1. Kubernetes API Server
提供k8s资源对象CRUD的REST接口,运行在kube-apiserver进程上。
1.1. 架构
从上到下:
-
API层:暴露k8s资源对象CRUD的REST API
-
访问控制层:鉴权,验证身份和权限
-
注册表层:资源对象以Registry形式保存
-
etcd键值数据库:资源对象实际存储的地方;并提供Watch API(与ZooKeeper类似),基于此设计List-Watch机制管理集群,响应集群事件
List-Watch机制:
-
api-server同样提供Watch API,供controller-manager、scheduler和kubelet监听,其它组件不需要直接访问etcd -
List-Watch可只监听自己感兴趣的事件(例如
kubelet只监听自己节点Pod的事件) -
步骤:
-
先调用List接口,获取相关资源数据,并缓存
-
启动Watch协程,监听事件更改
-
监听到事件后,将更改更新到缓存中
-

多版本数据转换:引用稳定的internal版本,以星形拓扑形式转换
定制资源CRD:用于扩展k8s,需要和api-server交互,要指定下面内容:
参考: https://kubernetes.io/zh/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions
-
元数据定义(YAML)
-
校验逻辑(YAML)
-
CRUD逻辑(YAML)
-
控制器(需自行实现)
1.2. Proxy API
某些API,api-server是充当代理的,转发到kubelet上,即数据来自Node
-
/api/v1/nodes/{name}/proxy:Node -
/api/v1/namespaces/{namespace}/pod/{name}/proxy:Pod -
/api/v1/namespaces/{namespace}/services/{name}/proxy:Service -
…
1.3. 集群模块间的通信

常见通信场景:
-
kubelet-api-server:-
kubelet向api-server报告状态,api-server更新到etcd中 -
kubelet监听api-server关于本节点的Pod信息,并执行相关操作
-
-
controller-manager-api-server:例如NodeController从api-server监听Node信息并执行相关操作 -
scheduler-api-server:监听api-server关于Pod创建信息,然后执行调度,将Pod绑定到目标Node上
每个模块都有内建本地缓存,通过List-Watch更新缓存,降低对api-server的压力。
1.4. API Server网络隔离
由于API Server是Master节点,属于内部安全区域,需要隔离,因此采用下面方式:
-
内部提供SSH通道
-
Network Proxy(推荐):将Master与Node网络隔离,通过Network Proxy解决网络连通性
-
Master网络:部署Konnectivity Server
-
Node网络:部署Konnectivity Agent
-
后者优势:
-
独立灵活扩展
-
可自定义实现高级功能
-
从API Server剥离出来,提升内聚性,不影响API Server功能
2. Controller Manager
通过List-Watch监听API Server,获得集群变化,并执行对应的集群控制逻辑。
内部包含多种控制器:如Replication Controller、Node Controller、ResourceQuota Controller、Namespace Controller、Service Controller 、Endpoint Controller、Deployment Controller、Router Controller、Volume Controller等。
2.1. Replication & Deployment Controller
为了保证Pod的个数等于定义中的设置,主要有3个作用:
-
确保集群中有且仅有指定数量的Pod
-
调整
spec.replica实现扩缩容 -
改变Pod Template实现滚动升级
2.2. Node Controller
实时获取Node信息(List-Watch、kubelet -> apiserver -> etcd),管理和监控集群各个Node。
工作流程:遍历各Node信息,并与本地缓存信息比较
-
没收到节点信息/第一次收到节点信息/节点状态变为非“健康”状态:更新探测时间与节点状态变化时间
-
收到节点信息,且发生变化
-
更新探测时间与节点状态变化时间
-
若某段时间内(gracePeriod),未收到节点状态信息,设置状态为“未知”
-
同步节点信息,若节点“非就绪”,则删除该节点
-
-
收到节点信息,没变化:更新探测时间与节点状态变化时间
2.3. ResourceQuota Controller
给资源对象分配资源的控制器。
支持三个层次的资源配额:
-
容器:CPU与Memory
-
Pod:所有容器的可用资源配置
-
Namespace:多租户级别的资源配置,例如Pod数量、RC数量、Service数量、PV数量等
创建资源信息流程:
-
api-server直接保持到etcd -
该控制器List-Watch读取并更新资源分配信息
确保资源使用不超过限定值:
-
利用
api-server的Admission Control,转发到该控制器 -
读取Resource Quota信息,判断资源请求是否合法
2.4. Namespace Controller
api-server将新namespace保存到etcd,Namespace Controller利用List-Watch更新这些信息。
若namespace要被删除:
-
被
api-server标记为Terminating,保存于etcd -
该控制器从
api-server读取到更新,删除下面到资源对象- 且Admission Controller和NamespaceLifecycle等插件阻止新建资源
-
该控制器同时对namespace进行finalize操作,删除
spec.finalizers信息 -
完成后,将namespace完整删除
2.5. Service Controller & Endpoints Controller
Endpoint Controller:
-
监听Service及对应Pod副本变化,更新保存对Endpoint列表
-
每个Node的
kube-proxy会获取每个Service完整的Endpoint列表,实现负载均衡- 因此需要EndpointSlice切片,不需获取完整列表,降低数据穿数量
Service Controller:k8s集群与外部平台之间的接口控制器,监听Service变化,并保证相关控制器和路由表的更新
3. Scheduler
调度Pod在哪个Node上执行,即将Pod安排到某个Node的kubelet上。
3.1. 调度流程
输入:待调度的Pod、全部Node信息;输出:Pod需要安排的Node
只与api-server交互,整体调度流程如下:
-
controller-manager给api-server待调度的Pod信息,api-server将待调度Pod写入etcd -
scheduler利用List-Watch得到待调度的Pod和全部Node信息 -
执行调度算法,开始调度
-
将调度结果返回
api-server,api-server写入etcd -
kubelet利用List-Watch得到Pod信息,生成Pod实例
3.2. 执行调度的内部流程
-
两阶段调度(旧版本):过滤Node候选节点,打分最高的记为结果
-
Scheduler Framework:增加更多的扩展点
[调度框架 Kubernetes](https://kubernetes.io/zh/docs/concepts/scheduling-eviction/scheduling-framework/)
4. kubelet
每个Node都有该进程。主要任务:
-
处理Master下发的任务
-
管理Pod及内部的容器
-
向Master注册并定期汇报状态
-
利用cAdvisor监控容器和节点资源
4.1. 节点管理
启动时,会向api-server注册自己的信息,即注册Node,并保存到etcd中。
此外,定时向api-server发送消息心跳,更新Node信息。
4.2. Pod管理
获取Pod清单:
-
静态Pod配置文件(
--config指定,不受controller-manager管理) -
URL(
--manifest-url指定)前两者为静态Pod,API Server会创建一个镜像Pod打标记
-
API Server(List-Watch机制)
所有本地Pod信息更新都会被kubelet监听,若需要修改Pod,则:
-
为该Pod创建数据目录
-
从
api-server拉取信息 -
给该Pod挂载Volume
-
下载需要的Secret
-
若已有Pod正在运行,先停止
-
为每个Pod创建一个Pause容器,容器用于接管Pod其它容器的网络
-
为Pod中每个容器执行
-
对不同散列值的容器,停止原容器;否则不处理
-
下载容器镜像,启动新容器
-
4.3. 容器健康检查
两类探针:LivenessProbe和ReadinessProbe。
方式也很多,例如Exec、TCPSocket(建立连接)、HTTPGet(>=200 <400)等。
4.4. 资源监控
旧版本:cAdvidor开源容器资源和性能分析代理工具,暴露REST API查询,但功能不行,被弃用
- 可通过使用DaemonSet自动启用
目前:Metric Server(核心指标,如Node/Pod的CPU、内存)+ 第三方组件(如Prometheus,自定义指标)
4.5. 管理容器运行时
kubelet通过例如gPRC等方式实现与Docker之间的控制。
Docker的容器运行时一般是containerd。
其它也有容器运行时的实现,但需要符合CRI接口规范,包括:
-
ImageService:镜像管理服务
-
RuntimeService:容器和Pod的生命周期管理
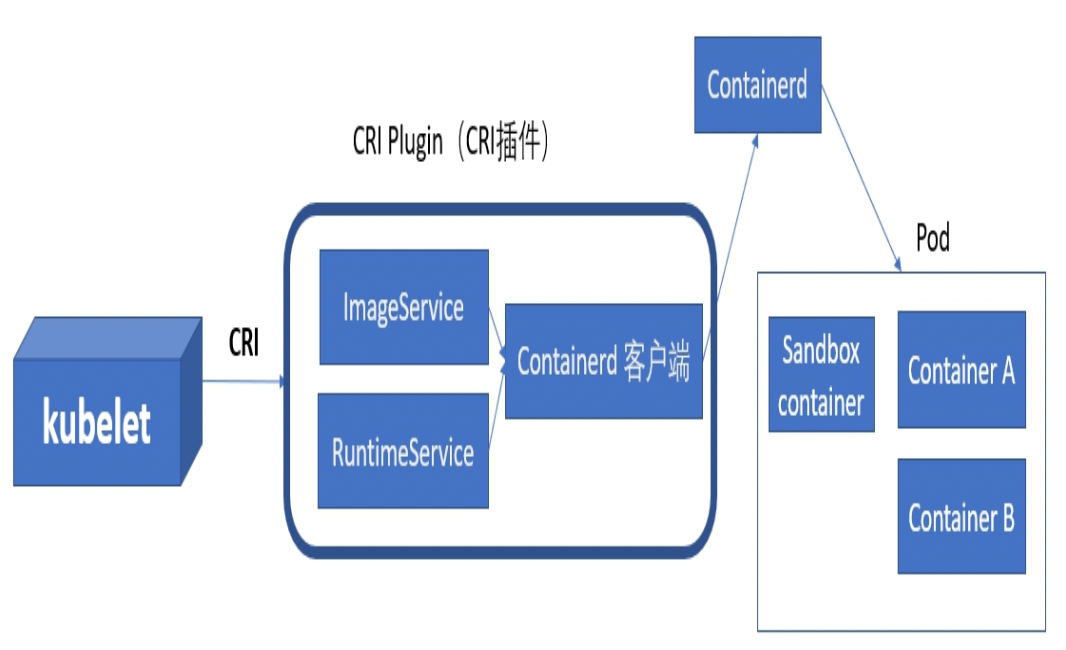
面对多种容器运行时,Pod为了选择某个容器运行时:
-
引入了RuntimeClass对象,具体配置可参考对应容器运行时
-
Pod定义中,指名
rumtimeClassName
5. kube-proxy
每个Node都有1个kube-proxy进程,用于Service的代理和负载均衡器,将流量路由到Pod上。
5.1. 第一代:userspace
真实的TCP/UDP代理。
Service的ClusterIP与NodePort等概念是
kube-proxy服务通过iptables的NAT转换实现的:
- ClusterIP/NodeIP+Port -> PodIP+TargetPort
5.2. 第二代:iptables
流量直接通过iptables的NAT机制转发,不需通过kube-proxy。
-
工作完全在内核态,性能更好
-
集群规模增大时,规则过多,性能下降明显
kube-proxy只是跟踪Service和Endpoint变更信息,修改iptables规则而已。
5.3. 第三代:ipvs
基于Netfilter实现,采用散列表管理规则,性能比iptables更高。
优点:
-
性能和扩展性更好
-
支持复杂的负载均衡算法
-
支持服务健康检查和连接充实
-
可动态修改ipset集合(一个IP段集合)
但没有类似iptables地址伪装、SNAT等功能,还需要搭配iptables使用(例如NodePort下)。
