1. 概要
上一篇讲了etcd-raft的复制和心跳。本文顺着论文讲集群配置的变更。
2. 集群变更的脑裂问题
单阶段的集群配置变更是不安全的,会造成脑裂问题。
见下图:
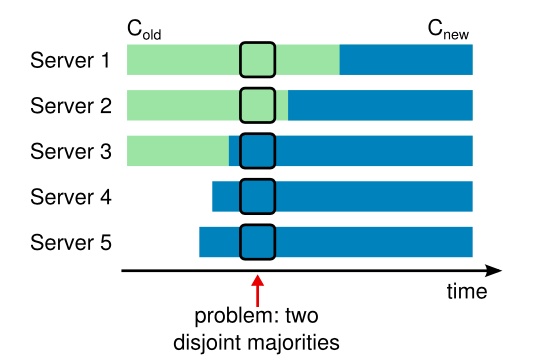
-
起始:$S_1, S_2, S_3$组成集群,配置为$C_{old} = {S_{1}, S_{2}, S_{3}}$
-
然后:集群扩容,启动$S_4, S_5$,这2台节点应用的配置为$C_{new}={S_{1}, S_{2}, S_{3}, S_{4}, S_{5}}$
-
到达图中箭头位置:$S_3$应用了新配置,但此时
- 旧配置由于故障,触发了选主
- 扩容的节点($S_4, S_5$)必定会选主(因为此时它们认为Leader不存在)
有可能出现下面的情况,即脑裂:
- $S_1, S_2$:它们认为集群有3个节点,某个节点收到2票就可超过半数,成为Leader
- $S_3, S_4, S_5$:它们认为集群有5个节点,某个节点会收到3票才超过半数,成为Leader
即上图会出现2个脑裂集合,分别为${S_1, S_2}$和${S_3, S_4, S_5}$。
在Raft论文中,它使用二阶段协议解决该问题,核心在于Joint Consensus的过渡,详细可参考这里。
3. 集群配置变更流程
etcd-raft中默认的算法并没有实现Joint Consensus,而是以日志的方式一个一个地变更配置。
3.0. 集群配置请求
etcd-raft目前有2个集群变更的数据结构,最新的使用了Joint Consensus,这里选的是旧的那个,主要包含下面信息:
- 变更消息类型
- 变更节点
- 上下文
1
2
3
4
5
6
7
8
type ConfChange struct {
Type ConfChangeType // 变更类型
NodeID uint64 // 变更节点ID
Context []byte // 上下文
ID uint64
XXX_unrecognized []byte
}
对于变更类型,包含:添加节点、删除节点、更新节点、添加Learner节点。
3.1. Leader发起集群配置变更
发起集群变更会通过Node的ProposeConfChange触发,生成MsgProp请求,请求会被路由到Leader处理(除了Candidate会拒绝请求)。
到达Leader后,请求不会受到校验,最终会进入stepLeader中,并做以下几件事:
- 解析并提取配置变更请求
- 判断是否拒绝配置变更,保证上一次的配置变更必须已经应用到状态机上,否则拒绝,设置请求为空
- 将上面的请求写入Raft日志
- 广播日志
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
func stepLeader(r *raft, m pb.Message) error {
switch m.Type {
// ...
case pb.MsgProp:
// ...
for i := range m.Entries {
// 1. 解析提取配置变更的请求
e := &m.Entries[i]
var cc pb.ConfChangeI
if e.Type == pb.EntryConfChange {
var ccc pb.ConfChange
if err := ccc.Unmarshal(e.Data); err != nil {
panic(err)
}
cc = ccc
} else if e.Type == pb.EntryConfChangeV2 {
var ccc pb.ConfChangeV2
if err := ccc.Unmarshal(e.Data); err != nil {
panic(err)
}
cc = ccc
}
// 2. 判断是否需要拒绝配置变更
if cc != nil {
alreadyPending := r.pendingConfIndex > r.raftLog.applied // 上次变更是否应用
alreadyJoint := len(r.prs.Config.Voters[1]) > 0 // 是否在Joint Consensus阶段(V2)
wantsLeaveJoint := len(cc.AsV2().Changes) == 0 // 是否需要离开Joint Consensus(V2)
var refused string
if alreadyPending {
refused = fmt.Sprintf("possible unapplied conf change at index %d (applied to %d)", r.pendingConfIndex, r.raftLog.applied)
} else if alreadyJoint && !wantsLeaveJoint {
refused = "must transition out of joint config first"
} else if !alreadyJoint && wantsLeaveJoint {
refused = "not in joint state; refusing empty conf change"
}
if refused != "" {
// 2.1. 若拒绝,设置日志项为空,表示忽略
m.Entries[i] = pb.Entry{Type: pb.EntryNormal}
} else {
// 2.2. 若接受,则标记pending,更新pendingConfIndex
r.pendingConfIndex = r.raftLog.lastIndex() + uint64(i) + 1
}
}
}
// 3. 追加日志
if !r.appendEntry(m.Entries...) {
return ErrProposalDropped
}
// 4. 广播日志
r.bcastAppend()
return nil
// ...
}
return nil
}
3.2. 其它节点处理集群变更请求
由于4.1.通过追加日志的方式发送了集群变更请求,其他节点收到后,和前文所述的追加日志逻辑一模一样,所以这部分省略说明。
3.3. Leader处理其它节点的响应
和追加日志一样,Leader需要得到半数以上同意才能提交日志,这部分不再说明。
日志提交后,Leader会轮询得到Ready并应用提交的日志,并处理并应用EntryConfChange的日志到状态机。同样,相同的日志在Follower也有一份,它也会被同样应用到Raft状态机中
这里以etcdserver为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
func (s *EtcdServer) apply(
es []raftpb.Entry,
confState *raftpb.ConfState,
) (appliedt uint64, appliedi uint64, shouldStop bool) {
for i := range es {
e := es[i]
switch e.Type {
// ...
case raftpb.EntryConfChange:
// 应用配置变更的日志
if e.Index > s.consistIndex.ConsistentIndex() {
s.consistIndex.SetConsistentIndex(e.Index)
}
var cc raftpb.ConfChange
pbutil.MustUnmarshal(&cc, e.Data)
removedSelf, err := s.applyConfChange(cc, confState)
s.setAppliedIndex(e.Index)
s.setTerm(e.Term)
shouldStop = shouldStop || removedSelf
s.w.Trigger(cc.ID, &confChangeResponse{s.cluster.Members(), err})
// ...
}
appliedi, appliedt = e.Index, e.Term
}
return appliedt, appliedi, shouldStop
}
3.4. 算法正确性
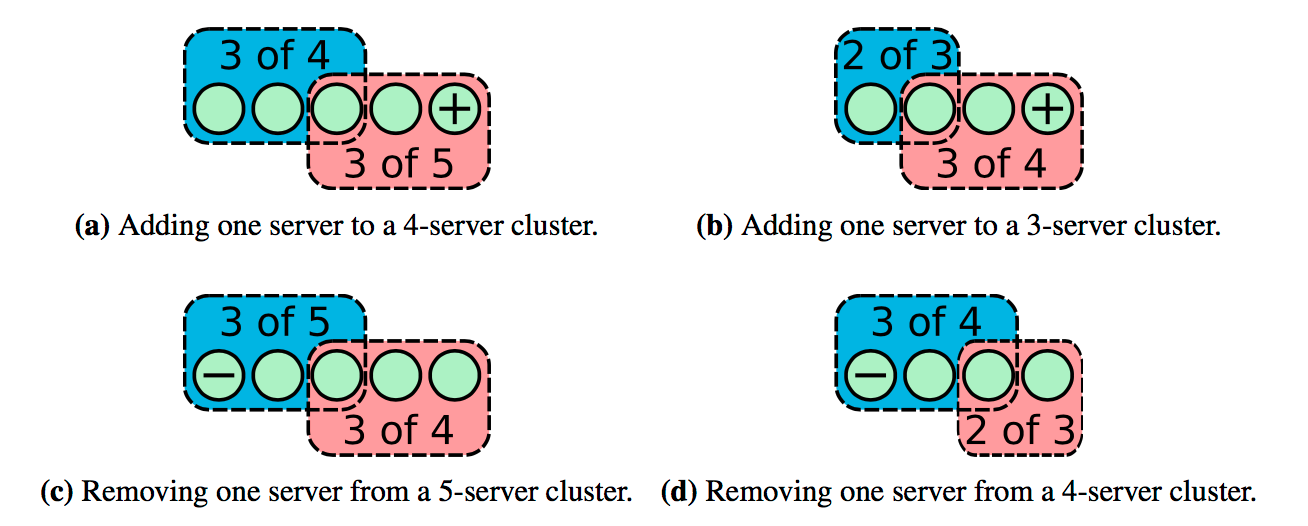
上述算法不是Joint Consensus,只是一个节点一个节点变更集群配置。
它的正确性来源于:只增加/删除一个节点时,新旧配置的majority必然重叠,不会有单独的一部分做出决定,防止了脑裂。
4. Joint Consensus
Raft论文中在变更配置时,采用了二阶段的协议,因此引入了Joint Consensus,代表了一个过渡的配置(即论文的$C_{old, new}$)。
- 第一阶段:状态从$C_{old}$转化成$C_{old,new}$,即Joint Consensus,需要$C_{old}$和$C_{new}$所有节点的半数以上同意
- 第二阶段:状态从$C_{old,new}$到$C_{new}$,需要$C_{new}$的节点半数以上同意
详细可参考这里。
etcd-raft内部已经实现了部分Joint Consensus的功能(可参考这里),不过似乎上层并没有接入这个功能(可能我有问题),所以这里就不详细说明了。
5. 总结
上文总结了etcd-raft的配置变更的内容。其内部原始实现并没有接入Joint Consensus,而是一个简单的单步变更。不过里面已经实现了Joint Consensus的基础。
下文将会顺着论文说明etcd-raft的快照。
