1. 概述
本文介绍的是给链式数据结构指针的压缩技术。
其主要方法就是“macroscopic”,我个人认为指针只作用于某个数据结构实例,该实例放置在一个有上限的容器中,容器只会到一定的大小,所以可以用小指针代替。此外,本文也介绍了一个方法,以应对数据结构大小超过上限时的情形。
而上面的方法有2个基础:
- 指针分析/数据结构分析
- 自动池化分配
2. 背景信息
自动池化分配是为了给编译器提供信息,以实施指针压缩。而这些需要依赖一个属性——DS Graph,即数据结构的指针图表示,它通过数据结构分析(DSA)计算而来。
下面给了一个单向链表的DS Graph的例子:
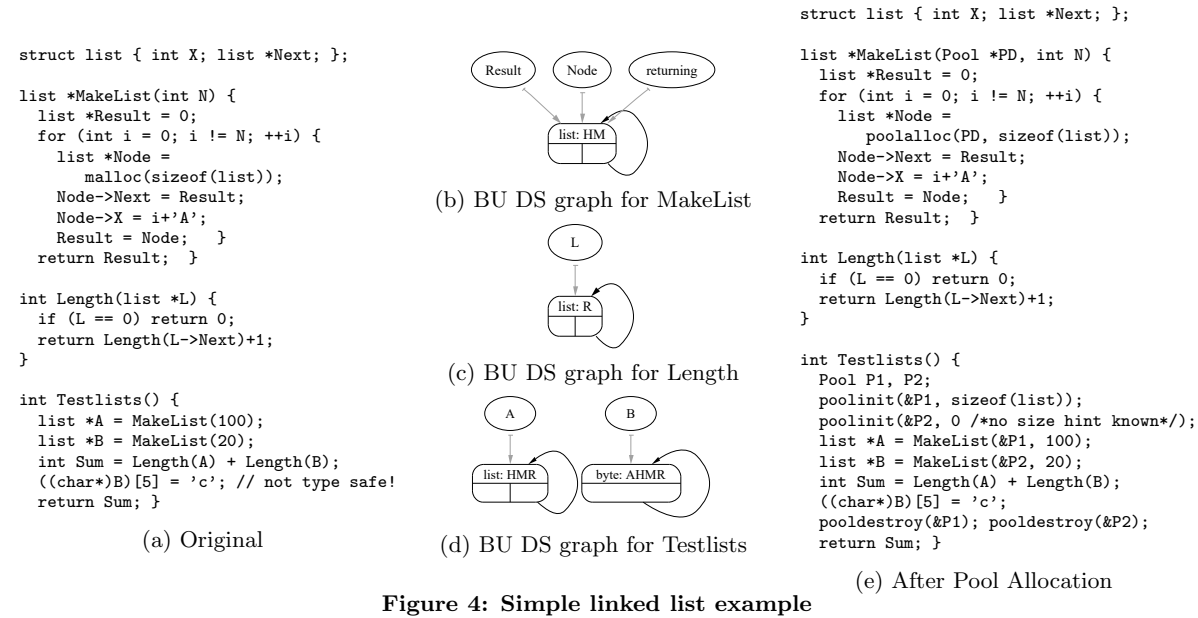
A代表数组,H代表堆,M,R可忽略
2.1. DS Graph
DS Graph是一个有向图,它提供了编译时的内存对象及其联系表示,其顶点表示不同的内存对象集合。当前认为DS Graph有下面4个属性信息:
- 类型信息:节点$n$会绑定一个类型,记为$n.\tau$,当类型未知时有$n.\tau = \bot$
- 当类型已知,这个节点就是type-homogeneous节点(TH node)
- 当类型未知,这个节点就被视作未知长度的字节数组,即被视为
byte+A
- 内存类型:根据存储未知分为堆($\bold{H}$)、栈($\bold{S}$)、全局($\bold{G}$)、未知($\bold{U}$)。每个节点的内存类型$M \subseteq {\bold{H}, \bold{S}, \bold{G}, \bold{U} }$
- 若$\bold{U} \in M$,$n.\tau = \bot$
- 函数被视作全局的
- 字段感知的指针指向信息:这里就是DS Graph的边,包含${s, f_{s}, t, f_{t} }$,第一个和第三个代表节点,第二个和第四个代表节点的类型信息
- 每个指针的指向目标:指针都会有一条出边,指向一个节点
计算DS Graph需要完全的上下文感知,来分析指向路径,本文是DSA。
2.2. 自动池化分配
这个方法将分配和释放内存在一个/一组内存池分配。
在本文中,它会给每个$\bold{H}$节点分配一个内存池,而每个内存池有一个描述符,根据描述符和偏移量,就可以定位字段位置。
池化分配的方案替换的代码可看第2节右侧代码。
总结一下,基于DSA的自动池化分配,提供了下面的信息:
- 自动池化分配将不同对象分配到不同的内存池
- 指针和内存池描述符的映射关系不需要动态存储(因为DS Graph的第四条性质)
- 若顶点的类型信息已知,那么它的大小在编译期就知道,这些对象在内存池中可以对齐存放
3. 静态指针压缩
它分为2步:
-
将指针描述成内存池的偏移量—— index conversion
-
利用32位整数存储(而非64位整数)—— index compression
静态指针压缩下,当内存池大小超过$2^{k}$时,会失败。后面的动态指针压缩算法会解决这个问题。
静态指针压缩会在编译期通过指令替换完成。
上面的例子,静态指针压缩转换后的代码如下:

3.1. 静态指针压缩API
和内存池分配的API类似,不过它保证内存池分配是连续的,并保留第一个节点是空指针。

3.2. 静态指针压缩的安全条件
Index conversion和Index compression的共同条件是:指向内存池的指针不会逃逸到外部(即不可访问内存池的地方)。这个条件已被编译器所保证。
Index conversion: DS Graph节点对应的内存池只能存储堆上数据,其它数据的指针是不能转换的;
Index compression: 编译器可以安全地改变封闭对象的内存布局(这对TH节点是可行的,因为类型和大小已知,因此可以重新布局它的内存布局,当然TH性质是充分的不是必要的),注意它可以用于堆、栈和全局的数据
3.3. 过程内部的指针压缩
给定一个DS Graph和自动池化分配的结果,过程内的指针压缩非常直接:
- 编译所有函数,获取每个函数的内存池
- 遍历对应函数中每个内存池,判断其是否可以进行指针转换,将可转换的内存池记录下来
- 根据函数和可转换的内存池,改写函数代码
算法如下所示:

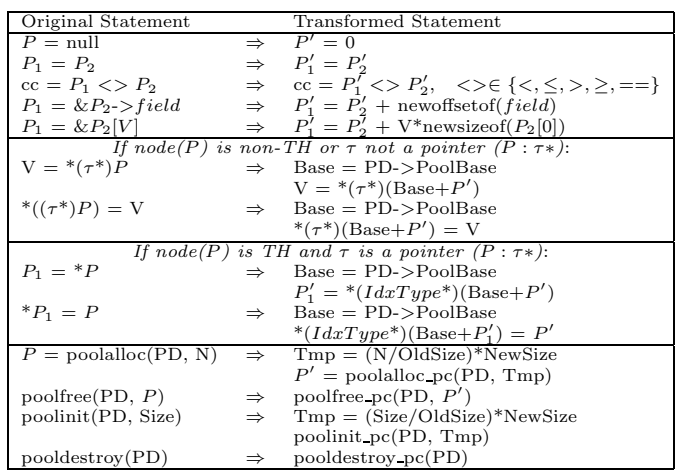
改写代码如下,这里$P$是原始指针,$P^{‘}$是压缩后的指针,$V$是任意未压缩的值:
3.4. 过程间的指针压缩
这部分在3.3.中,需要加入参数和返回值的支持,这部分需要更改3个地方。
-
分配内存时,必须指定内存池的描述符
-
关于指针的参数和返回值,需要替换成内存池的偏移量(即索引)

-
原始函数中,上下文里传入的指针可能是压缩的,也可能是未压缩的(例如上面
TestList函数中A,B两个指针是不一样的),有2个方法解决:- 生成条件语句判断
- 函数克隆(主要使用这个,因为执行更加有效)
3.5. 最小化静态指针压缩时的内存池大小冲突
静态指针压缩时,当内存池大小超过$2^{k}$时,程序就会失败。
不过静态指针压缩也是可用的:
- 每个内存池只能保存一类数据结构,或者该类数据结构的子集
- 对于TH节点,可使用实例个数作为索引,而不是字节,因为TH节点数据结构的大小编译时确定
- 编译器可以使用性能分析,识别可能异常大的内存池,关闭这些内存池的指针压缩
- 程序员可以自己指定哪些内存池不使用指针压缩
4. 动态指针压缩
动态指针压缩用于解决内存池大小超过$2^{k}$字节/对象的问题,通过运行时扩展压缩指针实现。
有很多方法实现动态指针压缩,为了简便和优化,引入3个限制:
- 只允许2类指针大小:32位(初始压缩)、64位(原始)
- 当且只当内存池是可压缩且节点是TH时,才会进行动态扩展
- 若一个对象有压缩指针,那么这些指针都是压缩的,要么都是未压缩的
4.1. 过程中的动态指针压缩
过程中的动态指针压缩和过程中的静态指针压缩大部分是一样的。
不过由于指针大小扩展,所以这里给每个内存池引入一个新变量isComp,当其为true时指针是压缩的,当为false时指针是未压缩的。
下面是使用动态指针压缩读取数据的转换后的代码,和静态指针压缩不同的是:
- 压缩和未压缩的情形都要考虑
- 使用对象索引而非字节索引

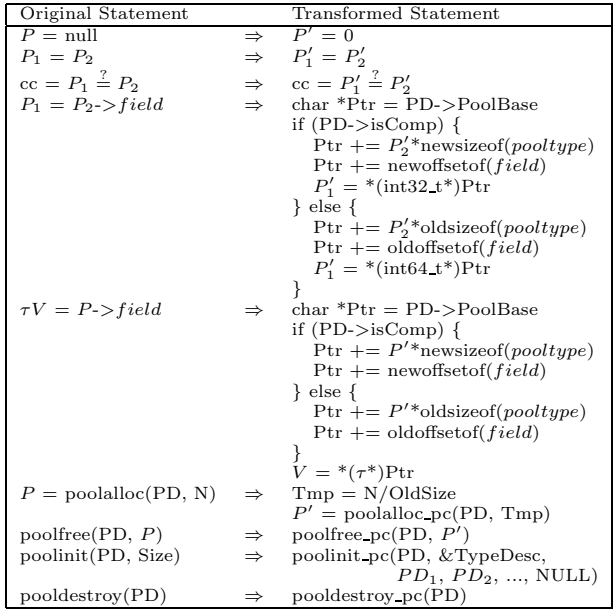
改写规则如下,实际上还是维护了2个大小——压缩的和未压缩的,并且处理压缩/未压缩分支:
4.2. 动态指针压缩API
动态指针压缩API和静态指针压缩有很大的不同,它需要运行时找到并扩展某个内存池中被引用的指针。
首先,poolinit函数接受的是对象的类型信息,而不是对象类型的大小。此外,对象若被其它内存池引用,这些内存池的描述符也得加入到初始化参数里。
当某个内存池存储超过$2^{k}$个对象,那么指向该内存池的指针都必须解压缩,这时候,只要遍历pollinit传入的内存池描述符即可实现。
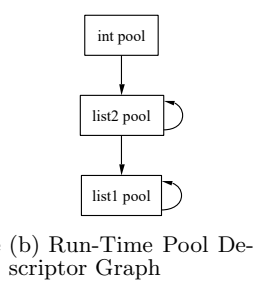
例如上图,list1引用了list2,list2池被list1池引用,所以初始化时,p2 = poolinit(&p2, type_list), p1 = poolinit(&p1, type_list, p2)。当list2超过一定大小需要解压缩时,list1也会被解压缩,而解压缩就是“扩展0”操作。
4.3. 过程间动态指针压缩
首先要解决上下文中压缩和未压缩指针共同存在的问题,由于这里使用了条件语句,那么函数克隆就没必要了。
然后,内存池需要保证是TH pool,不允许有字段地址的访问。这可通过DSA和DS Graph检查。
此外,对于非压缩的内存池,初始化时类型参时设为NULL,该内存池分配内存的指针就是非压缩的,其isComp一直是false。

其它的改写规则,可参照3.4.节,基本一样。
5. 优化
3, 4步能生成正确,但是较慢的代码,下面三个优化可以让代码更加有效,前两个可用于静态和动态指针压缩,最后一个可用于任何分支判断的场景。
5.1. 地址空间预留
当内存池扩大时,若上层使用的是malloc,为了保证内存的连续,扩容时需要拷贝,开销很大。
一种可行的实现方式就是开辟/预留一个静态大小的空间,这个大小比较大,不太可能被突破。这样扩容的时候不需要进行数据拷贝/数据移动。
这个方案也保证了PoolBase不会改变,也利于下面5.2.的优化。
5.2. 减少重复的PoolBase的读取
由于动态指针压缩需要读取PoolBase和isComp,尽管这2个字段不太可能发生cache miss,但是在大量指针读取的时候,会明显影响性能。
不过通常编译器会消除一些重复的读取。
而PoolBase字段,只可能在分配内存的时候会被改变(比如要扩容),而借助5.1.的优化,PoolBase不会改变,那么可以将其预先加载到寄存器中,或者放到函数的开头(这样就会被预先分配到一个寄存器),以降低多次读取PoolBase带来的开销。
5.3. 减少运行时isComp的比较
这里大量使用了isComp分支,可以用一些编译优化方法进行优化,如:
- 循环判断外提
- 条件分支合并
- 将使用非压缩指针的代码放到code section,将压缩指针的代码放到hot section(类似GCC的
__builtin_expect()宏) - 分支预测
6. 其它资料
PPT: https://llvm.org/pubs/2005-06-12-MSP-PointerCompSlides.pdf
