1. Introduction
Spanner是一个可扩展到全球的数据库。
从最高层面的抽象,Spanner就是一个数据库,它:
- 把数据分片到多个Paxos复制状态机上,状态机遍布全球
- 客户端可自动在副本间进行失败恢复
- 会自动对数据重分片,以应对负载变化和失败恢复
Spanner有几个特性:
-
可细粒度动态控制数据副本的配置
-
提供一般分布式数据库难以实现的功能
-
读和写操作的外部一致性
-
一个时间戳下跨数据库的全球一致性读
-
而第2个特性的实现,是因为Spanner能提供全球范围内的有序事务提交时间戳,而这个功能基于TrueTime API及其实现。
下面会根据论文,说明:
- Spanner的架构设计
- TrueTime API
- 基于TrueTime API,如何实现外部一致性分布式事务、无锁只读事务和原子表结构更新
2. Spanner架构设计
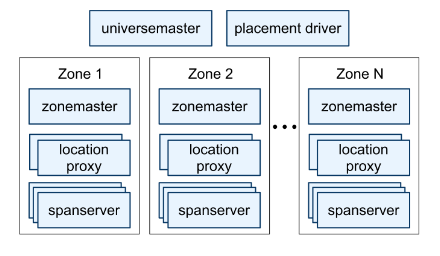
总体架构而言,一个Spanner部署被称为universe,包含:
- universe-master:管理和控制zone的状态和信息
- placement driver:周期性和span-server交互,发现需要转移的数据
- 多个zone,每个zone包含:
- zone-master:管理当前zone的span-server(如分配数据)
- span-server:存储和提供数据
- local proxy:给客户端定位提供数据的span-server
2.1. Span-server架构
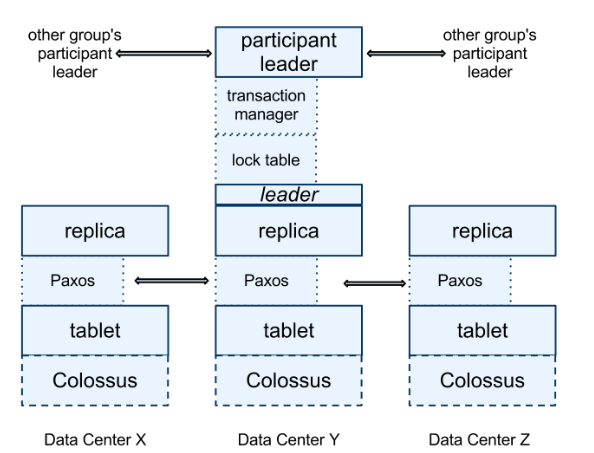
从底而上:
- 每个span-server存储多个tablet(即
(key: string, time: int64) -> string的多版本键值存储)- tablet存储于类似B+树的文件和WAL中,它们存于分布式文件系统Colossus
- 每个tablet上层实现一个Paxos状态机
- 每个tablet就是一个复制状态机的replica
- 多个replica组成一个Paxos group,其必有一个leader
- leader基于租约选定,默认10s
- 读写请求:
- 写:必须经过leader,并通过Paxos进行复制(起码半数以上)
- 读:可路由到足够新的副本上
- leader维护lock table,用于存储如2PL的锁状态
- leader拥有transaction manager,用于维护事务状态和事务并发控制
- 基于Paxos group leader,上层还有一个participant leader,用于协调跨Paxos group的事务,以完成2PC(基于transaction manager,其它replica就是participant slave)
2.2. 目录及其放置
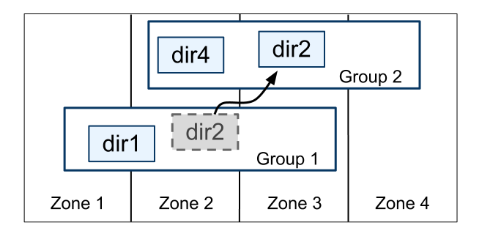
Spanner实现良一个叫做“目录”的抽象,是数据放置的最小单位:
- 1个Paxos group可拆成多个目录,每个目录由一系列共同前缀的键所对应的行组成
- 目录的复制在本Paxos group中
- 目录可以转移到不同的Paxos group,以调整负载(转移目录由Movedir后台任务执行)
- 若一个目录过大,会被分片到不同的Paxos group(而Movedir转移的也是分片而非整个目录)
2.3. 数据模型
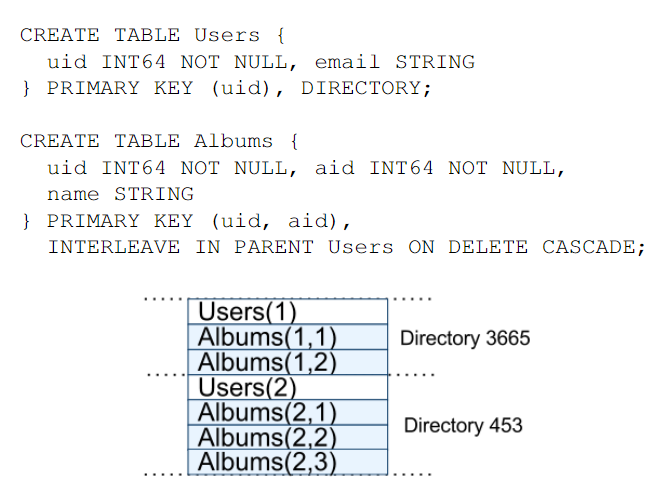
Spanner对外的数据特性是:
- “模式化的半关系式”的表
- 每个表的行都必须有名称(因此很类似于键值存储)
- 可定义外键和级联的关系
- 一个查询语言(类SQL)
- 通用的事务(基于2PC+2PL,没用MVCC)
3. TrueTime API
TrueTime是保证Spanner并发控制正确性的条件,而这些条件被用于实现很多特性,如外部一致事务、无锁只读事务、原子表结构更新等等。因此TrueTime是Spanner的基石。
TrueTime API有3个接口:
-
TT.now():返回能代表当前时间的区间TTinterval: [earlist, latest]若事件
e调用TT.now()的时间是t,调用返回的是[t_e, t_l],则t_e <= t <= t_l返回区间的原因是时钟漂移,见1.4.b节。
-
TT.after(t):返回时间t是否已经过去(t为TTstamp类型) -
TT.before(t):返回时间t是否还没到来
大致实现:
- 底层使用GPS和原子钟(不过都会产生偏差)
- 每个数据中心配有许多time master节点
- 一些配置GPS,一些配置原子钟
- 节点间互相彼此校对,若差距过大则会将自己驱逐出去
- 其它每个节点都有一个time slave daemon
- 收集time master时间参考值
- 使用类Marzullo算法进行时钟同步
4. 基于TrueTime的并发控制
基于TrueTime的并发控制,可以实现一个非常重要的特性:时间为t的读操作,只会看到t以前提交的事务。
4.1. 时间戳管理
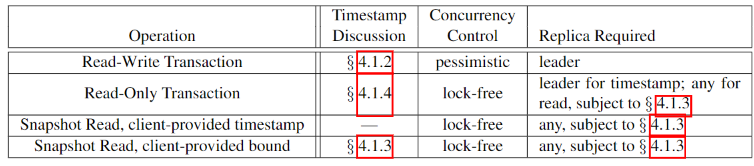
Spanner支持以下操作:
- 读写事务(包含独立写)
- 只读事务(预先声明的快照隔离事务,包含非快照独立读)
- 必须声明不含写操作
- 时间戳由leader决定,无锁,可在任何足够新的副本执行
- 需要提交
- 快照读事务
- 可读取历史数据,无锁
- 时间由客户端决定,可以是时间戳,也可以是时间范围(让Spanner自行选择时间戳)
- 需要提交
a) Paxos Leader租约
Spanner的Paxos使用了时间租约:
- potential leader会发起投票请求,接收投票
- 票拥有租期
- 若拥有一定数量的未过期的票,则成为leader;若没有足够数量的未过期票,则失去leader身份;这个时间段称为leader的租约区间
- leader完成一次写操作,会延长租约
- leader租约即将到期时,会请求延长租约
- leader可主动放弃该身份
- 前leader租约结束时间戳为$s_{max}$,对于后面的leader,它的租约起始时间戳必须大于$s_{max}$
和其它复制状态机协议一样,一个Paxos group,至多只有1个leader,即不同租约互不相交 (性质1)。
b) 给读写事务赋上时间戳
读写事务需要依赖2PL。Spanner是用在提交事务时的Paxos写操作的时间戳作为事务时间戳。
一般而言,获取所有锁后,提交前,就可以给事务赋上时间戳。
时间戳单调递增
首先,事务时间戳保证单调递增,且在不同leader上得到保证 (性质2),这是因为:
-
leader不同租约区间互不相交
- leader分配的时间戳只能在自己租约区间内
- 记leader使用过的最大时间戳为$s_{max}$,那么Paxos写操作选定时间戳$s$后,$s_{max}$也会更新到$s$(而新leader的租约区间最小值必定不小于$s_{max}$)
外部一致性
此外还要保证外部一致性,即:若事务$T_2$在事务$T_1$提交后执行,则前者事务时间戳一定比后者大 (性质3)。
说明这点首先定义一些符号:
- 事务$T_i$开始事件为$e_i^{start}$,已提交事件为$e_i^{commit}$,coordinator leader收到提交请求事件为$e_i^{server}$(因为Spanner也使用了2PC)
- Spanner给$T_{i}$赋上的时间戳为$s_{i}$
那么问题就变为了:$t_{abs}(e^{commit}{i}) < t{abs}(e^{commit}_j) \Rightarrow s_i < s_j$。
具体操作为:
- Start阶段:$e_{i}^{server}$发生时,调用
TT.now(),时间戳$s_{i}$要大于等于TT.now().latest - Commit Wait阶段:当保证
TT.after(s_i)成立后,才能触发$e_{i}^{commit}$事件
因此可以得出:

c) 在某个时间戳下的读操作
由于b)中的时间戳单调性,可以确定副本是否足够新。
每个副本会追踪一个值$t_{safe}$,表示副本最近更新的最大时间戳。当给定读时间戳为$t$,满足$t \le t_{safe}$,则副本可以读取。
而$t_{safe}$怎么来的?$t_{safe} = min(t_{safe}^{Paxos}, t_{safe}^{TM})$,这里:
-
$t_{safe}^{Paxos}$:Paxos写的最大时间
- 若一个事务只涉及一个Paxos group,就是取这个时间戳
-
$t_{safe}^{TM}$:副本对应的transaction manager维护的安全时间
-
若当前Paxos group没有已经prepare但没commit的事务(即没夹在2PC中间阶段的事务),则$t_{safe}^{TM} = +\infty$
-
否则,取事务commit时间戳的下限(后文会说明):
- 给Paxos group leader回复prepare消息给coordinator leader的事件赋上时间戳为$s^{prepare}$,那么$t_{safe}^{TM} = s^{prepare} - 1$
- 若出现多个这样夹在中间状态的事务,则取最小值即可,即$t_{safe}^{TM} = \min\limits_{i} (s_{i}^{prepare}) - 1$
易知:
- coordinator leader收到各个Paxos group leader的prepare回复,第二阶段commit的时间戳必定大于$\max \limits_g(t_{prepare}^{g})$
-
d) 为只读事务分配时间戳
只读事务分为两个阶段执行:
- 分配一个时间戳$s_{read}$
- 进行$s_{read}$的快照读,可在任何足够新的副本上读
注意$s_{read}$也会让$s_{max}$变大,以保证leader租约的不相交特性(4.1.a所述)。
在Spanner中,若$t_{safe}$不够大,可能需要阻塞,因此Spanner需要分配一个满足外部一致性的最小时间戳(后面会说明细节)。
4.2. 事务实现细节
Spanner的事务基于2PL+2PC的
a) 读写事务
执行读写事务时:
- 使用2PL获取锁,然后再访问数据(读取数据),读取时使用wound-wait机制避免死锁(wound-wait解释见此)
- 写入数据先缓存于客户端,直到提交
- 事务活跃时会发送心跳
提交读写事务,执行变种的2PC协议:
-
向所有的participant leader发送写请求(包括coordinator leader),并捎带prepare请求
-
非coordinator的participant leader
- 先获取写锁(之前读锁已经获取)
- 给回复prepare这个事件赋上时间戳$s_{i}^{prepare}$(此时更新了$t_{safe}^{TM}$),回复给corrdinator leader,并持久化这个事件(对当前Paxos group使用Paxos写,此时更新了$t_{safe}^{Paxos}$)
-
coordinator leader
-
等待其它participant leader的prepare所有回复
-
开始提交流程,给提交赋上时间戳$s$(即事务时间戳),需要满足
