1. CNM与CNI网络模型
1.1. CNM网络模型
包含3个组件:
-
Network Sandbox:容器内网络栈,包括接口、路由表、DNS等,可由Linux Namespace、FreeBSD Jail等实现。包含若干Endpoint。
-
Endpoint:与外部相连的网络接口,可由Veth设备对、Open vSwitch的内部port等实现。一个Endpoint只能加入一个Network。
-
Network:直接互连的Endpoint集合,可由Linux网桥、VLAN等实现。
Docker采用该模型。
1.2. CNI网络模型
a. 规范描述
提供容器的插件化网络解决方案,插件只需实现CNI接口。
只包含2个概念:
-
容器:拥有独立Linux Namespace的环境,例如Docker容器
-
网络:一组互连的实体,实体拥有唯一IP地址,可以是容器、物理机、网络设备
容器网络通过插件实现,包括2类:
-
CNI Plugin:负责容器配置网络资源
-
IPAM Plugin:负责容器IP地址分配和管理
b. 容器与插件的关系
容器与CNI插件的关系和工作机制遵循:
-
容器在调用插件前,需要创建新的网络namespace
-
容器需要规定它归属的网络和执行的插件
-
配置为JSON格式
-
容器必须按照顺序运行CNI插件,从而将容器添加到网络中
-
容器运行结束后,需要反向执行CNI插件,断开网络连接
-
同一个容器不能并行执行CNI插件
-
容器必须对ADD和DEL操作设置顺序,DEL操作应该幂等
-
容器必须用唯一ContainerID标识,存储状态对插件应使用联合主键存储(network name、CNI_CONTAINERID、CNI_IFNAME)
-
容器不能对同一实例连续调用两次ADD,仅在ADD操作使用不同网络接口名称时,才能多次添加到特定网络中
-
除非标记可选,CNI结构的字段都是必填字段
c. CNI Plugin接口
包括ADD、DELETE、CHECK和VERSION。
ADD
将容器添加到某个网络中。当容器创建好网络命名空间后,调用该操作,以完成该网络命名空间的配置。
参数:
-
容器标识
-
容器的网络命名空间路径
-
网络配置JSON文档
-
其它参数
-
容器的虚拟网卡名称
返回:
-
网络接口列表
-
每个接口的IP地址、网关、路由信息
-
DNS服务信息
DEL
容器销毁时,将其从网络中删除。
参数:基本条目同ADD。
执行该操作时需注意:
-
参数与ADD传入的一致
-
DEL应该释放容器所有的网络资源,且与ADD顺序反向
-
若前一个操作是ADD,则应在配置文件JSON补充
prevResult,否则插件应尽可能释放容器相关所有资源,并返回成功 -
若对ADD结果缓存,则DEL后必须清空
-
DEL操作结果应通常返回成功
CHECK
检查容器网络是否正确设置,结果为空(成功)或错误信息(失败)。
参数:基本条目同ADD
执行该操作时需注意:
-
必须设置
prevResult字段,表明检查的网络接口和网络地址,该字段应在ADD后补充 -
允许之后的插件对网络资源进行修改
-
若
prevResult中某个资源处于非法状态,或未在result跟踪的资源处于非法状态,或容器不可达,应返回错误 -
ADD或执行其它代理插件后,应立刻CHECK
-
不得在ADD前CHECK,不得在DEL后CHECK,不得在明确
disableCheck时CHECK -
可假设:一次CHECK失败,容器永远处于错误配置中
VERSION
查询网络插件支持的CNI版本号。无参数。
d. CNI网络配置
一个CNI网络配置主要包含:
-
cniVersion:CNI版本号 -
name:网络名称 -
type:插件可执行文件名称 -
args(键值对):其它参数 -
ipMasq:是否设置IP Masquerade -
ipam:IP地址管理配置 -
dns:DNS服务配置
上述配置会组成一个列表,为容器提供多个网络连接机制,包含:
-
cniVersion:CNI版本号 -
name:网络名称 -
disableCheck:是否禁止CHECK操作 -
plugins:一组网络配置列表,每项见上
e. IPAM Plugin与IP地址分配
IPAM Plugin负责容器IP地址分配、网关、路由和DNS。同样需要实现CNI接口和规范。
它由主CNI Plugin调用,结果会返回给主CNI Plugin。
典型实现:host-local插件、dhcp插件。
1.3. Kubernetes使用网络插件
支持2中插件:
-
CNI插件
-
kubenet插件:使用bridge和host-local CNI插件实现一个基本的
cbr0
2. 开源容器网络方案
Kubernetes的网络模型假定所有Pod都在一个可以直接连通的扁 平网络空间中,这在私有云中可能不存在。因此需要组网,才能运行容器应用。
2.1. Flannel
实现2点:
-
给每个Pod分配不冲突的IP地址
-
IP地址间建立覆盖网络,使其两两能直接通信
机制:
-
创建
flannel0网桥,一端连docker0,另一端连flanneld进程 -
flanneld进程:-
监听
etcd,维护了节点间Pod路由表 -
数据从Pod中发出,经过的
docker0转发到flannel0,flanneld服务监听它 -
源主机的
flanneld将数据内容封装,根据路由表投递给目的节点的flanneld -
数据到达后被解包,直接进入目的节点
flannel0,然后被转发到docker0,最后就像本机容器通信一样的由docker0路由到达目标Pod
-

缺点:组件多,时延较高,默认UDP不可靠,TCP大流量高并发下需要测试
2.2. Open vSwitch
虚拟交换机软件,但可以建立多种通信通道(如GRE、VxLAN)。这里建立L3到L3的隧道。
机制:
-
手动建立Linux网桥
br0 -
建立Open vSwitch的
ovs网桥,增加gre端口,设置目标的NodeIP为目标地址- 需要对每个Node做这样的操作,即$N$个Node,需要建立$N * (N-1)$ 个隧道
-
将
ovs网桥作为网络接口,加入docker0网桥上 -
重启
ovs和docker0网桥,添加Docker地址段到docker0网桥的路由规则项,- 使得目标为Docker容器的IP路由到
docker0网桥,docker0网桥决定是否内部转发,或转发到GRE隧道
- 使得目标为Docker容器的IP路由到
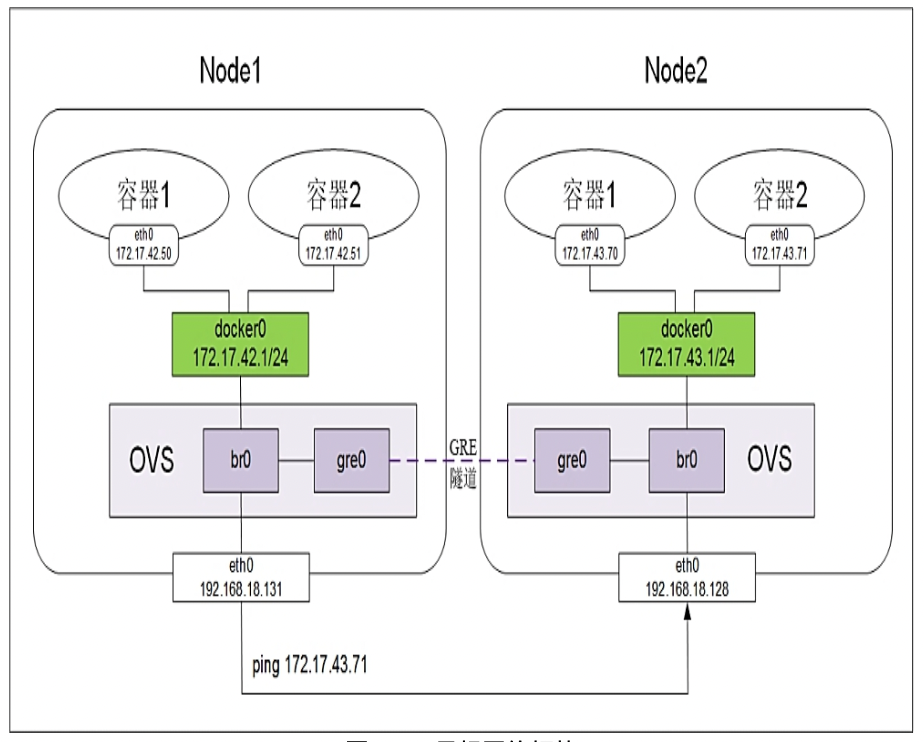
2.3. 直接路由
手动部署,只需要让本Node知道对方Node到docker0地址,并创建好路由表即可。
可通过部署MultiLayer Switch实现,配置每个docker0子网地址到对应Node到路由项,从而实现数据转发。
| 例子可参考:[k8s权威指南笔记:网络原理(1) - keys961 | keys961 Blog](https://keys961.github.io/2022/04/05/k8s%E6%9D%83%E5%A8%81%E6%8C%87%E5%8D%97%E7%AC%94%E8%AE%B0(6)/)的4.3.节。 |
可能出现路由表过大的问题,上千个Node需要测试和评估。
2.4. Calico
基于BGP的纯三层网络方案。
每个节点利用内核实现vRouter,负责数据转发,路由表通过BGP1协议广播和学习。小规模集群可直接互连,大规模集群可使用BGP route reflector。
可参考: https://cloud.tencent.com/developer/article/1482739
组件如下:
-
Felix:运行在每个Node上,负责设置网络资源
-
etcd:Calico使用的后端存储
-
BGP Client:将路由学习通过BGP协议进行广播
-
Route Reflector:负责大规模集群的分级路由分发
-
CalicoCtl:命令行管理工具
3. Kubernetes网络策略
用于目标Pod网络访问的控制/限制。包括
-
Network Policy:Pod的网络访问策略规则
-
Policy Controller:策略控制器,以实现设置的访问规则
大致流程:
-
Policy Controller需要实现一个API Listener,监听新的NetworkPolicy
-
将规则通过各个Node的Agent进行实际设置,Agent需要通过CNI插件实现
具体字段可参考: https://kubernetes.io/zh/docs/concepts/services-networking/network-policies/
