1. Overview
Redis可通过SLAVEOF命令,或者slaveof选项,实现一个服务器去复制另一个服务器的数据,这里被复制的节点是master节点,获取到数据的节点为slave节点。
SLAVEOF addr:port让自己成为addr:port的slave节点。
实现主从复制,主要有2大步:
- 同步:利用
PSYNC命令从master拉取一份RDB存档,它支持断连续传 - 命令传播:同步完成后,master将自己之后已经执行的写命令发送给slave
2. 同步
Redis内部使用PSYNC命令来执行同步操作。
PSYNC格式是:PSYNC runid offset,其中runid是master的ID,offset是slave当前同步的偏移量。
它的大致步骤是:
- slave向master发起连接
-
slave和master握手
- slave向master发送
PSYNC,接收RDB文件数据 - master收到命令:
- 对于初次复制:创建RDB文件,并发给slave(此时的
PSYNC命令为PSYNC ? -1) - 对于断线重连后继续复制:根据
rep-id和offset验证并发送完剩余的部分(从backlog中)
- 对于初次复制:创建RDB文件,并发给slave(此时的
2.1. slave向master发起连接
slave端有下面几个状态:
#define REPL_STATE_NONE 0 // 没有激活复制
#define REPL_STATE_CONNECT 1 // 需要向master连接
#define REPL_STATE_CONNECTING 2 // 正在向master连接
/* --- 握手状态,按照顺序 --- */
#define REPL_STATE_RECEIVE_PONG 3 /* Wait for PING reply */
#define REPL_STATE_SEND_AUTH 4 /* Send AUTH to master */
#define REPL_STATE_RECEIVE_AUTH 5 /* Wait for AUTH reply */
#define REPL_STATE_SEND_PORT 6 /* Send REPLCONF listening-port */
#define REPL_STATE_RECEIVE_PORT 7 /* Wait for REPLCONF reply */
#define REPL_STATE_SEND_IP 8 /* Send REPLCONF ip-address */
#define REPL_STATE_RECEIVE_IP 9 /* Wait for REPLCONF reply */
#define REPL_STATE_SEND_CAPA 10 /* Send REPLCONF capa */
#define REPL_STATE_RECEIVE_CAPA 11 /* Wait for REPLCONF reply */
#define REPL_STATE_SEND_PSYNC 12 /* Send PSYNC */
#define REPL_STATE_RECEIVE_PSYNC 13 /* Wait for PSYNC reply */
/* --- 握手结束 --- */
#define REPL_STATE_TRANSFER 14 // 正在接收master的RDB文件
#define REPL_STATE_CONNECTED 15 // 已连接上master
master端有下面几个状态:
#define SLAVE_STATE_WAIT_BGSAVE_START 6 // 后台RDB需要启动
#define SLAVE_STATE_WAIT_BGSAVE_END 7 // 正在等待后台RDB结束
#define SLAVE_STATE_SEND_BULK 8 // 正在传输RDB数据给slave
#define SLAVE_STATE_ONLINE 9 // RDB传输已完成,正在命令传播
slave向master发起连接是在replicationCron中执行的,它可能会在启动服务器时执行,也会在serverCron时间事件中执行,每秒执行1次。下面是slave向master发起连接的代码:
void replicationCron(void) {
// ...
// 当slave为REPL_STATE_CONNECT时,向master发起连接
if (server.repl_state == REPL_STATE_CONNECT) {
serverLog(LL_NOTICE,"Connecting to MASTER %s:%d",
server.masterhost, server.masterport);
if (connectWithMaster() == C_OK) {
serverLog(LL_NOTICE,"MASTER <-> REPLICA sync started");
}
}
// ...
}
发起连接主要是创建套接字发起连接,并向多路复用器注册一个读写回调(syncWithMaster):
int connectWithMaster(void) {
int fd;
// 1. 创建套接字发起连接(都是非阻塞的)
fd = anetTcpNonBlockBestEffortBindConnect(NULL,
server.masterhost,server.masterport,NET_FIRST_BIND_ADDR);
// ... handle error ...
// 2. 注册读写回调,用于和master同步
if (aeCreateFileEvent(server.el,fd,AE_READABLE|AE_WRITABLE,syncWithMaster,NULL) ==
AE_ERR) {
// ... handle error ...
}
// ...
server.repl_state = REPL_STATE_CONNECTING;
return C_OK;
}
2.2. slave与master握手
当连接成功后,会进入握手阶段,syncWithMaster的回调马上被调用,它里面包含了一些握手的流程,包括:
- 向master发送
PING,并验证响应 - 向master发送
AUTH信息,并验证响应 - 向master发送
REPLCONF,获取配置信息
这里不把
PSYNC纳入握手范围,尽管它属于握手的一部分
a) 发送PING
这里只是double-check一下master有没有存活/网络是否通畅:
void syncWithMaster(aeEventLoop *el, int fd, void *privdata, int mask) {
// ...
if (server.repl_state == REPL_STATE_CONNECTING) {
// ...
// 置REPL_STATE_RECEIVE_PONG
server.repl_state = REPL_STATE_RECEIVE_PONG;
// 发送PING给master(会立刻返回,因为非阻塞)
err = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"PING",NULL);
if (err) goto write_error;
return;
}
/* Receive the PONG command. */
if (server.repl_state == REPL_STATE_RECEIVE_PONG) {
// 阻塞读取master的PONG
err = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL);
// ... handler errors ...
// 置REPL_STATE_SEND_AUTH
server.repl_state = REPL_STATE_SEND_AUTH;
}
// ...
