = quicklist->head;
} else if (where == QUICKLIST_TAIL && quicklist->tail) {
node = quicklist->tail;
} else {
return 0;
}
// 取对应quicklistNode的ziplist的头/尾项的指针
p = ziplistIndex(node->zl, pos);
// 首先获取这一项的值
if (ziplistGet(p, &vstr, &vlen, &vlong)) {
// 若获取到了
if (vstr) {
// 将数据拷贝,并将该数据指针赋值到data上
if (data)
*data = saver(vstr, vlen);
if (sz)
*sz = vlen;
} else {
if (data)
*data = NULL;
if (sval)
*sval = vlong;
}
// 删除对应项
// 这里可能触发解压缩的操作(当quicklistNode整个被删除)
quicklistDelIndex(quicklist, node, &p);
return 1;
}
return 0;
}
和其他列表的Pop不一样,Redis quicklist的Pop操作会引发至少一次数据拷贝。
6. ziplist的压缩
quicklistNode的zl指针指向的可能是:
- 普通的
ziplist - 压缩过的
ziplist,即quicklistLZF
压缩,如结构名可见,使用了LZF算法。
具体的压缩/解压缩代码,可参考下面的文件:
- 压缩:
lzf_c.c - 解压缩:
lzf_d.c - 头文件:
lzf.h,lzfP.h
