1. Overview
总所周知,Redis是一个单线程的K-V缓存系统,一个线程(利用事件循环)把所有的事情都干了。虽然单线程架构可以避免代码的复杂度(如线程同步问题),但是也会影响系统的扩展性,性能因为单线程而上不去。
因此,Redis 6.0引入了多线程I/O。根据更新日志显示,其性能可以提高到原来的2倍。
为什么呢?下面就看下源码。
2. Review: 5.x版本的I/O
2.1. 读取请求
初始化服务器的时候,在多路复用器(如select, epoll, kqueue等)上,注册了读事件acceptTcpHandler。当连接到来时,调用函数链如下:
1
2
3
4
5
6
7
// 接受客户端连接请求,创建连接
acceptTcpHandler
=> acceptCommonHandler
// 创建客户端(包含输入输出缓冲区)
===> createClient
// 创建读事件readQueryFromClient, 当连接读就绪时读取客户端发送的请求
=====> aeCreateFileEvent(server.el,fd,AE_READABLE, readQueryFromClient, c)
可知读取客户端请求是通过函数readQueryFromClient进行的,它:
- 将客户端的数据读取到对应客户端的输入缓冲区中,即
client->querybuf中 - 调用
processInputBufferAndReplicate函数(内部调用processInputBuffer),从缓冲区读取内容并处理请求
这些都是由主线程做的。
2.2. 返回响应
执行命令后:
- 响应写入都会调用
addReply函数,将响应内容写入对应客户端的(小对象写入client->buf数组,大对象写入client->reply数据块链表),并且将客户端加入clients_pending_write列表中 - 事件循环中
- 在
beforeSleep中,遍历clients_pending_write列表,调用writeToClient将数据写出 - 若输出缓冲还有剩余,则注册写事件
sendReplyToClient,连接写就绪时(实际上还是调用writeToClient)将数据写出
- 在
这些也都是由主线程做的。
3. Redis 6.0: 多线程I/O
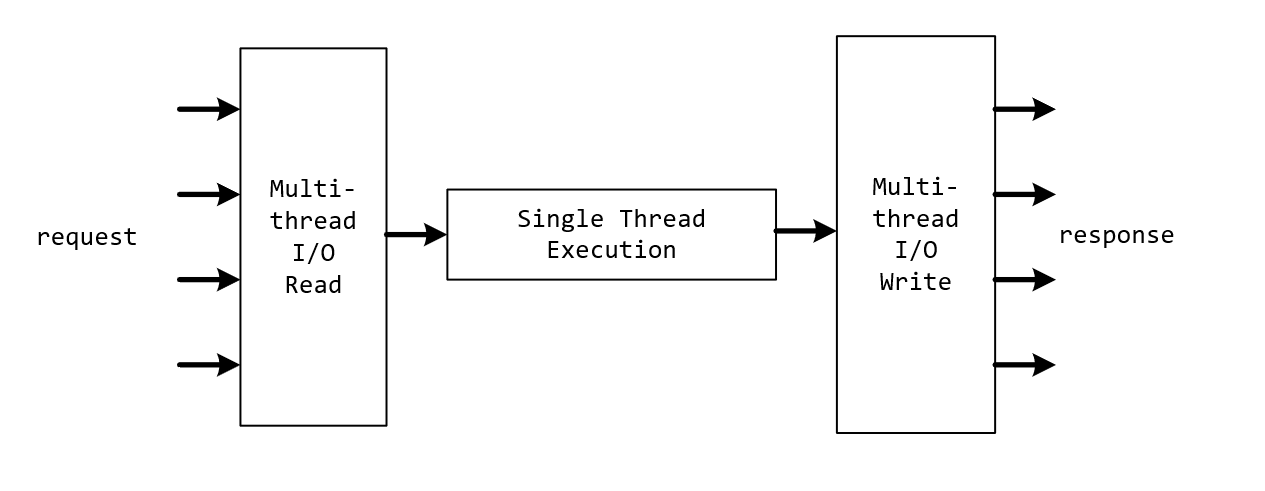
Redis 6.0引入了多线程I/O,它的总体设计思路是:
- 主线程接受客户端并创建连接,注册读事件,读事件就绪时,主线程将读事件放到一个队列中(很明显一个客户端一个事件)
- 主线程利用RR策略,将读事件分配给多个I/O线程,然后主线程开始忙等待(等待I/O线程读取完成,包括主线程)
- I/O线程读取数据到输入缓冲区,并解析命令(不执行)
- 主线程忙等待结束,单线程执行解析后的命令,将响应写入输出缓冲区
- 返回响应时,类似地,主线程利用RR策略,将写事件分配给多个I/O线程,然后主线程开始忙等待(等待I/O线程写出完成,包括主线程)
总结一句话就是:多线程读取/写入,单线程执行命令。
下面看看源码是怎么做的。
3.1. 读取请求
a) 处理回调
在创建连接和客户端,注册读事件的流程上,和之前是非常类似的。调用链如下:
// 接受客户端连接请求,创建连接
acceptTcpHandler
=> acceptCommonHandler
// 创建客户端(包含输入输出缓冲区)
===> createClient
// 创建读事件readQueryFromClient, 当连接读就绪时读取客户端发送的请求
=====> connSetReadHandler(conn, readQueryFromClient)
可知读取客户端请求是通过函数readQueryFromClient进行的,但是它加了下面的代码:
void readQueryFromClient(connection *conn) {
// ...
