1. 简介
本文主要分析分布式系统由于网络分区带来的错误,研究它们的特性,包括:事件顺序、时间特征、网络错误特征等。通过分析这些特性,本文得出这些错误大多是系统设计缺陷造成的,大多数可以通过极小的测试样例复现。
而这种测试需要大量的测试样例,因此,本文构建了NEAT测试框架,它简化了客户端之间的协调,并适用于不同网络分区的情形。
2. 背景知识
2.1. 网络分区类型
完全网络分区:将网络完全分割成2个部分。其发生原因通常是地理位置过远带来的连接丢失、核心/汇聚/ToR交换机故障。
部分网络分区:将网络分割成3个部分(G1, G2, G3),其中G1和G2不能通信,但G1和G3、G2和G3可以通信。其发生原因主要是三个数据中心出现一组断连、交换机转发规则不一致等
单向网络分区:网络通信变成了单工。其发生原因主要是交换机转发规则不一致、硬件错误。
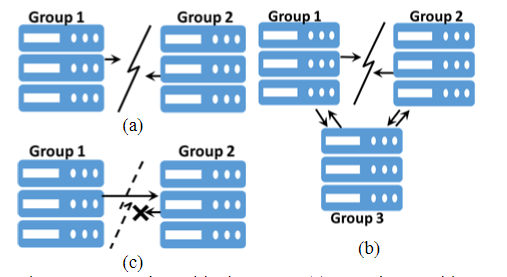
2.2. 理论上的限制
第一个限制,也是最有名的,就是CAP理论了,软件设计最多只能取2个特性(通常P必选,所以基本是C和A选一个)
第二个限制,就是系统实现的一致性协议,并没有形式化证明:
- 弱一致性协议,如Redis使用的
- 强一致性协议,虽然被证明正确,但实现时,使用了未证明的方法
2.3. 网络分区下的测试
Mock是常用的测试方式,但是它并不适合对分布式协议进行系统级别的测试。
现有其它的测试方式,最有名的是Jepsen(用Clojure写的),它能自动生成样例,并注入网络分区故障,但是它对单元测试支持不好,且不支持所有类型的网络分区。
而本文的NEAT(用Java写的),是一个系统级别的分布式协议测试框架,且支持上文3大类网络分区场景。
3. 方法论与限制
本文研究了25个分布式系统136个错误,包括10个KV分布式存储、1个协调服务、2个文件系统、1个对象存储系统、3个消息队列、1个数据处理系统、1个搜索引擎、3个资源管理器、3个分布式内存缓存。
工具使用Jepsen和NEAT,测试网络分区的场景,结果如下表:
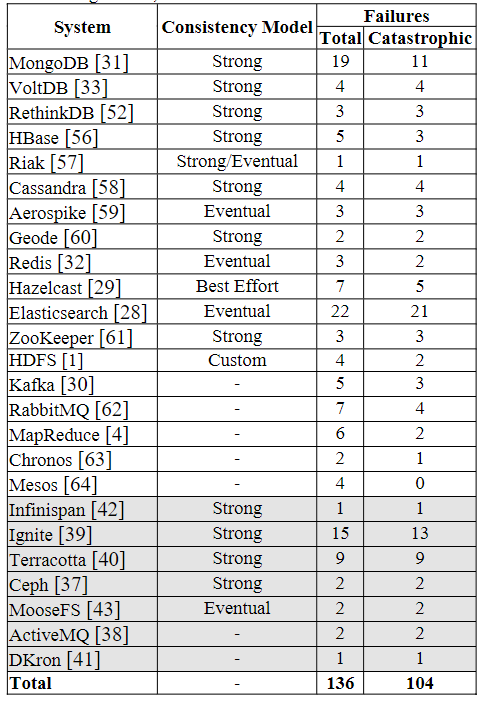
而实际测试过程中,有一些限制:
- 系统的代表性:由于分布式系统很多,因此不可能全部测完,只能测代表性的系统,如上表所示
- 采样偏差:测试的适合,只测试由于网络分区带来的错误,且忽略一些低优先级的错误,着重测试对开发者而言最重要的
- 观察者错误:为了降低观察者错误的可能性,所有的故障都会被评估和审核
4. General Findings
4.1. 故障的影响
#1:大部分故障(约80%)会带来很严重的后果,最常见的是数据丢失(约27%)
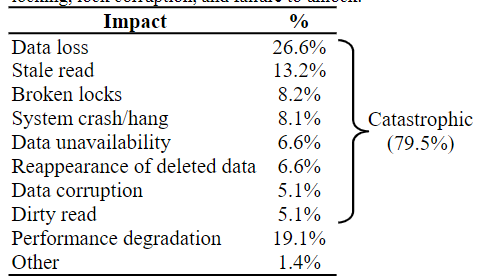
#2:大部分故障(约90%)是静默的,其余故障(约10%)会发出无法消除的警告
大部分故障都不会返回错误和警告给客户端,而剩余的警告非常难以理解,没有明确的解决机制。
#3:约21%的错误会给系统带来永久性伤害(即网络分区恢复后依旧造成伤害)
有相当一部分错误,即使网络分区恢复,系统依旧处于一个不正常的状态。
4.2. 系统机制的缺陷
#4:面对网络分区时,Leader选举、配置变更、请求路由、数据整合的机制有缺陷的最多
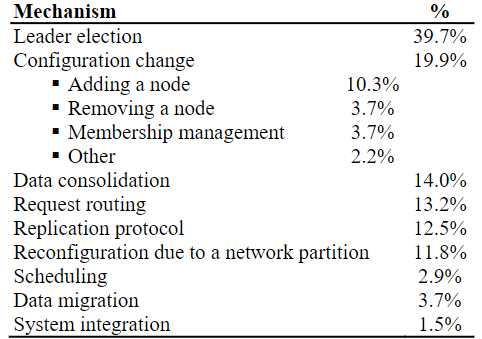
Leader选举是缺陷最多的,而Leader选举的缺陷也有分类,基本上分为4类:
-
在同一时间内,同时存在一个旧Leader和1个新Leader(57.4%)
如MongoDB, VoltDB, Raft-based RethinkDB,在网络分区时,可能出现这种情况,造成读到旧数据以及脏读。
-
选了一个错误的Leader(20.4%)
使用简单Leader选拔规则会有问题,如最长日志(VoltDB),最新时间戳(MongoDB),最小ID(ElasticSearch),可能造成数据的丢失。
-
给两个Candidate投票(18.5%)
-
和Leader选举规则冲突(3.7%)
只有MongoDB有,它有很多选举规则,且有优先级,优先级高的节点以及时间戳最高的节点会拒绝Leader的提议,让集群没有任何Leader
其次就是配置变更,即节点加入、离开和角色变化(后面会叙述)。
接下来是数据整合,由于应用了简单的规则(如根据时间戳),没有检查复制和操作状态,造成数据丢失,涉及到的有Redis, MongoDB, Aerospike, ElasticSearch, Hazelcast等。ZooKeeper也有问题,分区恢复后,不会丢磁盘数据,但可能会丢掉内存中的日志。
然后是请求路由,大部分的错误是无法返回响应(但是实际上执行了操作)。
其它错误分布如上表所示。
4.3. 网络故障分析
#5:大多数故障(64%)不需要客户端参与,或仅需要客户端和集群出现单向网络分区
这告诉系统设计者应该注意网络分区对所有操作的影响,包括客户端异步操作和内部操作
#6:大多数故障需要完全网络分区(69%),有相当一部分需要部分网络分区(29%),仅小部分是单向网络分区(2%)
此外,大部分故障发生时,只出现了1个网络分区(99%),很少出现2个或多个分区的情况
4.4. 部分网络分区的故障
本节介绍一些例子描述部分网络分区出现时,一些系统的故障。而本文提出,这些故障的原因基本都是设计缺陷。此外部分网络分区的特性和完全网络分区非常类似。
下面是一些例子:
-
MapReduce和ElasticSearch的调度:
- MapReduce:若AppMaster和resource manager分区,但和其它节点保持通信,则AppMaster会执行任务并返回客户端,而resource manager会任务AppMaster挂了而重启新的AppMaster,可能导致任务重新执行
- ElasticSearch:有相同的问题——coordinator和主节点分区,可能导致任务重新执行
-
HDFS的数据替换:
若分区发生在客户端和rack节点,NameNode可访问rack,但客户端会操作失败,并索要不同的副本,而NameNode可能会返回和之前相同的rack,造成一段时间的不可用
-
MongoDB和ElasticSearch的Leader选举:
- MongoDB:它有一个仲裁进程认定谁是Leader,假设A, B两副本,A是Leader,A, B分区,那么B发起选举,仲裁进程让它成为Leader,而A也会发起选举让自己成为Leader,如此往复会造成系统颠簸
- ElasticSearch:有类似的问题
-
RethinkDB和Hazelcast的配置变更:
- RethinkDB:其依赖Raft复制,但有改动,当节点离开时,上面的日志也会被删除,网络分区时会造成配置不一致。假设有A, B, C, D, E,分为3组(A, B), (D, E), (C),前2组分区。当设置D副本数为2,它会请求A, B, C删除日志,只有C被作用到,它会删除自己的日志(包括配置变更的日志),但A, B不知道C的配置变更了,因此C还会响应A, B的请求。这样就有旧配置组(A, B, C)和新配置组(D, E)。
- Hazelcast:也有类似的问题
5. 故障复杂性
5.1. 表现序列分析
#7:大多数由于网络分区造成的故障(83%),只需要最多额外3个的请求输入
这里的故障基本是读写操作错误。而注意到,有一部分情况下,不需要外部输入,分区发生时,也会发生故障,如Redis的SYNC操作在分区时会永久中断。
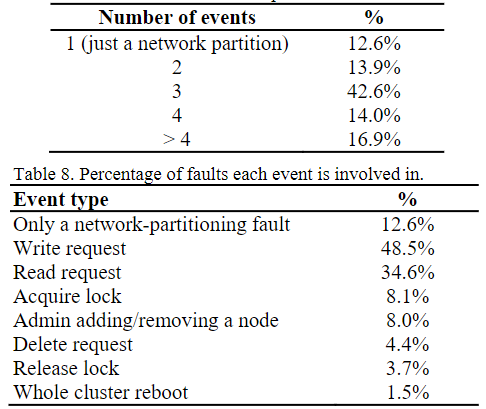
#8:网络分区后,仅当事件以特定顺序发生时,涉及到的多个故障才会出现
这里顺序有一些特性,例如大部分都是从网络分区事件开始,而仅有很小一部分与事件无关。

#9:大部分故障(88%)都可通过隔离1个节点复现,其中45%的只需隔离任意1个节点(即没有节点角色限制)
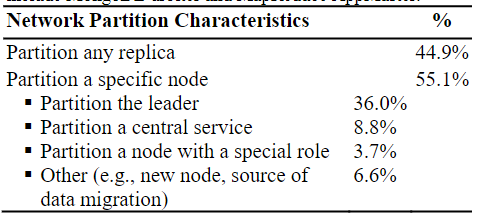
5.2. 时间限制
#10:大多数故障(80%)要么是确定性的(62%),要么有已知的时间限制(18%)
此外,这些时间限制通常是已知的(18%),常是“故障事件马上发生在网络分区之后”。例如Redis发生分区时,在旧Leader下线前,分区后,写入还是会成功。而13%的时间限制并不可知,但依旧可以测试。只有7%的故障是不确定的,因为涉及到多线程并发操作和难以预测的内部操作。
因此,测试需要重点关注时间限制,但限制常是“故障事件马上发生在网络分区之后”,因此简化了测试。
5.3. 故障解决的分析
#11:约一半(47%)的故障问题解决,需要重新设计系统的相关机制
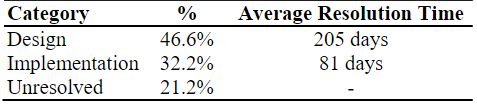
很大一部分都是因为系统设计本身的缺陷,需要很长时间来解决;而实现的漏洞相对少一些,解决也相对快一些;当然有些缺陷,开发者就放着不管了,如Redis就直接说“网络分区会造成写数据丢失”。
5.4. 提升测试的机会
#12:所有的故障都可以用5个节点复现,大部分可以用3个节点复现
因此,测试不需要测试大集群,一般单节点多虚拟机就足够了。
#13:大部分故障(93%)都可以通过故障注入框架来复现,如NEAT
6. 讨论
从观察中,还发现了一些问题:
-
设计者轻视网络分区带来的故障
例如Redis认为异步复制依旧能带来可靠性,尽管理论上会丢数据;Hazelcast锁服务依赖异步复制来提供可靠性,尽管理论上会造成double locking;早版本的Aerospike认为网络是可靠的。
此外有些设计者的假设在现实中不可行,如MapReduce, RabbitMQ, Ignite, HBase认为不可达的节点算停机,但现实中不是这样的;有如,某个节点可以访问某个服务,则所有节点也可以访问该服务,但现实中也不是这样的。
-
测试工具的缺失
网络分区难以测试,单元测试的覆盖很低,需要一个故障注入框架,但例如Jepsen,功能有一定的不足,因此需要一个好的故障注入测试框架,可以在系统级别测试网络分区的场景。
7. NEAT框架
本文实现了一个网络分区的故障注入测试框架,使用Java实现,并使用OpenFlow和iptables注入网络分区故障。
关于API和框架使用的部分,这里就不叙述了。这里稍微说明一下该工具的设计。
NEAT包括三个部分:
- 服务器节点:用于允许目标系统
- 客户端节点:用于发出请求
- 测试引擎:一个中心节点,运行测试样例
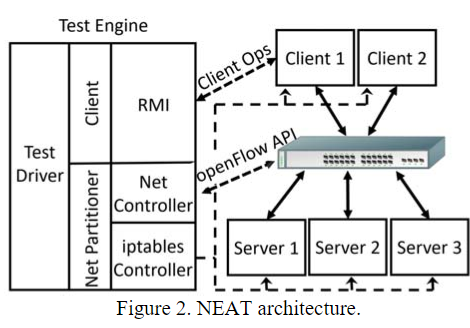
测试引擎的功能如下:
- 它可以通过Java RMI唤起客户端发起请求,可给所有的客户端的请求提供一个全局排序
- 网络分区模块使用两个模块实现:
iptables和OpenFlow API- 当有可编程交换机时,可使用OpenFlow API,否则可通过
iptables,一样能实现网络分区
- 当有可编程交换机时,可使用OpenFlow API,否则可通过
- 可以让任意节点宕掉
8. 总结
本文类似一个综述,提供了网络分区带来的分布式系统故障的一系列观察,给了我很多的设计和测试指导。
另外它开发了NEAT框架,也可以考虑用它来测试自己组开发的分布式缓存系统。
