1. Introduction
本文提出了一个新的复制协议NOPaxos,利用网络的有序保证,降低了Paxos共识带来的开销,使得复制带来的开销非常低(2%的降低)。
NOPaxos实现分为2层:
- 网络层:实现有序不可靠广播(OUM),保证广播传输有序,但不可靠
- 协议层:在OUM上的复制协议NOPaxos,只需要处理丢包场景,避免了大多数的协调场景
本文贡献点:
- 实现OUM,可用于数据中心内部,并提供OUM的三种方法
- 基于P4可编程交换机
- 基于Cavium Octeom网络处理器
- 纯软件实现,不需要硬件依赖(延迟稍高)
- 实现NOPaxos,可用于有序不可靠的网络,只需要处理丢包场景
2. 将乱序问题从复制状态机抽出
复制状态机协议需要解决2个问题:乱序、消息不可靠。
本文创新地将乱序问题下移到网络层解决,因此上层协议只需要处理消息可靠性问题,协议可大量简化:
- 只需要保证每条消息的传输是all-or-nothing(原子的)
- 在消息没丢失的情况下,不需要和其它副本协调
而处理乱序问题,实际上非常容易实现,且非常高效:
- 给消息赋上单调递增的序列号
- 直接拒绝旧序列号的消息
下面是各个复制状态机协议的对比:

3. Ordered Unreliable Multicast
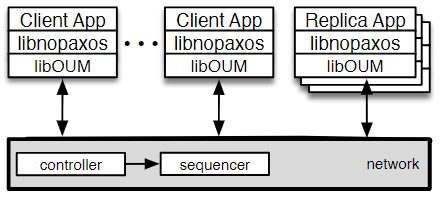
首先说明整个NOPaxos架构,其组件都在一个数据中心内部:
libOUM:OUM库,保证网络传输的有序,不需保证其可靠,节点靠其发送和接收消息libnopaxos:NOPaxos库,实现NOPaxos协议,需要依赖OUM
3.1. OUM性质
- 异步:延迟可无上限
- 不可靠:消息不保证传输到
- 有序广播:接收端收到消息的顺序和发送端一样
- 消息丢失检测:消息$m$广播到进程组$R$,只会出现2种情况
- 所有$R$的进程,在下一个广播到来前,都收到消息$m$或丢包提示
- 所有$R$的进程,都没收到消息$m$或丢包提示
3.2. OUM Session和API
OUM API可参考下图:

注意到,OUM引入了新的概念:Session(在API中用sessionNum标识)
- 从session开始到结束,保证OUM的属性
- session结束时,多进程的结束时间点是不一样的,那么结束时,消息直接丢弃,用丢包提示替代,不同进程丢弃的消息可能不同
- session是通常是长久的,很少情况下才会终止(如网络本身问题)
- 终止时,上层需要保证集群一致下,开启下一个session,这和TCP类似
4. OUM设计与实现
设计思路非常简单:所有网络包只通过唯一的序列号生成器(sequencer)。
序列号生成器是一个设备,它:
- 给网络包赋上递增序列号
- 转发网络包到目标
这样libOUM就可以探测到消息顺序,对于乱序的包,直接丢弃并返回丢包通知。
这里会涉及3个挑战:
- 网络必须将消息通向唯一的序列号生成器,即network serialization
- 实现一个高吞吐低延迟的序列号生成器,有3种实现
- 容错
4.1. Network Serialization
这里使用了软件定义网络(SDN),可以让我们在网络层的控制器上自定义转发、过滤和重写规则。
有了SDN,实现就比较好实现:
- 对于每个OUM组
- 分配一个组地址
- 拥有对应的一个序列号生成器,每个OUM组一般序列号生成器不一样
- SDN控制器设置转发规则,将包转发到序列号生成器,然后转发到OUM组
- 序列号生成器可嵌入到交换机中,该交换机即根交换机(或根交换机组的一个)
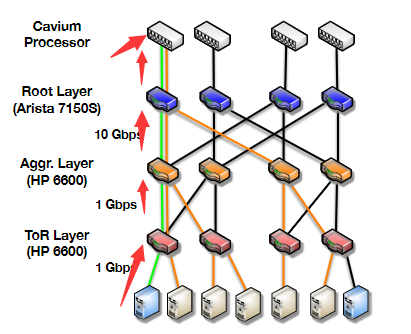
尽管路径变长,但是实测性能并没有太大损失(88%场景没有延迟的提升)。
4.2. 序列号生成器
它的工作很简单,但很重要:给消息赋上一个单调递增的序列号。
本文提供3个实现:可编程交换机、网络处理器、软件实现
a) 可编程交换机
最有效的方式是使用交换机来进行序列号生成。
其编程语言如P4,刷入交换机后,可用于每个包粒度的控制。
不过在论文发布的时候,这样的商用产品并不可用。
b) 网络处理器
这是本文的采用的实现方式:使用了OpenFlow交换机+网络处理器。
具体的:
- 以MiddleBox形式实现序列生成器
- 将MiddleBox嵌入到交换机上,修改OpenFlow规则,将消息发送到MiddleBox进行编号
相比第一种方式,延迟相对高一些(99%下不超过16微秒)。
c) 软件实现
这种方式最简单,但延迟最大。
具体的:
- 将消息转发到一个终端节点/集群(如Linux服务器)
- 终端节点/集群对消息进行编号
d) 序列号生成器的扩展性
由于一个OUM组的流量只走一个序列号生成器,它很容易造成瓶颈,因此它的扩展性很重要:
- 对于a)和b)的实现,不会有瓶颈,它基于硬件实现,速度很快
- 对于c)实现,若使用RDMA,也很快,可处理一个OUM组的能力,若有多个组,使用不同的序列号生成器即可
4.3. 容错
根交换机容错:
- 一般很少出错,而且出错后,网络层能很快的重新路由
序列号生成器容错:
- 网络控制器会监控序列号生成器的状态
- 若出错,则创建新的session,session号单调递增
- 比较的时候,比较
<sessionNum, seqNum> - 若出现
sessionNum增加,旧session就会停止,对应的消息会丢失,但是丢失的个数不知道,所以生成提示SESSION-TERMINATED,让上层确保一致后(NOPaxos协议保证)再开启新session seqNum出现空隙,乱序消息都会被丢弃,并生成提示DROP-NOTIFICATION
- 比较的时候,比较
5. NOPaxos
OUM上即可构建复制协议NOPaxos。
5.1. 模型
- 使用crash failure模型,使用$2f+1$个副本,允许容忍$f$个错误
- 保证线性一致性
- 保证at-most-once(保存最近请求表来实现)
5.2. 协议
协议分为四种情况:
- 正常情况:正常情况下处理
REQUEST,只需要1轮 - 消息丢失:序列号出现空隙,得到
DROP-NOTIFICATION,协议协调哪些消息需要丢弃以保证一致性 - 集群视图更改:Leader挂掉或OUM session终止时,协议更改集群视图并保证副本一致
- 同步:协议Leader周期性同步所有副本的日志
而每个副本包含的字段如下:

a) 正常情况
- 客户端通过
libOUM向OUM组广播请求,格式为<REQUEST, op, request-id>(REQUEST消息类型、操作、请求标识符) - OUM组所有节点接收到请求后,将消息插入日志,并返回响应,格式为
<REPLY, view-id, log-slot-num, request-id, result>(REPLY消息类型、集群视图ID、日志插入位置、对应请求标识符、结果)- Leader:还需要执行请求,
result为非空 - 非Leader:不需要执行请求,
result为空
- Leader:还需要执行请求,
- 客户端需等待收到至少$f+1$个响应,且包含Leader的响应,若等待时间过长,则重试
b) 消息丢失
消息丢失时,节点会收到DROP-NOTIFICATION通知。而丢失可能发生在Leader和非Leader,需要区分。
非Leader:
- 向Leader索要请求的副本
Leader:它需要协调提交一个NO-OP操作,具体如下
- 插入
NO-OP到日志,并向其它节点发送<GAP-COMMIT, log-slot>(第二个为NO-OP日志位置) - 其它节点收到
GAP-COMMIT后,保证之前的操作都写入日志后,将NO-OP插入到特定位置(会覆盖REQUEST日志),并返回Leader<GAP-COMMIT-REP, log-slot> - Leader需要收到$f$个节点的响应,超时则重试发送
- Leader不响应客户端
Leader丢消息时:
-
集群将其视作一次“失败”的操作(因为覆盖了副本的日志为
NO-OP),因此不会响应客户端,客户端也会重试。 -
优化:先向其它节点获取丢失的消息,若全部没有,再执行
NO-OP操作的提交
对于所有节点而言,通过request-id和client-id,可以做到操作去重,保证at-most-once。
c) 集群视图改变
当出现下面的情况时,会改变集群视图:
- Leader挂掉
- 节点发现OUM session终止
- 收到更高
view-id的VIEW-CHANGE、VIEW-CHANGE-REQ请求
视图改变协议保证所有成功的操作都会保留,并保证副本一致。协议很像Viewstamped Replication。
节点发现需要变更视图时,协议分为下面几步:
-
节点发起视图变更
a. 节点增加
view-id(leader-num或session-num),设status = ViewChange,当变更session-num时设session-msg-num = 0b. 向其它节点发送
<VIEW-CHANGE-REQ, view-id>,向Leader发送<VIEW-CHANGE, view-id, v', session-msg-num, log>(v'是上一个Normal状态下的视图号,后面需要发送该视图下的会话消息数和日志),若节点等待响应超时,则重试c. 当
status == ViewChange时,忽略所有节点间的消息(除了START-VIEW,VIEW-CHANGE,VIEW-CHANGE-REQ消息) -
当Leader收到相同
view-id的$f+1$个VIEW-CHANGE(包括自己)时a. 从
VIEW-CHANGE消息中,将上一个Normal状态下视图的日志合并b. 从
VIEW-CHANGE消息中,更新自己的view-id,并更新session-msg-num为最大的c. 向所有节点(包括自己)发送
<START-VIEW, view-id, session-msg-num, log> -
当其它节点收到
view-id一样或更高的<START-VIEW>时a. 更新
view-id,log和session-msg-numb. 调用
libOUM的listen(session-num, session-msg-num)c. 重新写入这些日志(Leader还得执行操作来更新状态),并向客户端返回
REPLYd. 设置
status为Normal,并重新开始从libOUM接收消息
d) 同步
由于只有Leader执行请求,非Leader只是写入日志,当发生集群视图改变时,新Leader需要执行所有的日志,很耗费时间。
因此NOPaxos会定期在非Leader节点执行日志同步操作。非Leader节点可以执行日志操作到sync-point,当集群视图改变时,新Leader只需要执行sync-point之后的日志即可。
具体如下:
-
Leader广播
<SYNC-PREPARE, session-msg-num, log> -
其它节点收到
SYNC-PREPARE后a. 添加和覆盖请求中的日志,必要时用
NO-OP来替代原有的REQUEST日志b. 若请求中
session-msg-num更大,更新它,并调用listen(session-num, session-msg-num)c. 向Leader响应
<SYNC-REPLY, sync-point>,其中sync-point是请求中日志的最后一项的位置 -
Leader收到$f$个
SYNC-REPLY后,广播<SYNC-COMMIT, sync-point>,并更新自己的sync-point -
其它节点收到
SYNC-COMMIT后-
其它节点之前收到了
SYNC-PREPARE:更新sync-point,并执行日志里的请求到sync-point -
否则:向Leader请求一个
SYNC-PREPARE指令,然后按照上面的步骤执行下去
-
e) 恢复与重新配置
尽管NOPaxos使用crash failure模型,并指定了固定个数的节点,但是它也可以进行故障恢复和重配置(成员改变):
- 恢复机制:Viewstamped Replication协议一样
- 重配置:做下面的事情,协议保证所有的成员会在新配置下保证一致
- 与控制器通信,给新成员安装新的转发规则
- 与序列号生成器通信,终止原有session,创建新session
5.3. 优势
- 正常情况下,只需一轮操作即可完成,延迟低,吞吐高,且能保证线性一致性
- 基于有序网络和多数投票,应对异常时,开销少,且不需要回滚
- 正常情况下,NOPaxos只会为每个请求发送和接收固定数量的消息,当副本变多时,性能不会显著下降
5.4. 正确性
NOPaxos保证了线性一致。证明略过,详细的证明可看extended version论文的附录。
6. 总结
本文最大的创新点还是在于把有序性保证放到了网络层,从而简化了上层的协议,进而提高了性能(复杂的协议通常性能不会很好)。而有序性保证是很容易实现的,非常适合放到下层。