/* Check if we want to read from the client later when exiting from
* the event loop. This is the case if threaded I/O is enabled. */
if (postponeClientRead(c)) return;
// ... 下面的和之前版本的逻辑几乎一样
}
这里postponeClientRead函数会在多线程I/O开启时,将读事件放入队列中,等待主线程将读事件分配给I/O线程:
int postponeClientRead(client *c) {
if (io_threads_active &&
server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ)))
{
// 当多线程I/O模式开启,I/O线程活跃时(此外主线程也没有因为阻塞处理其它事情)
// 将读事件添加到clients_pending_read队列中
// 客户端也打上CLIENT_PENDING_READ标记
c->flags |= CLIENT_PENDING_READ;
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}
至此回调部分到此结束。
b) 多线程读取并执行请求
处理回调的时候,只是把读事件添加到clients_pending_read队列中而已,而并没有读取任何内容。
这部分处理对应于beforeSleep函数中调用的handleClientsWithPendingReadsUsingThreads函数,它主要做下面几件事:
- 将读事件根据RR,分配给所有的I/O线程(包括主线程自己)
- 主线程读取并解析客户端请求(和I/O线程一起,但不执行命令)
- 自旋,等待I/O线程读取完毕
- 遍历所有的事件(通过遍历
clients_pending_read上的客户端),解析和执行命令
代码如下:
_Atomic unsigned long io_threads_pending[IO_THREADS_MAX_NUM]; // 每个线程未完成的任务数
list *io_threads_list[IO_THREADS_MAX_NUM]; // 每个线程分配到的读事件列表
int io_threads_active; // I/O线程是否活跃
int io_threads_op; // I/O线程执行的操作(读/写)
int handleClientsWithPendingReadsUsingThreads(void) {
// ...
listIter li;
listNode *ln;
listRewind(server.clients_pending_read,&li);
int item_id = 0;
// 遍历读事件队列,通过RR给每个I/O线程分配读任务(包括主线程,对应0号)
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 设置I/O线程为读操作,初始化每个线程未完成的任务数,此时I/O线程就可以开始执行任务了
io_threads_op = IO_THREADS_OP_READ;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}
// 主线程自己读取和解析客户端的数据
// a) 命令不会执行, 后面会说明
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 这里对应3.1.a中postponeClientRead会返回0, 所以数据会被读取和解析
readQueryFromClient(c->conn);
}
// 清空线程0(主线程)事件队列
listEmpty(io_threads_list[0]);
// 自旋,等待I/O线程读取完毕
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
// ...
// 最后扫描所有的读事件(客户端), 取消标记, 执行并解析命令
while(listLength(server.clients_pending_read)) {
ln = listFirst(server.clients_pending_read);
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
listDelNode(server.clients_pending_read,ln);
if (c->flags & CLIENT_PENDING_COMMAND) {
// b) 若CLIENT_PENDING_COMMAND被标记,说明有命令被解析出来
// 所以要执行命令
c->flags &= ~CLIENT_PENDING_COMMAND;
if (processCommandAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid
* processing the client later. So we just go
* to the next. */
continue;
}
}
// c) 这里还是需要进行命令解析和执行
processInputBufferAndReplicate(c);
}
return processed;
}
上面有3个问题,标为了a), b)和c),这可以下面的解释解答:
-
首先I/O线程读取命令后,不会执行命令。因为客户端打上了
CLIENT_PENDING_READ标记,在processInputBuffer中会判断这个标记,从而在命令解析停止执行。这解释了a)。代码如下(见11行):
void processInputBuffer(client *c) { while(c->qb_pos < sdslen(c->querybuf)) { // ... // 若有遗留命令没执行,就会直接跳出不执行命令 if (c->flags & CLIENT_PENDING_COMMAND) break; // ...解析命令... if (c->argc == 0) { resetClient(c); } else { // I/O线程处理时,会直接跳出,不会执行命令 if (c->flags & CLIENT_PENDING_READ) { // 注意这里打上了CLIENT_PENDING_COMMAND // 因为上面 c->flags |= CLIENT_PENDING_COMMAND; break; } // 执行命令 if (processCommandAndResetClient(c) == C_ERR) { return; } } } // ... } -
容易得知,当I/O线程解析命令时,会解析第一个命令,之后的命令不会解析,因此需要:
- 先执行第一次命令,并消除
CLIENT_PENDING_COMMAND标记 - 然后再调用
processInputBufferAndReplicate把剩下的数据解析,并执行
这就是
b)和c)代码这么写的原因。 - 先执行第一次命令,并消除
3.2. I/O线程的任务
任务对应的函数就是IOThreadMain,它其实很简单:
- 轮询,判断是否有任务要做
- 根据任务类型(读/写),执行任务
void *IOThreadMain(void *myid) {
long id = (unsigned long)myid;
while(1) {
// 轮询,判断是否有任务过来
for (int j = 0; j < 1000000; j++) {
if (io_threads_pending[id] != 0) break;
}
// 遍历任务列表,根据任务类型,执行I/O任务
listIter li;
listNode *ln;
listRewind(io_threads_list[id],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
if (io_threads_op == IO_THREADS_OP_WRITE) {
writeToClient(c,0); // 写,返回响应
} else if (io_threads_op == IO_THREADS_OP_READ) {
readQueryFromClient(c->conn); // 读, 上面提过,不会执行命令
} else {
serverPanic("io_threads_op value is unknown");
}
}
// 清空任务列表,并设置未完成任务数为0
listEmpty(io_threads_list[id]);
io_threads_pending[id] = 0;
// ...
}
}
3.3. 返回响应
和Redis 5.x版本类似:
- 执行命令是单线程的
- 响应也被主线程写入了客户端的输出缓冲区
- 客户端会被添加到
clients_pending_write列表(即写事件列表)
多线程刷掉输出缓冲区,将响应返回给客户端,也是在beforeSleep中完成,对应的函数就是handleClientsWithPendingWritesUsingThreads。
它和多线程读非常类似,也是:
- 遍历
clients_pending_write列表,根据RR,分配写事件给所有的I/O线程(包括主线程自己) - 主线程写出客户端响应(和I/O线程一起)
- 自旋,等待I/O线程读取完毕
- 遍历所有的事件/客户端,若还有没写出的部分,则注册写事件
sendReplyToClient,连接写就绪时(实际上还是调用writeToClient)将数据写出
int handleClientsWithPendingWritesUsingThreads(void) {
// ...
// 遍历clients_pending_write列表(写事件列表)
// 根据RR分配写任务(包括主线程自己,即线程0)
listIter li;
listNode *ln;
listRewind(server.clients_pending_write,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 取消CLIENT_PENDING_WRITE注记,因为要写出了
c->flags &= ~CLIENT_PENDING_WRITE;
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 设置I/O线程为写操作, 初始化每个线程未完成的任务数, 此时I/O线程就可以开始执行任务了
io_threads_op = IO_THREADS_OP_WRITE;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}
// 主线程(线程0)自己将响应写出
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
writeToClient(c,0);
}
// 清空线程0(主线程)事件队列
listEmpty(io_threads_list[0]);
// 自旋, 等待其它I/O线程写出完毕
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
// 遍历所有的写事件(客户端)
// 若还有剩余的没写出,
// 则注册写事件sendReplyToClient,连接写就绪时(实际上还是调用writeToClient)将数据写出
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 若还有剩余的没写出, 注册写事件sendReplyToClient
if (clientHasPendingReplies(c) &&
connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR) {
freeClientAsync(c);
}
}
// 清空写事件列表
listEmpty(server.clients_pending_write);
return processed;
}
4. 总结
Redis 6.0实现了I/O读写的多线程,而执行命令依旧是单线程。
并行化的读取和写出提高了Redis的总体性能,但是却并没有引入复杂的线程同步问题,数据结构也不需要满足线程安全,让项目改动处于可控的范围内。
架构图如下: