1. 概述
本文是阿里Tair团队在FAST 20上的论文。
这里主要讲的是HotRing,用于解决内存K-V存储内部的热点问题,它是一个热点可感知的KV数据结构,具有以下特性:
- 基于有序散列环,让热点数据更靠近头指针,以提供强局部性
- 提供轻量、运行时的检测热点转移策略
- 操作并发且无锁
2. 背景
本节说明已有的散列数据结构的热点问题,并说明解决热点问题的挑战和设计准则。
2.1. 已有散列数据结构的热点问题
内存KV存储数据结构中,散列表是最常用的。散列表基本都是以分离链表的形式实现。
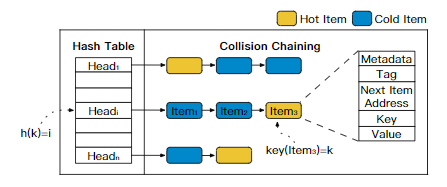
但这类数据结构难以处理热点问题,如上图,热点数据在链表尾部,访问时需要更多的内存读取,开销很大。
tag是散列值中未使用的一段
已有的解决方法有:
- 利用CPU cache,但是cache容量太小
- rehash,但会成倍增加内存使用
2.2. 挑战和设计原则
数据结构需要对热点感知,以降低内存读取的次数。
此外,还需要:
- 感知热点的转移
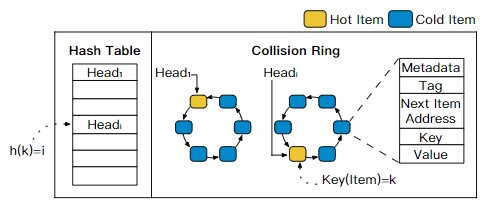
- 用于解决冲突的链表被替换成环,即HotRing
- 访问时,头指针会移动到最近访问项/热点项(热点访问时可显著降低内存读取次数)
- 有轻量的策略在运行时检测热点的转移(本文有2个)
- 支持并发
- 无锁化处理:基于CAS,以及read-copy-update (RCU), Hazard Pointers等
- 支持其它的并发操作:如热点转移检测、头指针移动、rehash等
3. HotRing的设计
3.1. 有序环
本文中,冲突链表被有序环代替:
- 原有链表的尾部会指向原有的头部
- 环的头指针可以改变
- 环的项是有序排列的
对于第3点,这是为了搜索时可终止。
这里定义顺序$order_{k} = (tag_{k}, key_{k})$,比较时按照$order$的排序(默认是字典序),那么查找终止的条件是:
- 命中:$order_{i} = order_{k}$
- 未命中:满足下面三个条件之一
- $order_{i-1} \lt order_{k} \lt order_{i}$(将环展成链表,待搜索项$order$在链表内)
- $order_{k} \lt order_{i} \lt order_{i-1}$(将环展成链表,待搜索项$order$在链表头之前)
- $order_{i} \lt order_{i-1} \lt order_{k}$(将环展成链表,待搜索项$order$在链表尾之后)
下图是一个例子:
3.2. 热点转移识别
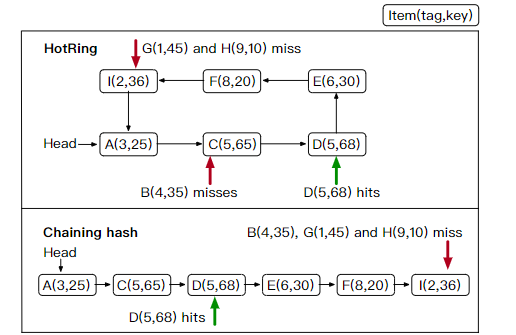
对于热点数据,可以将头节点移到热点项,以降低热点数据访问的性能开销。而问题是如何检测热点项。
即头指针是hot item, 其它都是cold item,它们的访问分别是hot access和cold access。
这里有2个方案:
- 随机移动
- 统计采样
a) 随机移动
头指针周期移动,指向一个的热点项,这个决定不依赖任何历史元数据。
实现:
- 每个线程维护一个变量,记录执行了多少次请求
- 每隔$R$个请求,线程决定是否要移动头指针
- 若第$R$个请求是hot access,头指针不移动
- 否则,头指针移动到第$R$个请求所在的项上
说明:
- 若$R$小,找到热点的时间会很短,但是可能造成频繁的头指针移动
- 若负载偏移小,该策略会比较低效
- 难以处理环中多个热点数据
b) 统计采样
索引格式
头指针head包括:
active:1 bit,作为控制统计采样的标识total_counter:15 bits,当前环总共的访问次数address:48 bits,环的头地址(x86-64上目前只使用了48位)
而环上每一项的next包括:
rehash:1 bit,作为控制rehash的标识occupied:1 bit,用于并发控制,保证并发访问的正确性counter:14 bits,该项的访问次数address:48 bits,下一项的地址
可见,利用x86-64架构和系统特性,节省处理的16位用于统计采样。
统计采样
统计采样也是需要开销的,为了降低开销,且保证识别的准确性,和随机移动一样,周期性地调整:
- 每个线程维护一个变量,记录执行了多少次请求
- 每隔$R$个请求,线程决定是否要移动头指针
- 若第$R$个请求是hot access,头指针不移动,且不开启采样
- 否则,则需要移动头指针,开启统计采样,采样个数也是$R$
- 打开
head.active(CAS) - 后续的请求会被记录到
head.total_count和对应的next.count(CAS)
- 打开
热点调整
基于上一步的统计采样,就可以决定哪一个是头节点,步骤如下:
- 关闭
head.active(CAS) - 遍历环,计算每一项的访问频率$n_{k}/N$
- 计算每个节点的收益$W_{t} = \sum_{i=1}^{k}{\frac{n_{i}}{N}[(i-t)\%k]}$,取最小的收益$min(W_{t})$,将项$t$作为新的hot item
- 使用CAS设置新的头指针
- 重置所有的计数器
写入密集型的热点:RCU场景下
对于更新操作,HotRing可以对不超过8字节的数据进行in-place原子更新操作,这种情况下,读取和更新被视作一样的操作。
但对于大量数据的更新,则使用read-copy-update协议,并且需要修改前一项的next指针。特别的,修改一个hot item,需要遍历整个环来获取前一项——也就是说,修改一个hot item,也会让前一项hot。因此,RCU下,更新的是前一项的计数器。
由于在RCU下,更新的是前一项的计数器,头指针就会趋向于指向写入项的前一项,在写密集型的热点时,可以直接定位到热点的前一项,更新时就不需要遍历链表。
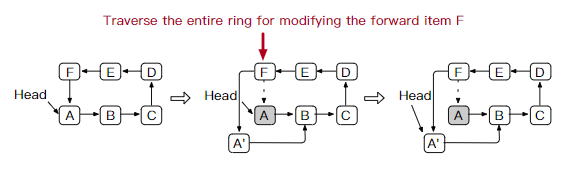
例如上图,热点是A,RCU下,修改A需要前一项F,这需要遍历整个环。
所以RCU下,更新的是F的计数器,从而让头指针指向F(写入热点依旧是A),之后写入A时,不需要遍历环了。
c) 热点继承
当对头节点执行更新或删除时,头节点需要指向其它项。但是不能随便指向其它项,因为很可能新的一项是cold item,然后频繁触发热点识别,降低性能。
解决方式如下:
- 若环只有一项,直接CAS更新头指针即可
- 若环有多个项,利用已有的热点信息(即头指针的位置)处理:
- RCU更新:指向新版本的头(因为很可能会被再次访问,比如读取)
- 删除:指向被删除项的下一个节点
3.3. 并发操作
由于头指针的移动,并发控制会更加复杂:
- 头指针移动和其它操作并发,需要检查指针的有效性
- 更新或删除时,需要检查头指针是否指向被删除项,并正确地更改头指针
HotRing的并发控制的基础就是CAS。下面看下HotRing的各个操作的并发控制。
a) 读取
不需要任何的操作,操作完全无锁。
b) 插入
插入需要:
- 创建新项
- 连接新项的
next指针 - 修改前一项的
next指向新项(CAS)
第三步可通过CAS保证线程安全。若前一项next字段发生竞争,CAS会失败,此时操作需要重试(重试后2步)。
c) 更新
当更新的数据不超过8字节:使用in-place CAS,不需要其它操作。
当更新的数据超过8字节:使用RCU更新,这时候需要分3种情况
-
RCU-update & Insert
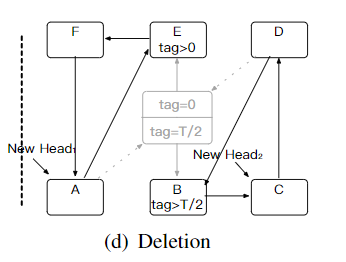
如下图,2个线程分别更新B和插入C,修改前一项的
next需要CAS,两个操作都会成功,但是结果不能成环了: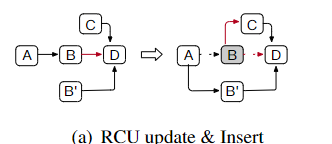
-
RCU-update & RCU-update
如下图,2个线程分别更新B和D,和第一种情况一样,CAS都会成功,但是最后结果也会导致无法成环,且B’的
next是一个野指针: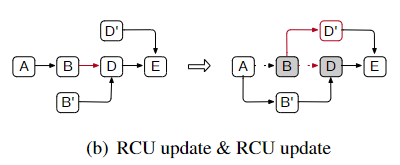
-
RCU-update & Delete
如下图,2个线程分别删除B和更新D,也有类似的问题,CAS也都会成功,但是最后结果也会导致无法成环,且A的
next是一个野指针: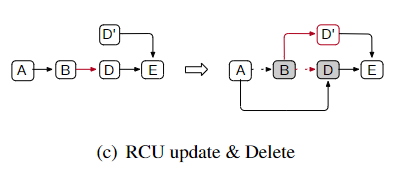
可见只有CAS设置next指针是不够的。
这时候需要额外的字段以保证正确性,这就是next指针的occupy字段,例如:
- RCU-update & Insert
- RCU-update前,尝试CAS修改
B.next值,置B.next.occupy = 1 - Insert时,使用CAS连接前一个节点,发现
B.next.occupy = 1,操作会失败,重试 - 操作完成后,新版本项的
occupy为0
- RCU-update前,尝试CAS修改
- RCU-update & Delete
- Delete前,尝试CAS修改待删除项
B.next值,置B.next.occupy = 1 - RCU-update时,使用CAS连接前一个节点,发现
B.next.occupy = 1,操作会失败,重试 - 操作完成后,新版本项的
occupy为0
- Delete前,尝试CAS修改待删除项
- RCU-update & RCU-update:个人认为和RCU-update & Delete类似
总结:
- RCU-update和删除会CAS置待更新/删除的节点
occupy从0到1 - 所有操作利用CAS连接前一个节点
- 任何的CAS失败,以及前一个节点的
next.occupy = 1,操作都会失败,需要重试
其实论文只是一笔带过了,最后还是得看无锁链表的论文(先挖一个坑)。
论文先上:
- Valois J D. Lock-free linked lists using compare-and-swap[C]//Proceedings of the fourteenth annual ACM symposium on Principles of distributed computing. 1995: 214-222.
d) 删除
RCU-update & Delete的情况上面也说了。
而Delete & Delete的情况,和RCU-update & Delete情况类似;而Delete & Insert情况,和RCU-update & Insert情况类似。
e) 头指针移动
需要解决2个问题:
- 处理正常操作和头指针移动的并发
- 处理更新/删除头节点之后的头指针移动
这里依旧使用occupy字段:
- 当要移动头指针时,CAS设置新的头节点的
occupy为1,保证其不被更新/删除 - 当头节点被更新时:
- 移动前,更新时会设置新版本的头节点
occupy为1 - 移动完成,重置
occupy为0
- 移动前,更新时会设置新版本的头节点
- 当头节点被删除时:
- 除了设置当前被删除的头节点
occupy为1,还得设置下一项的occupy为1,因为下一项是新的头节点,需要保证其不被更新/删除 - 移动完成,重置
occupy为0
- 除了设置当前被删除的头节点
3.4. 无锁rehash
HotRing支持无锁的rehash操作。而和其它使用负载因子来触发rehash不同,HotRing使用访问开销(即操作平均内存访问次数)来触发rehash。
HotRing rehash分为3步:
- 初始化
- 分割
- 删除
a) 初始化
首先创建线程,初始化一个2倍大小的散列表。易知,1个环会被拆成2个环,而散列值定位哪个环需要+1位,tag需要-1位,根据这一位的值(即rehash bit),决定原有环中的项在哪一个新环上(和JDK HashMap类似):
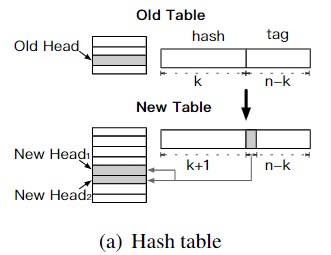
同时,该线程创建一个rehash node,里面包含2个rehash child item,作为2个新环的头(实际上是个dummy head)。它的格式和data item一样,但是tag值分别是0和T/2,代表不同的rehash bit。
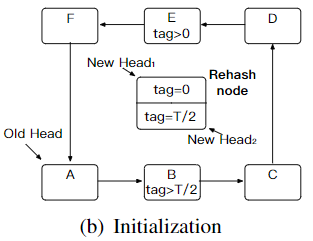
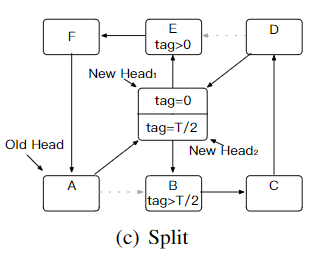
b) 分割
接下来需要分割原有的环到2个新的环。
线程遍历原有的环,根据rehash bit,将项插入到不同的新环上,插入完毕后就可用了(可访问,可写且可读)。
c) 删除
最后一步,线程将a)中创建的rehash node删除。
但在此之前,需要保证旧表上的访问要终止(类似于RCU的grace period同步原语,RCU也要挖一个坑)。所有旧表访问结束后,线程会删除旧表和rehash node。
可知,只有rehash线程会阻塞,其它线程是不会阻塞的。