}
b) 发送验证消息
若Redis配置了masterauth,那么需要向master发送验证信息,即AUTH命令。
这里的代码和2.2.a类似:
void syncWithMaster(aeEventLoop *el, int fd, void *privdata, int mask) {
// ...
if (server.repl_state == REPL_STATE_SEND_AUTH) {
if (server.masterauth) {
// 发送AUTH命令
err = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"AUTH",server.masterauth,NULL);
if (err) goto write_error;
// 设置为REPL_STATE_RECEIVE_AUTH
server.repl_state = REPL_STATE_RECEIVE_AUTH;
return;
} else {
// 不需要就之间进入REPLCONF的阶段
server.repl_state = REPL_STATE_SEND_PORT;
}
}
if (server.repl_state == REPL_STATE_RECEIVE_AUTH) {
// 阻塞接收AUTH响应
err = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL);
// ... handler error ...
// 进入REPLCONF的阶段
server.repl_state = REPL_STATE_SEND_PORT;
}
// ...
}
c) 同步REPLCONF配置信息
后面就会进入REPLCONF,把自己的信息告诉给master,按照顺序是:
- slave监听的端口
- slave的IP
- master对于主从复制的支持能力(如是否支持
PSYNC2/EOF等)
这些响应返回错误都不要紧,因为它们返回的结果只是打出日志而已。
而根据Socket的连接,服务端就可以知道客户端的地址和端口的
最后状态会转移到REPL_STATE_SEND_PSYNC,准备发起PSYNC请求,也就是下一节准备要说明的。
上述的代码和2.2.a.以及2.2.b.差别不大,区别在于发送的命令不一样。因此代码略。
2.3. PSYNC
a) Slave发送PSYNC请求
接下来就会进行PSYNC命令请求。
void syncWithMaster(aeEventLoop *el, int fd, void *privdata, int mask) {
// ...
if (server.repl_state == REPL_STATE_SEND_PSYNC) {
// 1. 尝试发送PSYNC指令
if (slaveTryPartialResynchronization(fd,0) == PSYNC_WRITE_ERROR) {
// ... Handling errors ...
}
server.repl_state = REPL_STATE_RECEIVE_PSYNC;
return;
}
// ...
// 2. 读取MASTER响应的PSYNC数据
psync_result = slaveTryPartialResynchronization(fd,1);
if (psync_result == PSYNC_WAIT_REPLY) return;
if (psync_result == PSYNC_TRY_LATER) goto error;
if (psync_result == PSYNC_CONTINUE) {
serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization.");
return;
}
disconnectSlaves(); // 断开自己的slave,强制这些slave向自己同步
freeReplicationBacklog(); /* Don't allow our chained slaves to PSYNC. */
//...
}
首先是发送PSYNC命令,它尝试读取cache_master的reploff,并由该值生成PSYNC命令,正常情况下:
#define PSYNC_WRITE_ERROR 0 // 发送PSYNC命令错误
#define PSYNC_WAIT_REPLY 1 // 等待PSYNC响应
#define PSYNC_CONTINUE 2
#define PSYNC_FULLRESYNC 3
#define PSYNC_NOT_SUPPORTED 4
#define PSYNC_TRY_LATER 5
int slaveTryPartialResynchronization(int fd, int read_reply) {
char *psync_replid;
char psync_offset[32];
sds reply;
// 这里read_reply == 0,且开始生成命令
if (!read_reply) {
server.master_initial_offset = -1;
if (server.cached_master) {
// 若cached master,则说明复制RDB文件在过程之中,把offset读出来
// 生成的命令是"PSYNC <cache_master->replid> <cache_master->reploff>+1"
psync_replid = server.cached_master->replid;
snprintf(psync_offset,sizeof(psync_offset),"%lld", server.cached_master->reploff+1);
serverLog(LL_NOTICE,"Trying a partial resynchronization (request %s:%s).", psync_replid, psync_offset);
} else {
// 若没有cached master,则说明之前没进行RDB文件复制
// 那么命令就会是"PSYNC ? -1"
serverLog(LL_NOTICE,"Partial resynchronization not possible (no cached master)");
psync_replid = "?";
memcpy(psync_offset,"-1",3);
}
// 发送PSYNC命令
reply = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"PSYNC",psync_replid,psync_offset,NULL);
if (reply != NULL) {
// handle errors...
}
return PSYNC_WAIT_REPLY;
}
// ...
}
b) Master处理PSYNC请求
Master在syncCommand(client *c)处理PSYNC请求:
void syncCommand(client *c) {
// ...
// 当client是从服务器
// 或没有和自己(MASTER)产生连接关系
// 或client响应缓冲区没清空,忽略或直接返回错误
// ...
if (!strcasecmp(c->argv[0]->ptr,"psync")) {
// 若为PSYNC命令
// 尝试增量同步,成功则返回
if (masterTryPartialResynchronization(c) == C_OK) {
server.stat_sync_partial_ok++;
return;
} else {
// 失败,则强制全量同步
char *master_replid = c->argv[1]->ptr;
if (master_replid[0] != '?') server.stat_sync_partial_err++;
}
} else {
// 若为SYNC,则执行全量同步
c->flags |= CLIENT_PRE_PSYNC;
}
server.stat_sync_full++;
c->replstate = SLAVE_STATE_WAIT_BGSAVE_START;
// ...
