1. Pod调度
1.1. Deployment:自动调度
Deployment可以创建指定副本数量的Pod,用于无状态服务。运行时,Pod会被调度到不同Node上,并会自动维持副本数量。
同理还可以推广到StatefulSet等上面
调度策略见下。
a. NodeSelector:定向调度
通过定义NodeSelector,定向调度Pod到指定Node上。步骤如下:
-
给Node打Label
-
在Pod/Deployment等定义中,设置match label表达式
b. NodeAffinity:Node亲和性调度
相比NodeSelector,增加了软限制、优先采用等限制方式,进行调度。
有2种方式,位于affinity.nodeAffinity下(依旧是匹配Label方式):
-
requiredDuringSchedulingIgnoredDuringExecution:同NodeSelector
-
preferredDuringSchedulingIgnoredDuringExecution:要求尽量满足该要求,可配置权重
IgnoredDuringExecution:若一个运行时Pod所在Node的Label发生变更,不符合Pod的Node亲和性要求,则忽略变更,Pod继续运行
注意事项:
-
若同时设置NodeSelector和NodeAffinity,则需同时满足,才能运行到指定Node
-
若NodeAffinity设置多个
nodeSelectorTerms,只需满足一个即可 -
若一个
nodeSelectorTerms设置了多个matchExpressions,则需全部满足
c. PodAffinity:Pod亲和与互斥调度
调度时,不同Pod是否能在同一个拓扑区域(一群Node中)中共存。能共存就是“亲和”,不能共存就是“互斥”。
拓扑域用
topologyKey标识
依旧有2种方式,位于affinity.podAffinity/podAntiAffinity下(分别代表亲和与互斥):
-
requiredDuringSchedulingIgnoredDuringExecution:要求完全满足该要求,需要指定
-
topologyKey:拓扑区域的标识 -
labelSelector:拓扑区域内Pod的标签匹配
-
-
preferredDuringSchedulingIgnoredDuringExecution:要求尽量满足该要求,可配置权重
若上面的条件满足,“亲和”时会被调度到同一个Node上,“互斥”时会被调度到不同的Node上。
topologyKey的限制:
-
亲和性和requiredDuringScheduling的互斥性下,非空
-
若设置了LimitPodHardAntiAffinityTopology,那么requiredDuringScheduling的互斥性下,只能为kubernetes.io/hostname
-
preferredDuringScheduling的互斥性下,会被替换为kubernetes.io/hostname 、 failure-domain.beta.kubernetes.io/zone 及 failure-domain.beta.kubernetes.io/region 的组合
PodAffinity规则注意事项:
-
可配置Namespace,和Label Selector和
topologyKey同级 -
requiredDuringScheduling的所有
matchExpression需要全满足
d. Taint和Tolaration(污点与容忍)
Taint:被标记后的Node一般存在隐患,需要维护,不希望新Pod调度过来。
-
可通过
kubectl taint nodes设置,标记可以是多个 -
包含
key,value和effect,最后一个是效果,如NoSchedule,表示不要调度到该Node上
Toleration:调度时,可以容忍Taint信息,从而调度到有隐患的Node上。可在Pod定义中设置tolerations:
-
需要指定
key,operator,value,effect-
若后者为
Exists则不用指定value; -
若后者为
Equal,则需要指定value并需要和它相等; -
若
key为空,配合Exists,匹配到所有键值 -
若
effect为空,匹配到所有效果
-
-
会容忍所有匹配到Taint
Taint效果:
-
NoSchelue:不会调度Pod到该Node上 -
PreferNoSchedule:软性限制,尽量不调度到该Node上 -
NoExecute:若该Pod已经在该节点运行,则会被驱逐;否则不会调度该Pod到该Node上
常见用例:
-
独占节点:例如某些Group应用独占某些节点、独占有特殊硬件的节点等
-
定义Pod驱逐行为,应对节点故障:对应
NoExecute效果-
若Pod没设置Toleration,立即驱逐
-
若没设置
tolerationSeconds,则一直留在节点中;否则过了这段时间后被驱逐
-
-
系统会自动检查,给Node添加Taint,从而防止Node崩溃,例如未就绪、不可达、磁盘满、内存满、网络不可用等。包含2个机制,默认启用
-
TaintNodeByCondition:添加
NoSchedule的Taint -
TaintBasedEviction:添加
NoExecute的Taint
-
e. Pod Priority Preemption:Pod优先级抢占调度
资源不足时,释放低优先级的Pod,让更高优先级的Pod进来。
核心是驱逐(Eviction)和抢占(Preemption),都是释放低优先级的Pod,以让高优先级Pod调度。前者是kubelet行为,后者是调度器行为。
考虑因素:优先级、资源申请量、实际使用量,权重由高到低。
步骤:
-
定义PriorityClass,指定优先级
- 默认开启抢占,可指定关闭抢占,
preemptionPolicy为Never即可
- 默认开启抢占,可指定关闭抢占,
-
Pod定义中,设置
priorityClassName,引用1中的优先级
1.2. DaemonSet:每个Node调度1个Pod
DaemonSet会在每个Node调度1个Pod。
调度策略和Deployment类似,例如NodeSelector、NodeAffinity等,也能处理Taints和Tolerations问题。
1.3. Job:批处理调度
3种任务模式:
-
Job Template Expansion:1个工作项1个Job
-
Queue with Pod Per Work Item:工作项放入队列,1个Job消费,Job启动N个Pod,每个Pod执行1个工作项
-
Queue with Variable Pod Count:和前一个类似,但Pod数量可变
1.4. CronJob:定时任务
类似crontab用法,定时启动一个容器执行任务。
1.5. 自定义调度
调度器可由任意语言实现,然后将Pod定义中的schedulerName替换即可。
若自定义调度器未部署,则Pod一直Pending。
调度器基本基于通过kubectl或者apiserver接口的信息来实现。
1.6. Pod容灾
多区域的容灾,可在每个Zone建立1个Deployment,但难以迁移。
k8s 1.16引入Even Pod Spreading特性:
-
基于
topologyKey识别Zone -
通过
topologySpreadConstraints调整不同Zone的Pod均匀程度,-
maxSkew:最大不均衡数 -
whenUnsatisfiable:不满足时的动作
-
可在Pod定义文件中指定topologySpreadConstraints。
2. Init Container
应用容器初始化前,需要执行的初始化操作。
特点:
-
本质还是容器,但仅运行一次,先于应用容器执行
-
多个init container串行执行,都成功后,才能执行应用
-
若重启策略为
Never,若init container失败,则Pod启动失败 -
若重启策略为
Always,若init container失败,则Pod重启
-
-
可设置资源限制
-
readiness探针不可用
-
Pod重启时,init container会被再次执行
3. 升级与回滚
镜像更新时,需要重启以升级/回滚。
k8s采用滚动的方式解决该问题。
3.1. Deployment升级
可在strategy中配置,可选:
-
Recreate -
RollingUpdate,参数:-
maxUnavailable:不可用Pod数量上限(即每次滚动数量),可配置百分比 -
maxSurge:更新过程中的Pod数量超过定义数量的最大值,可配置百分比
-
RollingUpdate步骤:
-
创建新的ReplicaSet
-
逐步从旧的RS杀Pod,往新RS加Pod
-
最后新RS形成,删除旧RS
升级过程中再触发升级:最前面的旧版本会全部杀掉,直接创建新版。
不推荐升级时更新Label Selector。
3.2. Deployment回滚
通过kubectl rollout history获得升级的命令记录,然后调用kubectl rollout undo撤销即可。
3.3. 暂停与恢复Deployment部署
调用kubectl rollout pause/resume即可。
3.4. 其它管理对象的升级策略
a. DaemonSet
2种策略:
-
OnDelete:默认,手动删除旧Pod后触发升级(类似手动升级) -
RollingUpdate:同Deployment,但不能查看记录,也不能回滚(只能再提交旧版本,再次滚动部署)
在updateStrategy中设置。
b. StatefulSet
3种策略:
-
OnDelete:同DaemonSet -
RollingUpdate:删除并创建StatefulSet的每个Pod,创建顺序与终止顺序一致- 即从最大序号开始重建,每次更新1个Pod
-
Partitioned:指定一个序号,大于等于此序号的Pod被升级,其它保持旧版本
同样在updateStrategy中设置。
4. Pod扩缩容
4.1. 手动扩缩容
使用kubectl scale命令即可,多则创建新Pod,少则杀掉Pod。
4.2. 自动扩缩容
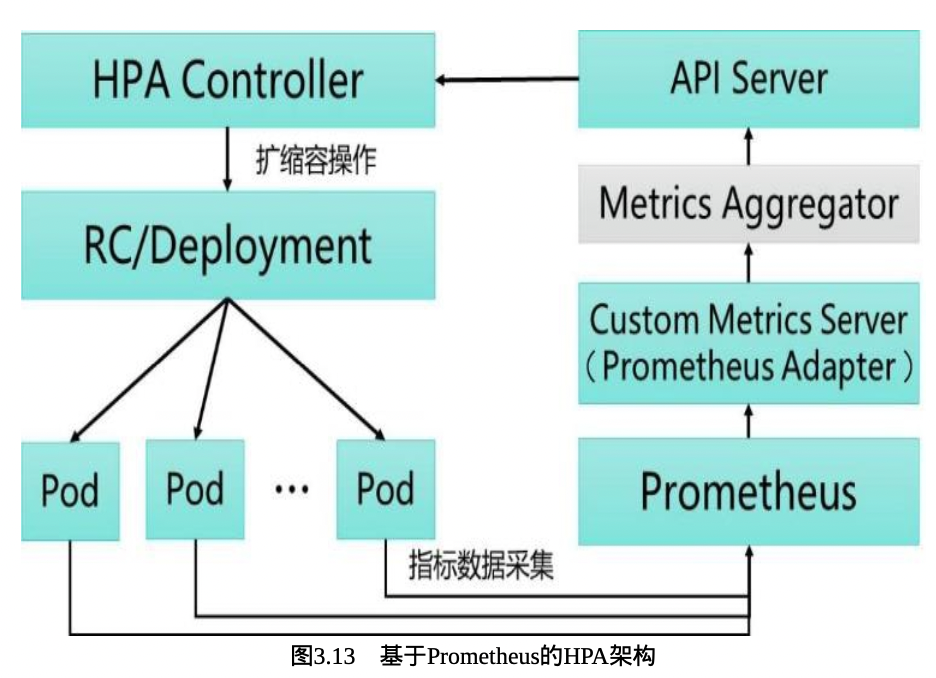
即HPA控制器。
基于Metric Server进行数据采集,周期检测Pod资源指标,并与HPA Controller扩缩容条件对比,然后向apiserver触发scale操作。
一个样例架构图如下所示: