1. 简介
本文介绍一个副本复制协议:SAUCR(情形感知的更新与故障恢复)。它是一个混合协议:
- 正常情况下:副本复制缓存在内存中
- 故障发生时:副本复制刷入磁盘
该协议性能很好,相比纯内存情形额外开销小,且保证了很强的持久性和可用性。
该协议包含下面核心部分:
- 模式切换:协议可以在内存和磁盘模式切换
- 模式感知的故障恢复:协议可根据模式,让节点从磁盘或其它节点恢复
该协议的原型已经在ZooKeeper使用,且通过严格的测试。
此外,该协议假定:
- 同时发生多个错误的可能性非常低,即错误之间基本都包含一个时间差(即文中的NSC假定)
- 只处理fail-recover错误,不处理拜占庭错误
2. 分布式更新与恢复
2.1. 磁盘模式协议
磁盘模式协议包含了更新协议和恢复协议:
- 更新协议和类Paxos复制协议类似,需要半数以上节点的持久化和响应
- 恢复协议比较简单
- 通常根据磁盘持久化的数据恢复
- 若数据存在落后的情形,恢复时,节点不会参与Leader选举,且会从Leader拉取新数据
2.2. 内存模式协议
内存模式协议也有自己的持久化等级,下面介绍几种。
a) 可遗忘的内存持久
这个实现方式很简单,只要关闭刷盘即可(例如ZooKeeper关闭forceSync)。
但是当大部分的节点宕机时,由于没刷盘,数据就会丢失,且新Leader不会感知到。
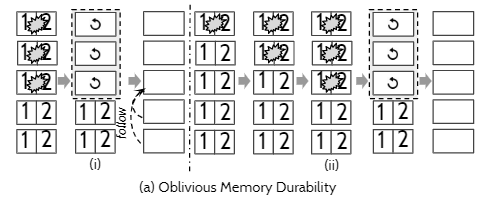
b) 数据丢失感知的内存持久
和a)一样,关闭刷盘,但是恢复时会跑一个恢复协议,感知数据的丢失。
一个协议的例子是View-stamp Replication:
- 当节点从故障恢复时,标记自己为
recovering,表示自己不能参与Leader选举(包括成为候选者和投票) - 向其它节点拉取最新的数据(其它节点不能是
recovering),并收到大多数节点的响应(必须包括Leader)
但是该协议会造成系统永远的不可用,可参考下图:
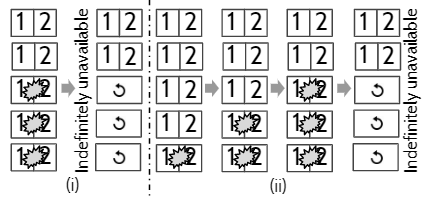
下图总结了上面3种协议的可用性和持久性特性:
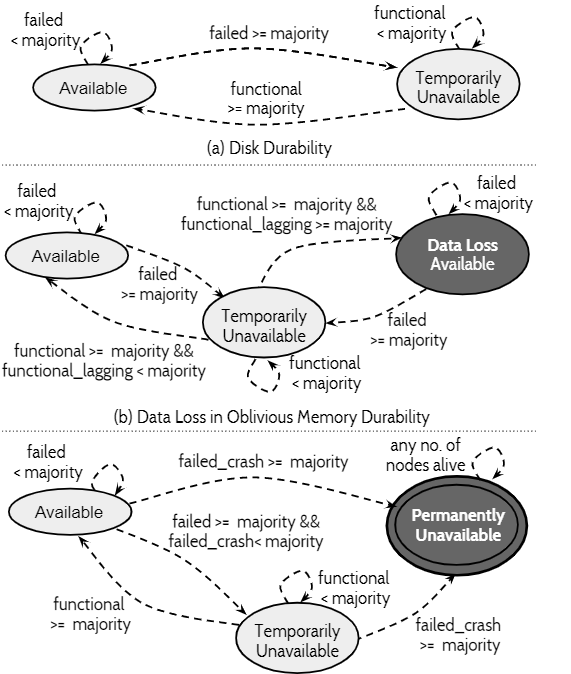
2.3. 故障与故障异步性
现实中,故障常常是相关的,即一次会出现多个相关的故障。
不过本文认为这些故障不是同时发生的,两个故障之间存在时间窗口,即NSC假定。该假定是有数据依据的——从Google集群中观察到,99.9999%的故障事件,它们的时间差超过50ms。
因此,SAUCR协议可以利用这个特性,将数据刷盘,从而提升持久性和可用性。
2.4. 原有协议的非反应性和静态性
原有的复制协议有一些不好的特性:
- 不能对故障进行响应:难以应对故障带来的各种问题。例如对于内存复制协议,当故障发生时,不能应对其带来的数据丢失、集群不可用等。
- 静态(灵活性缺失):复制和恢复的方式不灵活,不会考虑集群的状态。例如磁盘复制协议,故障不发生的情况下,还是强制刷盘,性能降低;例如内存复制协议,故障很多时,还是使用内存,造成数据丢失和不可用。
因此,SAUCR协议使用了情形感知技术,根据集群状态,采取不同的复制和恢复模式,从而兼顾高性能和持久性、可用性。
3. SAUCR
本节介绍SAUCR协议。
3.1. 协议保证
分三种故障类型分析:
- 独立故障 & 相关的非同时发生的故障:
- 能容忍任何数量的故障,保证持久性
- 只要大多数节点恢复,保证可用性
- 相关的同时发生的故障:
- 小于一半的节点故障,保证持久性;只要大多数节点恢复,保证可用性
- 大于一半的节点故障,不保证持久性和可用性
协议保证会在后面详细总结。
3.2. SAUCR模式
首先SAUCR和其它已有的复制协议有很多相同的地方:
- 基于Leader复制,需要半数以上节点同意
- Follower发现Leader挂掉,则会竞争成为Leader,选举基于半数以上的投票
- 保证Leader数据完整性,即Leader保存了集群已提交的所有信息
其次SAUCR会根据集群状态,使用不同的复制模式:
- 当超过半数以上节点存活($\ge \lceil n/2 \rceil + 1$),再宕一个节点不会丢失数据/不可用:使用内存模式(即快速模式)
- 当只有半数节点存活($\lceil n/2 \rceil$),再宕一个节点会丢失数据/不可用:使用磁盘模式(即慢速模式)
Leader是可以持续观察Follower的存活个数,来判断到底采取什么模式。
不同模式的提交条件也不同:
- 快速模式:需要$\lceil n/2 \rceil + 1$个节点缓存(包括Leader),才能提交,后台会周期性刷盘
- 慢速模式:需要$\lceil n/2 \rceil$个节点刷盘(包括Leader),才能提交
3.3. 故障响应
SAUCR是通过心跳感知节点状态,并依次判断模式的切换。而错误分为Leader和Follower,需要分开讨论。
a) Follower故障与模式切换
Follower故障后,Leader会通过心跳感知到。
当Leader怀疑(可能节点没挂,只是抖动造成)只有一半节点存活时,就立即切换到慢速模式:
- Leader向所有节点发送一个特殊请求,节点必须持久化所有缓存的数据后才能响应
- 后续的请求都会持久化到磁盘
当Follower恢复后,Leader会发现多于一半节点存活,它先进行多次确认,确认后,再切回快速模式。
b) Leader故障与刷盘
当Leader故障后,Follower会通过心跳感知到,此时Follower:
- 把数据刷盘
- 开启选主
3.4. 安全且模式感知恢复的条件
快速模式故障时,恢复可能会丢数据,此时需要从其它节点获取丢掉的数据;慢速模式故障时,恢复不会丢数据,只需从磁盘读取即可。
因此,SAUCR需要确定节点最后一个操作是处于什么模式,并且保证其它节点有足够的信息。
下面对此进行说明。
a) 持久化模式标记
当节点以快速模式处理第一个请求时,会持久化一个(epoch, log-index)数对到fast-switch-entry 数据结构。
当节点处于慢速模式或由于故障在刷盘,对于到来的请求,会持久化最新的(epoch, log-index)数对到lastest-on-disk-entry数据结构。
判断节点最后处于什么模式,可通过下面的方式判断:
- 若
fast-switch-entry数对大于lastest-on-disk-entry,则故障前处于快速模式 - 否则处于慢速模式
b) 复制的LLE表
当节点恢复时,需要知道故障前记录了多少日志,这需要节点的LLE(最后一个日志项)。因此恢复它很重要。
当节点从慢速模式恢复:LLE直接从磁盘恢复
当节点从快速模式恢复:LLE从其它节点恢复,因此需要特殊处理
- 当Leader复制请求时,捎带
LLE表,记录了每个节点可能的最后一个日志项下标(epoch和index数对) - 这个表是这么记录的:
- 对于正常的Follower和Leader,则添加
{node: (e, i)},这里(e, i)是Leader最后一项日志下标 - 对于挂掉的Follower,则添加它上一次成功响应的日志下标
- 对于正常的Follower和Leader,则添加
3.5. 故障恢复
恢复需要分模式进行。
a) 慢速模式
这和其它复制协议一样:
- 从磁盘恢复日志和
LLE - 参与选主,这需要
LLE - 从其它节点恢复缺失的数据
b) 快速模式
快速模式的恢复也需要:从其它节点恢复LLE,从其它节点恢复数据。
恢复LLE:Max-Among-Minority
- 首先待恢复节点标记状态为
recovering,并向其它节点获取自己的LLE - 其它节点若已经恢复,则返回响应,否则忽略请求
- 待恢复节点要收到$\lceil n/2 \rceil-1$回复,并选择最大的
LLE - 最后,待恢复节点恢复
LLE及以前的数据
这个流程不会丢数据。
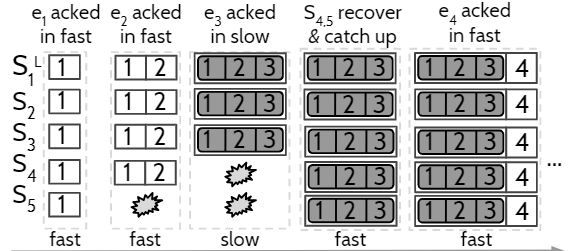
考虑下面的情况:有$S_{1}$到$S_{5}$ 5个节点,发送了2个请求,$S_{3}$挂掉,其最后LLE为$L$,而恢复后的LLE为$L’$
- 挂掉前只写了1个请求,其它写了2个请求,那么恢复时有$L’ \gt L$,明显不会丢数据
- 挂掉前写了2个请求,有2个节点由于分区只写了1个请求,恢复时,其余2个节点挂掉,那么$L’ \lt L$,但系统也可以保证不丢数据
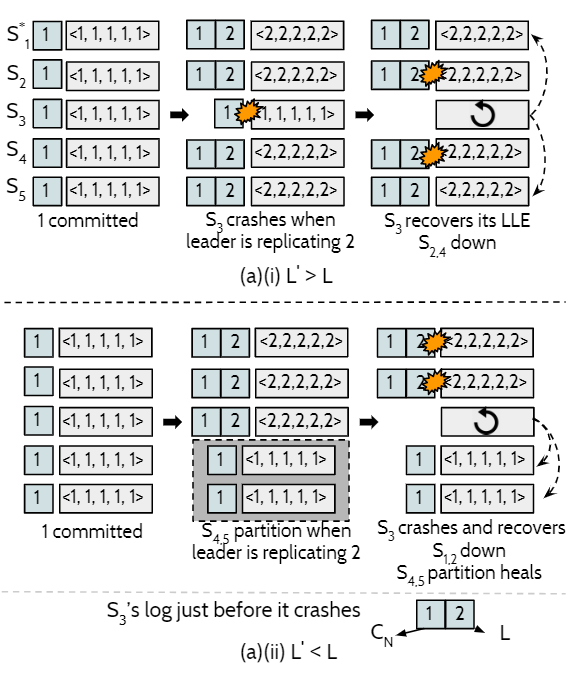
为了处理第2个情形,本文提出了$L’$下界的概念。
$L’$的下界:
另节点$N$挂掉前的日志为$D$,$C_{N}$是$D$最后一个提交的日志项。则上面第2个情形,$D$包含1和2,而$C_{N}$只包含1。可知$C_{N}$不一定是$D$的最后一项。
因此,恢复LLE时,只需要恢复到$C_{N}$。依旧是上面第2个情形,1是提交的,2没有提交,所以可忽略2的写入,节点$S_{3}$恢复到$C_{N}=1$,依旧可认为不丢失数据(因为提交的数据没丢失)。
因此认为,$C_{N}$就是$L’$的下界。
简要证明:快速模式下$L’ \ge C_{N}$:
使用归谬法。
假定$L’ \lt C_{N}$,这在$\lceil n/2 \rceil-1$个节点保存$N$的LLE小于$C_{N}$的情况下出现(记挂掉的一组节点为$G$),而这会在$G$挂掉/分区很长时间并恢复后出现(节点$N$恢复时,另外的$\lceil n/2 \rceil-1$节点挂了/分区了,记这一组为$G’$)。
然而$G$挂掉后,对于快速模式,后面的请求都不会被提交(因为需要$\lceil n/2 \rceil+1$个确认),因此$C_{N}$只可能在慢速模式提交,或者根本没提交。
而$C_{N}$是慢速模式提交的,那么和快速模式的前提冲突;只有一种可能$C_{N}$没提交,和定义$C_{N}$是提交的冲突。
所以$L’ \ge C_{N}$。
恢复LLE表
当LLE恢复后,LLE表也需要恢复:
- 若恢复后成为Leader,选举时,请求捎带
LLE表来学习,然后取LLE最大值来重建LLE表 - 若恢复后成为Follower,那么不用管,复制的时候,请求中捎带了
LLE表,自然恢复了
数据恢复
LLE恢复后,就可以恢复数据了:
- 当恢复后自己成为Follower,直接从Leader取数据即可
- 当恢复后自己成为Leader,则从返回最大
LLE的节点上取数据即可
3.6. 总结
这张图表现了SAUCR的模式转换和可用性状态转换图:
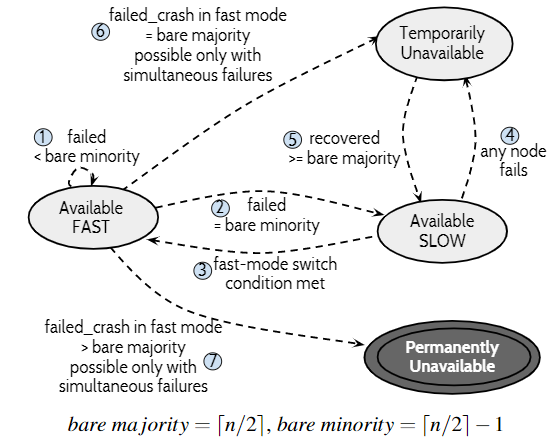
这里有几步需要说明:
- 第6步:若挂掉$\lceil n/2 \rceil$个节点,集群会暂时不可用,但是$\lceil n/2 \rceil-1$个节点数据没丢,包括已提交的数据,若再有1个节点恢复,参考3.5.b的
LLE恢复流程和$L’ \ge C_{N}$的证明,集群能够恢复可用,进入慢速模式 - 第7步:这种情况,恢复就不可能实现,因为多于$\lceil n/2 \rceil-1$个
LLE丢了,LLE无法恢复
不过对于第7种情况,本文有NSC假定,认为这种情况非常少见,因此没有考虑进去。
4. 实现
SAUCR在ZooKeeper 3.4.8中实现了一个原型。
4.1. 存储层
- 快速模式下,对于日志更新禁用
fsync,元数据的更新以及后台快照还是允许fsync fast-switch-entry会被同步持久化到磁盘- 慢速模式下,
LLE表会同步持久化到磁盘,携同latest-on-disk-entry
4.2. 复制
修改了QuorumPacket,使其捎带了模式标记和LLE表。当从慢速模式切换到快速模式,需要得到至少3次的确认。
4.3. 错误响应
节点故障通过心跳缺失、响应缺失和连接错误感知。
但是假如心跳缺失一次就切换模式,尽管会保证数据不丢失,但是会造成系统性能不稳定。
SAUCR是这么做的:
- Leader故障:
- Follower检测到与Leader心跳缺失,先刷盘,但只怀疑Leader挂掉
- 当缺失一段时间,才认为Leader挂掉,开启选主流程
- Follower故障:
- Leader检测到与Follower心跳缺失,也只怀疑Follower挂掉
- 当缺失一段时间,才认为Follower挂掉
- 当没有过半数的Follower的心跳一段时间,Leader会下线成为候选者,开启选主流程
4.4. 恢复协议
选主协议被修改,使得请求中可捎带LLE信息,利于在快速模式恢复时恢复LLE。而响应LLE请求的节点也按照上文所述的正确且并发的处理。
不过由于快速模式下有周期刷盘,因此恢复的时候,只需要恢复缺失的数据即可,数据量相对较小,因此节点响应的时候将缺失的数据批量返回给待恢复的节点。
5. 总结
本文的创新点在于:在已有的类Paxos协议的基础上,将内存持久和磁盘持久相结合,既兼顾性能,又兼顾可靠性。
这项工作个人认为非常具有挑战性,难度非常高。