- $s > \max \limits_{i}(s_{i}^{prepare})$(保证了$t^{TM}_{safe}$是存在的)
- $s > TT.now().latest$(为了保证$t_{abs}(e^{server}) < s$,见4.1.b Start阶段)
然后使用Paxos写入提交事件(coordinator group提交)
-
为了保证外部一致性,等待到$TT.after(s)$成立后(见4.1.b Commit-wait阶段)
- 告知客户端,告知事务提交完成
- 告知其它participant leader(捎带时间戳),让它们也提交事务(也使用Paxos写入提交事件),并释放锁
-
b) 只读事务
只读事务的时间戳需要各个涉及到的Paxos group的协商,这需要只读事务提供一个查询scope:
- 若scope仅限于单Paxos group:
- 给该组的leader发起只读事务
- leader为只读事务分配时间戳$s_{read} = LastTS()$
- $LastTS()$即该Paxos group最后提交的写操作时间戳,因此读能看到最新的写操作结果
- 若scope跨多Paxos group,有多种选择:
- 协商所有的Paxos group,基于各组的$LastTS()$
- Spanner直接使用$s_{read} = TT.now().latest$,可能需要等待$t_{safe}$变大(见4.1.d)
c) 模式变更事务
Spanner支持原子的模式变更,但它不是标准的事务,而是一个事务的变种:
- 首先分配一个未来的时间戳,它会在prepare阶段进行注册(依旧依赖2PC)
- 读写操作隐式依赖该模式,并与注册的模式变更时间戳$t$保存同步
- 若操作时间戳小于$t$,正常执行
- 若操作时间戳大于$t$,则阻塞等到模式变更完成后,才能继续下去
d) 改进
首先是$t_{safe}^{TM}$:
- 问题:当存在一个prepared但没commit的事务,$t_{safe}$无法变大,从而阻塞$s_{read} > t_{safe}$的读,即使读操作不会造成冲突
- 解决:增加$t^{TM}_{safe}$到key range的映射(key range涉及2PC夹在中间状态的事务)于lock table,读操作只需检查lock table上这个映射信息即可
然后是$LastTS()$:
- 问题:当一个事务刚被提交,一个读请求时间戳必须跟在刚提交事务的后面,造成阻塞,即使读操作不会造成冲突
- 解决:增加key range到提交时间戳$s$的映射于lock table,读操作(若无冲突)$LastTS()$只要从lock table找对应key range的最大提交时间戳即可
接着是$t_{safe}^{Paxos}$:
- 问题:没有Paxos写时,$t_{safe}^{Paxos}$无法变大,即存在某个Paxos group上次写提交发生在$t$以前,时间$t$的快照读无法执行
- 解决:利用了leader租约的不相交性
- 每个Paxos leader维护一个阈值来增加$t_{safe}^{Paxos}$值,超过该阈值时将会发生一次写入操作:维护一个映射$MinNextTS(n)$,即”序号$n$的Paxos写$\Rightarrow$序号$n+1$的Paxos写的时间戳”的映射
- 第$n$个Paxos写提交后,$t_{safe}^{Paxos}$可增大到$MinNextTS(n) - 1$
-
关于$MinNextTS(n)$的讨论:
- 单个Paxos leader下很容易实现,因为$MinNextTS(n)$必须落在租约期内
-
若leader需要延伸$MinNextTS()$,导致其值超过租约期,则需要先延长租约
- $s_{max}$会增大到$MinNextTS()$的最大值