// CASE 1: BGSAVE正在执行,且数据同步到磁盘
if (server.rdb_child_pid != -1 &&
server.rdb_child_type == RDB_CHILD_TYPE_DISK)
{
client *slave;
listNode *ln;
listIter li;
listRewind(server.slaves,&li);
// 遍历slave,寻找某个slave正在等待RDB的创建完成
while((ln = listNext(&li))) {
slave = ln->value;
if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_END) break;
}
if (ln && ((c->slave_capa & slave->slave_capa) == slave->slave_capa)) {
// 找到,且有能力接收数据,则
// 把slave的输出缓冲区内容拷贝到这个client的输出缓冲区中
// 且设置这个client的initial offset
copyClientOutputBuffer(c,slave);
replicationSetupSlaveForFullResync(c,slave->psync_initial_offset);
serverLog(LL_NOTICE,"Waiting for end of BGSAVE for SYNC");
} else {
// 没找到/没能力,报错
serverLog(LL_NOTICE,"Can't attach the replica to the current BGSAVE. Waiting for next BGSAVE for SYNC");
}
// CASE 2: RDB正在创建,且写入socket
} else if (server.rdb_child_pid != -1 &&
server.rdb_child_type == RDB_CHILD_TYPE_SOCKET)
{
// 不需要操作,忽略
serverLog(LL_NOTICE,"Current BGSAVE has socket target. Waiting for next BGSAVE for SYNC");
// CASE 3: (MAIN)当前没在创建RDB
} else {
if (server.repl_diskless_sync && (c->slave_capa & SLAVE_CAPA_EOF)) {
// 若是无盘RDB,那么忽略即可
if (server.repl_diskless_sync_delay)
serverLog(LL_NOTICE,"Delay next BGSAVE for diskless SYNC");
} else {
// 若RDB和AOF都没有开,就执行后台RDB
if (server.aof_child_pid == -1) {
startBgsaveForReplication(c->slave_capa);
} else {
// AOF重写开了,是不能执行后台RDB
serverLog(LL_NOTICE,
"No BGSAVE in progress, but an AOF rewrite is active. "
"BGSAVE for replication delayed");
}
}
}
return;
}
首先是尝试进行增量更新,若认为可以增量的同步,则会:
- 响应Slave
+CONTINUE - 把
backlog中的数据同步给Slave
int masterTryPartialResynchronization(client *c) {
long long psync_offset, psync_len;
char *master_replid = c->argv[1]->ptr;
char buf[128];
int buflen;
// PSYNC命令parse失败,需要全量更新
if (getLongLongFromObjectOrReply(c,c->argv[2],&psync_offset,NULL) !=
C_OK) goto need_full_resync;
// 自己的replid和slave发来的runid不一样(说明runid/replid不匹配)
// 或者slave发来的runid是master的replid2,
// 且offset比master自己的replid2的offset大(说明SLAVE数据更加新,MASTER是旧的)
// 则需要重新全量同步
if (strcasecmp(master_replid, server.replid) &&
(strcasecmp(master_replid, server.replid2) ||
psync_offset > server.second_replid_offset)) {
if (master_replid[0] != '?') {
if (strcasecmp(master_replid, server.replid) &&
strcasecmp(master_replid, server.replid2))
{
serverLog(LL_NOTICE,"Partial resynchronization not accepted: "
"Replication ID mismatch (Replica asked for '%s', my "
"replication IDs are '%s' and '%s')",
master_replid, server.replid, server.replid2);
} else {
serverLog(LL_NOTICE,"Partial resynchronization not accepted: "
"Requested offset for second ID was %lld, but I can reply "
"up to %lld", psync_offset, server.second_replid_offset);
}
} else {
// 若"PSYNC ? -1",则执行全量同步
serverLog(LL_NOTICE,"Full resync requested by replica %s",
replicationGetSlaveName(c));
}
goto need_full_resync;
}
// 若MASTER的backlog没创建
// 或MASTER backlog第一条数据新于SLAVE最新的数据
// 或MASTER backlog最后一条/最新数据旧于SLAVE最新的数据
// 则需要全量同步
if (!server.repl_backlog ||
psync_offset < server.repl_backlog_off ||
psync_offset > (server.repl_backlog_off + server.repl_backlog_histlen))
{
// ...
goto need_full_resync;
}
// 到这里,说明可以执行部分增量更新
// 这里设置客户端状态为SLAVE
// 并响应+CONTINUE
// 然后把backlog的数据传给SLAVE(从offset开始)
c->flags |= CLIENT_SLAVE;
c->replstate = SLAVE_STATE_ONLINE;
c->repl_ack_time = server.unixtime;
c->repl_put_online_on_ack = 0;
listAddNodeTail(server.slaves,c);
if (c->slave_capa & SLAVE_CAPA_PSYNC2) {
buflen = snprintf(buf,sizeof(buf),"+CONTINUE %s\r\n", server.replid);
} else {
buflen = snprintf(buf,sizeof(buf),"+CONTINUE\r\n");
}
// 1. 响应+CONTINUE
if (write(c->fd,buf,buflen) != buflen) {
freeClientAsync(c);
return C_OK;
}
// 2. 传输backlog,把backlog数据写入slave客户端响应缓冲,等待下一次事件循环写出
psync_len = addReplyReplicationBacklog(c,psync_offset);
// ...
return C_OK;
need_full_resync:
return C_ERR;
}
这里可见有一个backlog的东西。它是一个环形的缓冲区,存储了最近传播的命令,可以说是一个备份:
typedef struct redisServer {
// ...
long long master_repl_offset; // Master全局的复制偏移量(只要命令添加到backlog,该值就会增加)
char *repl_backlog; // Backlog缓冲,环形缓冲
long long repl_backlog_size; // Backlog缓冲的大小
long long repl_backlog_histlen; // Backlog缓冲实际占用的大小
long long repl_backlog_index; // Backlog缓冲当前的位置
long long repl_backlog_off; // 该值等于master_repl_offset-repl_backlog_histlen,即Backlog中第一条数据的全局复制偏移
// ...
}
它默认大小是1MB,用于备份最近传播给Slave的命令,当Slave意外宕机,并重连,则可以通过backlog中的数据来让Slave跟上Master的进度,即用于增量同步。
若增量同步失败,则会尝试全量更新:
- 创建RDB后台任务
- RDB生成完毕后,还需要把
PSYNC的响应返回给slave,这里是全量同步,所以是+FULLRESYNC
而RDB文件的传输在serverCron中执行(后面会说)
int startBgsaveForReplication(int mincapa) {
// ...
if (!socket_target) {
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
// 初始是SLAVE_STATE_WAIT_BGSAVE_START
if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START) {
// 发送PSYNC响应给slaves(从initial offset开始)
replicationSetupSlaveForFullResync(slave,
getPsyncInitialOffset());
}
}
}
// ...
}
int replicationSetupSlaveForFullResync(client *slave, long long offset) {
char buf[128];
int buflen;
slave->psync_initial_offset = offset;
// 置状态为SLAVE_STATE_WAIT_BGSAVE_END,等待RDB数据传播完毕
slave->replstate = SLAVE_STATE_WAIT_BGSAVE_END;
server.slaveseldb = -1;
if (!(slave->flags & CLIENT_PRE_PSYNC)) {
// 返回+FULLRESYNC的响应,说明MASTER已开启后台RDB并正在进行全量同步传输
buflen = snprintf(buf,sizeof(buf),"+FULLRESYNC %s %lld\r\n",
server.replid,offset);
if (write(slave->fd,buf,buflen) != buflen) {
freeClientAsync(slave);
return C_ERR;
}
}
return C_OK;
}
c) Slave接收Master响应
然后slave接收服务端响应:
int slaveTryPartialResynchronization(int fd, int read_reply) {
char *psync_replid;
char psync_offset[32];
sds reply;
// ...
// read part
// 读取服务端的PSYNC响应
reply = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL);
if (sdslen(reply) == 0) {
// 返回空,先不改变状态,下一轮再试(可当作一次ping)
sdsfree(reply);
return PSYNC_WAIT_REPLY;
}
aeDeleteFileEvent(server.el,fd,AE_READABLE);
if (!strncmp(reply,"+FULLRESYNC",11)) {
// 若响应+FULLRESYNC,即全量同步
char *replid = NULL, *offset = NULL;
// 则从响应里提取master_replid和master_initial_offset
// 并把cache_master清除,准备接收全量复制的数据
replid = strchr(reply,' ');
if (replid) {
replid++;
offset = strchr(replid,' ');
if (offset) offset++;
}
if (!replid || !offset || (offset-replid-1) != CONFIG_RUN_ID_SIZE) {
// ... handle error...
} else {
memcpy(server.master_replid, replid, offset-replid-1);
server.master_replid[CONFIG_RUN_ID_SIZE] = '\0';
server.master_initial_offset = strtoll(offset,NULL,10);
// ...
}
replicationDiscardCachedMaster();
sdsfree(reply);
return PSYNC_FULLRESYNC;
}
if (!strncmp(reply,"+CONTINUE",9)) {
// 若响应是+CONTINUE,则为增量同步
// ...
char *start = reply+10;
char *end = reply+9;
while(end[0] != '\r' && end[0] != '\n' && end[0] != '\0') end++;
if (end-start == CONFIG_RUN_ID_SIZE) {
char new[CONFIG_RUN_ID_SIZE+1];
memcpy(new,start,CONFIG_RUN_ID_SIZE);
new[CONFIG_RUN_ID_SIZE] = '\0';
// 检查,必要时更改成新的cached_master
if (strcmp(new,server.cached_master->replid)) {
serverLog(LL_WARNING,"Master replication ID changed to %s",new);
memcpy(server.replid2,server.cached_master->replid,
sizeof(server.replid2));
server.second_replid_offset = server.master_repl_offset+1;
memcpy(server.replid,new,sizeof(server.replid));
memcpy(server.cached_master->replid,new,sizeof(server.replid));
disconnectSlaves();
}
}
sdsfree(reply);
// 把cached_master设置成server.master
// 并注册readQueryFromClient读事件,读取Master的backlog数据
replicationResurrectCachedMaster(fd);
if (server.repl_backlog == NULL) createReplicationBacklog();
return PSYNC_CONTINUE;
}
if (!strncmp(reply,"-NOMASTERLINK",13) ||
!strncmp(reply,"-LOADING",8))
{
// 改情况,说明现在不能PSYNC,需要等待
serverLog(LL_NOTICE,
"Master is currently unable to PSYNC "
"but should be in the future: %s", reply);
sdsfree(reply);
return PSYNC_TRY_LATER;
}
if (strncmp(reply,"-ERR",4)) {
// 若返回+ERR,说明对方不支持PSYNC
serverLog(LL_WARNING,
"Unexpected reply to PSYNC from master: %s", reply);
} else {
serverLog(LL_NOTICE,
"Master does not support PSYNC or is in "
"error state (reply: %s)", reply);
}
sdsfree(reply);
// 把cached_master清除
replicationDiscardCachedMaster();
return PSYNC_NOT_SUPPORTED;
}
返回到syncWithMaster函数,处理返回的结果:
void syncWithMaster(aeEventLoop *el, int fd, void *privdata, int mask) {
// ...
if (psync_result == PSYNC_WAIT_REPLY) return;
if (psync_result == PSYNC_TRY_LATER) goto error;
// 若响应返回+CONTINUE,则说明SLAVE的增量同步被接收,直接返回
if (psync_result == PSYNC_CONTINUE) {
serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization.");
return;
}
// ...
// 若返回+ERR,说明PSYNC不支持,则直接发送SYNC命令执行全量同步
if (psync_result == PSYNC_NOT_SUPPORTED) {
serverLog(LL_NOTICE,"Retrying with SYNC...");
if (syncWrite(fd,"SYNC\r\n",6,server.repl_syncio_timeout*1000) == -1) {
serverLog(LL_WARNING,"I/O error writing to MASTER: %s",
strerror(errno));
goto error;
}
}
// ...
// 这里就是+FULLRESYNC或者SYNC的全同步情形
// 首先创建临时RDB文件
while(maxtries--) {
snprintf(tmpfile,256,
"temp-%d.%ld.rdb",(int)server.unixtime,(long int)getpid());
dfd = open(tmpfile,O_CREAT|O_WRONLY|O_EXCL,0644);
if (dfd != -1) break;
sleep(1);
}
// ...
// 然后注册读取RDB文件数据的回调,用于接收Master RDB的数据
// (fd注册的读写事件回调之前已被消除)
if (aeCreateFileEvent(server.el,fd, AE_READABLE,readSyncBulkPayload,NULL)
== AE_ERR) {
serverLog(LL_WARNING,
"Can't create readable event for SYNC: %s (fd=%d)",
strerror(errno),fd);
goto error;
}
// 最后置状态为REPL_STATE_TRANSFER
server.repl_state = REPL_STATE_TRANSFER;
// ...
}
d) +FULLRESYNC:Master发送RDB数据
这个部分是在RDB后台任务完成后执行,数据同步于serverCron这个周期函数执行,具体的调用链为:
serverCron
=> backgroundSaveDoneHandler
==> backgroundSaveDoneHandlerDisk
===> updateSlavesWaitingBgsave
====> 注册写回调sendBulkToSlave
当slave socket的写就绪后,sendBulkToSlave会被调用:
- 且若RDB没发送完,每次发送16KB数据,发完后,等socket再次写就绪,它会被再次调用,发送下一轮16KB的数据
- 直到RDB传输完毕,写回调被移除
这里sendBulkToSlave把数据发给slave节点:
void sendBulkToSlave(aeEventLoop *el, int fd, void *privdata, int mask) {
client *slave = privdata;
UNUSED(el);
UNUSED(mask);
char buf[PROTO_IOBUF_LEN];
ssize_t nwritten, buflen;
// 1. 发送RDB之前,先把RDB长度发给slave
if (slave->replpreamble) {
nwritten = write(fd,slave->replpreamble,sdslen(slave->replpreamble));
if (nwritten == -1) {
serverLog(LL_VERBOSE,"Write error sending RDB preamble to replica: %s",
strerror(errno));
freeClient(slave);
return;
}
server.stat_net_output_bytes += nwritten;
sdsrange(slave->replpreamble,nwritten,-1);
if (sdslen(slave->replpreamble) == 0) {
sdsfree(slave->replpreamble);
slave->replpreamble = NULL;
} else {
return;
}
}
// 2. 开始发送RDB数据
lseek(slave->repldbfd,slave->repldboff,SEEK_SET);
// 每次发送PROTO_IOBUF_LEN(16KB)
buflen = read(slave->repldbfd,buf,PROTO_IOBUF_LEN);
if (buflen <= 0) {
// ...error handle...
}
if ((nwritten = write(fd,buf,buflen)) == -1) {
// ...error handle...
}
// 更新offset,下次发送时从这里开始
slave->repldboff += nwritten;
server.stat_net_output_bytes += nwritten;
if (slave->repldboff == slave->repldbsize) {
close(slave->repldbfd);
slave->repldbfd = -1;
// 写完,则移除本写回调
aeDeleteFileEvent(server.el,slave->fd,AE_WRITABLE);
putSlaveOnline(slave);
}
}
e) +FULLRESYNC:Slave接收RDB数据
在c)中最后,可知RDB数据的接收于回调readSyncBulkPayload函数实现。
它也是一个回调,当读就绪时就会读取Master发来的数据:
- 若没读完则会等待读再次就绪时继续读取,并定期刷盘
- 若读完了,则保存并重命名RDB文件,清空DB并加载RDB数据
#define REPL_MAX_WRITTEN_BEFORE_FSYNC (1024*1024*8) /* 8 MB */
void readSyncBulkPayload(aeEventLoop *el, int fd, void *privdata, int mask) {
char buf[4096];
ssize_t nread, readlen, nwritten;
off_t left;
UNUSED(el);
UNUSED(privdata);
UNUSED(mask);
static char eofmark[CONFIG_RUN_ID_SIZE];
static char lastbytes[CONFIG_RUN_ID_SIZE];
static int usemark = 0;
if (server.repl_transfer_size == -1) {
// 1. 先读第一行,读取数据的长度/头
if (syncReadLine(fd,buf,1024,server.repl_syncio_timeout*1000) == -1) {
serverLog(LL_WARNING,
"I/O error reading bulk count from MASTER: %s",
strerror(errno));
goto error;
}
// ...处理长度数据...
}
// usemark=0 => socket
// usemark=1 => disk
if (usemark) {
readlen = sizeof(buf);
} else {
left = server.repl_transfer_size - server.repl_transfer_read;
readlen = (left < (signed)sizeof(buf)) ? left : (signed)sizeof(buf);
}
// 2. 读取MASTER的数据
nread = read(fd,buf,readlen);
if (nread <= 0) {
serverLog(LL_WARNING,"I/O error trying to sync with MASTER: %s",
(nread == -1) ? strerror(errno) : "connection lost");
cancelReplicationHandshake();
return;
}
server.stat_net_input_bytes += nread;
int eof_reached = 0;
// ...
server.repl_transfer_lastio = server.unixtime;
// 3. 把读到的数据写到临时RDB文件里
if ((nwritten = write(server.repl_transfer_fd,buf,nread)) != nread) {
serverLog(LL_WARNING,"Write error or short write writing to the DB dump file needed for MASTER <-> REPLICA synchronization: %s",
(nwritten == -1) ? strerror(errno) : "short write");
goto error;
}
server.repl_transfer_read += nread;
// ...
// 4. 定期刷数据(fsync)到磁盘,默认每8MB刷一次
if (server.repl_transfer_read >=
server.repl_transfer_last_fsync_off + REPL_MAX_WRITTEN_BEFORE_FSYNC)
{
off_t sync_size = server.repl_transfer_read -
server.repl_transfer_last_fsync_off;
// 这里刷盘
rdb_fsync_range(server.repl_transfer_fd,
server.repl_transfer_last_fsync_off, sync_size);
server.repl_transfer_last_fsync_off += sync_size;
}
// ...
// 5. 若已经读完了RDB文件数据
if (eof_reached) {
int aof_is_enabled = server.aof_state != AOF_OFF;
// ... Reject when RDB background task exists ...
// 5.1. 重命名RDB临时文件
if (rename(server.repl_transfer_tmpfile,server.rdb_filename) == -1) {
serverLog(LL_WARNING,"Failed trying to rename the temp DB into dump.rdb in MASTER <-> REPLICA synchronization: %s", strerror(errno));
cancelReplicationHandshake();
return;
}
serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Flushing old data");
// 5.2. 暂时停止AOF
if(aof_is_enabled) stopAppendOnly();
// 5.3. 清空所有数据库
signalFlushedDb(-1);
emptyDb(
-1,
server.repl_slave_lazy_flush ? EMPTYDB_ASYNC : EMPTYDB_NO_FLAGS,
replicationEmptyDbCallback);
// 5.4. 移除自己和Master通信套接字的读事件
aeDeleteFileEvent(server.el,server.repl_transfer_s,AE_READABLE);
serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Loading DB in memory");
rdbSaveInfo rsi = RDB_SAVE_INFO_INIT;
// 5.5. 加载RDB数据
if (rdbLoad(server.rdb_filename,&rsi) != C_OK) {
// ...handle error...
return;
}
zfree(server.repl_transfer_tmpfile);
close(server.repl_transfer_fd);
// 5.6. 创建一个Master客户端
replicationCreateMasterClient(server.repl_transfer_s,rsi.repl_stream_db);
// 5.7. RDB加载完毕,置状态为REPL_STATE_CONNECTED,准备接收Master发过来的复制请求
server.repl_state = REPL_STATE_CONNECTED;
server.repl_down_since = 0;
memcpy(server.replid,server.master->replid,sizeof(server.replid));
server.master_repl_offset = server.master->reploff; // 同步offset
clearReplicationId2();
if (server.repl_backlog == NULL) createReplicationBacklog();
serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Finished with success");
// 5.8. 重启AOF
if (aof_is_enabled) restartAOFAfterSYNC();
}
return;
error:
cancelReplicationHandshake();
return;
}
若进入第5步,并完成了接收,那么PSYNC阶段就完成了。
f) +CONTINUE:Slave接收backlog数据
在处理+CONTINUE响应时,会调用函数replicationResurrectCachedMaster,它:
- 不仅把
cached_master置成正式的master - 且注册
readQueryFromClient事件,当读就绪时,读取backlog以及后续命令传播的命令数据,并以正常命令的形式执行处理
void replicationResurrectCachedMaster(int newfd) {
// 设置master = cached_master
server.master = server.cached_master;
// ...
// 把master添加到client链表,并注册readQueryFromClient事件,读取backlog信息
linkClient(server.master);
if (aeCreateFileEvent(server.el, newfd, AE_READABLE,
readQueryFromClient, server.master)) {
// handle error...
}
// 若master有遗留数据要输出则还得注册sendReplyToClient事件
if (clientHasPendingReplies(server.master)) {
if (aeCreateFileEvent(server.el, newfd, AE_WRITABLE,
sendReplyToClient, server.master)) {
// handle error...
}
}
}
而readQueryFromClient这个回调之前提及过,在Slave中:
- 首先读取并执行命令
- 然后把命令传播给自己下属的Slave中
- 维护Master客户端的
reploff - 根据上面的偏移,发送
pending_querybuf的数据(这种情况下,不仅querybuf有数据,pending_querybuf也有数据)
- 维护Master客户端的
3. 命令传播
3.1. Master端
当同步执行完成后,Master会将成功的写命令传播给Slaves,它会调用propagate函数,这在之前的文章中有所提及,它优先同步本机AOF,然后传播给Slave节点:
void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc,
int flags) {
if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF)
feedAppendOnlyFile(cmd,dbid,argv,argc); // 添加到AOF缓冲队列,等待serverCron刷盘
if (flags & PROPAGATE_REPL)
replicationFeedSlaves(server.slaves,dbid,argv,argc); // 传播给Slaves
}
这里主要是replicationFeedSlaves函数,它干三件事:
- (必要时)传播
SELECT命令,并写入backlog - 把命令写入
backlog - 把命令写入Slave(客户端)的响应缓冲区,待事件循环开始前/事件循环执行写文件事件时,输出给Slave
void replicationFeedSlaves(list *slaves, int dictid, robj **argv, int argc) {
listNode *ln;
listIter li;
int j, len;
char llstr[LONG_STR_SIZE];
// 若自己不是最顶端的master,直接返回
if (server.masterhost != NULL) return;
// 若backlog为空,或没有配置slave,也直接返回
if (server.repl_backlog == NULL && listLength(slaves) == 0) return;
// ...
// 有必要,先传播SELECT,保证所有的slave选择同一个数据库
if (server.slaveseldb != dictid) {
robj *selectcmd;
if (dictid >= 0 && dictid < PROTO_SHARED_SELECT_CMDS) {
selectcmd = shared.select[dictid];
} else {
int dictid_len;
dictid_len = ll2string(llstr,sizeof(llstr),dictid);
selectcmd = createObject(OBJ_STRING,
sdscatprintf(sdsempty(),
"*2\r\n$6\r\nSELECT\r\n$%d\r\n%s\r\n",
dictid_len, llstr));
}
// 把SELECT命令添加到backlog
if (server.repl_backlog) feedReplicationBacklogWithObject(selectcmd);
// 把SELECT命令发给/返回给slaves(slave在master眼里是客户端)
listRewind(slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
// 不写还没执行同步的slave
if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START) continue;
// SELECT命令添加到slave(客户端)的响应缓冲
addReply(slave,selectcmd);
}
if (dictid < 0 || dictid >= PROTO_SHARED_SELECT_CMDS)
decrRefCount(selectcmd);
}
server.slaveseldb = dictid;
// 然后把命令写到backlog中
if (server.repl_backlog) {
char aux[LONG_STR_SIZE+3];
/* Add the multi bulk reply length. */
aux[0] = '*';
len = ll2string(aux+1,sizeof(aux)-1,argc);
aux[len+1] = '\r';
aux[len+2] = '\n';
feedReplicationBacklog(aux,len+3);
for (j = 0; j < argc; j++) {
long objlen = stringObjectLen(argv[j]);
aux[0] = '$';
len = ll2string(aux+1,sizeof(aux)-1,objlen);
aux[len+1] = '\r';
aux[len+2] = '\n';
feedReplicationBacklog(aux,len+3);
feedReplicationBacklogWithObject(argv[j]);
feedReplicationBacklog(aux+len+1,2);
}
}
// 遍历slaves链表,把命令以BULK的格式,添加到输出缓冲区中
listRewind(slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
// 不写还没执行同步的slave
if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START) continue;
addReplyMultiBulkLen(slave,argc);
for (j = 0; j < argc; j++)
addReplyBulk(slave,argv[j]);
}
}
3.2. Slave端
若对于增量同步的Slave,回调readQueryFromClient已经被添加了,只要读就绪,就可以读取Master传来的命令,并执行,从而达到同步。详见2.3.f.。
若对于全量同步的Slave,当回调readSyncBulkPayload读完并加载完Master的RDB数据后,会调用replicationCreateMasterClient,它会调用createClient函数,将readQueryFromClient读事件回调注册到事件循环中,接下来该回调就会读取和处理Master传播来的命令。
4. 心跳检测——replicationCron
主从服务器各自会发送心跳,检测对方是否存活。
这些任务在replicationCron函数中执行,每秒执行一次,它主要做的任务是:
-
作为Slave时
-
检测超时(连接Master超时、I/O超时、接收Master的
PING超时),并释放连接通过
client的lastinteraction字段判断,Master在Slave中也是一个client -
必要时连接到配置的Master
-
向Master发送ACK,并携带复制偏移(
REPLCONF ACK <offset>)这里的
offset是master->reploff,即收到Master传来且以提交到数据库的数据偏移量Master收到
REPLCONF ACK <offset>后,会更新slave->repl_ack_off(只有给的offset更大的时候更新),并刷新slave->repl_ack_time以避免超时该命令不会返回任何值
-
-
作为Master/作为Slave且自己有Slave时
-
向下属Slave发送
PING(将PING命令拷贝到Slave的响应缓冲和backlog里,即调用replicationFeedSlaves) -
当下属Slave正在数据同步之中,且自己的RDB后台任务没有执行/正在执行,且RDB存入磁盘,则还得向Slave发送一个空行,同样作为PING,防止Slave认为自己和Master连接超时
Slave收到
PING或者空行后,会刷新lastinteraction,从而避免出现超时 -
断开超时的Slave
通过
client的repl_ack_time字段判断,Slave在Master中也是一个client -
若当前没有Slave,根据
repl-backlog-ttl,释放backlog的内存 -
若当前没有Slave,且AOF关闭,释放复制脚本缓存
-
若当前Slave需要RDB文件,且目前没有创建RDB文件,则启动RDB后台任务
-
标黑的部分,就是和心跳相关——Master发PING和空行,Slave发REPLCONF ACK <offset>。
5. 总结
Redis主从复制的代码的确很复杂,下面总结一下:
-
Master和Slave跟踪
reploff偏移,通过心跳确定各自复制的进度- Master中,是
slave->repl_ack_off - Slave中,是
master->reploff
- Master中,是
-
Redis通过配置(
slaveof)或者SLAVEOF命令来配置主从节点关系,从节点的状态会被初始化为REPL_STATE_CONNECT,在事件循环(replicationCron)中和主节点连接,注册回调,利用回调函数执行后续的数据同步和命令传播流程 - 主从复制的流程如下:
- 首先数据同步(
PSYNC runid offset/SYNC) - 然后命令传播
- 首先数据同步(
-
数据同步分为:
-
全量复制(无效
PSYNC/SYNC):- Master创建RDB后台任务,完成后通过
serverCron注册回调,把RDB文件传给Slave - Slave收到
+FULLRESYNC响应,注册回调,通过回调读取RDB文件,将其加载 - Slave加载完后,创建Master客户端,注册
readQueryFromClient读回调,准备接收命令传播
- Master创建RDB后台任务,完成后通过
-
增量复制(有效
PSYNC)-
Master会保留最近的复制记录于
backlog(默认1MB),当Slave意外掉线重连时,恢复从这里拿数据,并根据给定的offset,把这里的数据写给Slave因此断线不能太长,否则
backlog数据覆盖,只能全量同步 -
Slave收到
+CONTINUE后,注册readQueryFromClient回调,接收并执行backlog命令,并准备接收命令传播
-
-
-
命令传播:
- Master执行完命令后:
- 首先添加到
backlog,它是环形缓冲,旧数据会被丢弃 - 然后把命令写到Slave的响应缓冲区,等待事件循环的写出
- 首先添加到
- Slave通过
readQueryFromClient回调接收传播的命令,并执行
- Master执行完命令后:
-
心跳检测:主从都会彼此心跳
- 主:向Slave发送
PING,且当Slave正在等待RDB传输时PING一个空行。 - 从:向Master发送
REPLCONF ACK <offset>心跳,并告知复制偏移量,该命令可方便管理员查看复制的进度。
- 主:向Slave发送
6. 附录
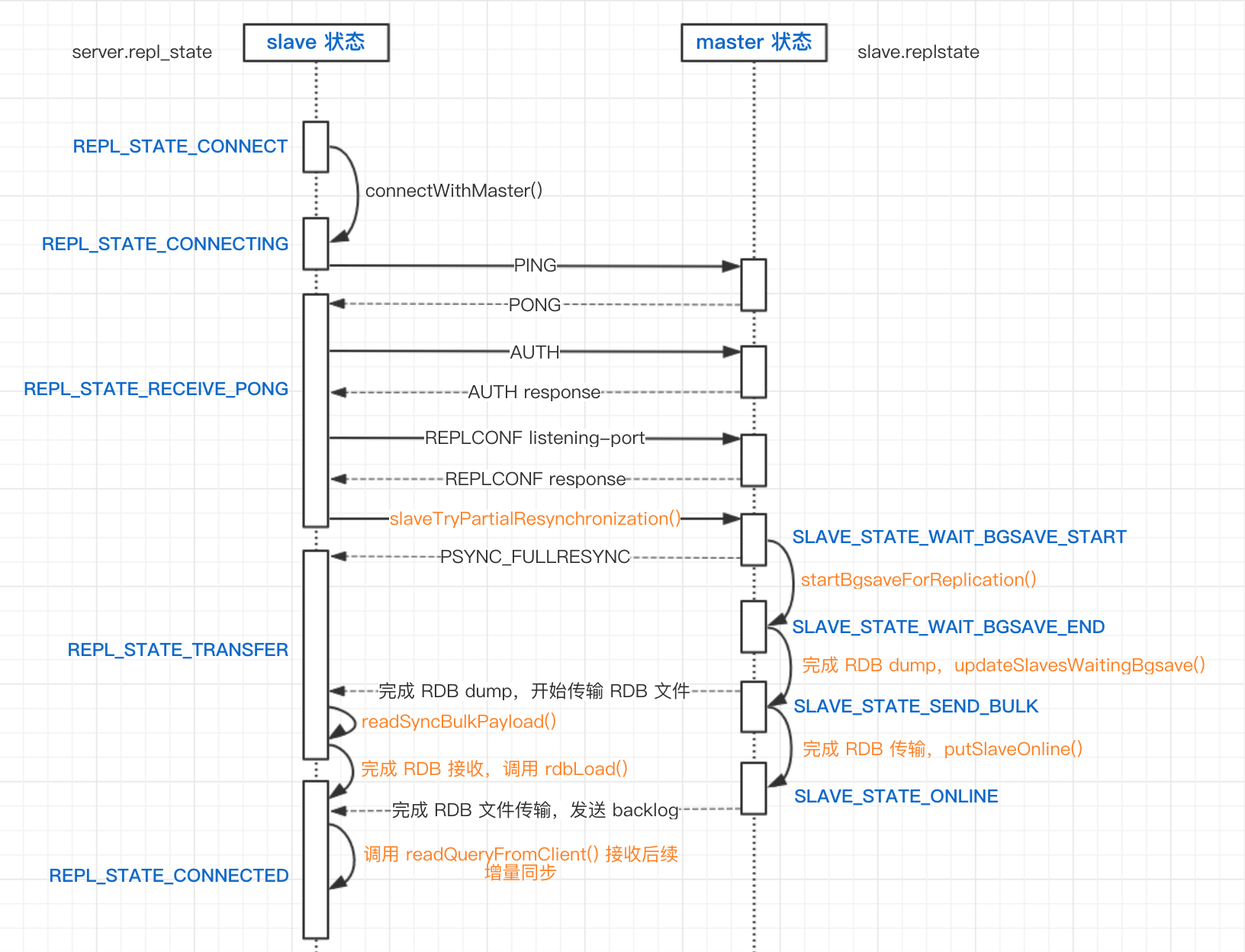
盗一张图,说明+FULLRESYNC下的时序图,来源:
- 作者: wettper
- 链接: http://www.web-lovers.com/redis-source-replication.html
此外,这里有更加详细的关于Redis复制的内容:https://521-wf.com/archives/414.html。
