1. Introduction
CRAQ是一个分布式对象存储,主要特点是:
- 使用提升过的链式复制,保证强一致性,并通过在链上分摊查询,提高读操作的吞吐
- 支持最终一致性读,以降低写操作期间的延迟,并在瞬时分区时降级操作为只读
- 支持跨数据中心部署,并保留很好的局部性
此外,本文还介绍了CRAQ的扩展:
- 多对象更新事务
- 利用广播提高大对象的写性能
2. 基本的系统模型
2.1. 接口与一致性模型
CRAQ支持2个接口:
write(objId, value)read(objId) -> value
一致性模型有2个:
- 强一致性:全局上,读写操作以一个顺序执行,且读一定能看到之前最新的写
- 最终一致性:全局上,写操作以一个顺序执行,但读会返回旧数据,存在一段时间的不一致
2.2. 链式复制(CR)
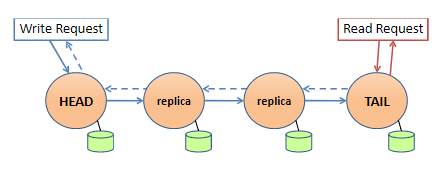
如上图所示:
- 写请求由头节点处理,数据沿链复制到尾节点,由尾节点最后提交(响应沿链反向传回给客户端)
- 读请求全由尾节点处理(因此只会返回已提交的数据)
链式复制已被证明,复制的负载能均摊,且能由更好的吞吐,且错误恢复更快更容易
链式复制能达到强一致性,读全由尾节点处理是必要的,因为读中间节点会强一致性冲突(因为并发的读不同节点,会由于数据传播,读到不一致的数据)。
但是它限制了扩展性,因此CRAQ对此进行优化,使得读可以在链上任意节点执行,并保证强一致性。
2.3. 链式复制下的分摊查询(CRAQ)
CRAQ对链式复制进行扩展,实现了分摊查询:
-
每个节点保存多版本的对象,每个版本的对象包含一个版本号(单调递增)和一个标记(标识该版本是
clean还是dirty,初始为clean) -
当节点收到新版本的对象,将最新版本追加到该对象的列表中
- 若节点不是尾节点,则标记最新版本是
dirty,并传播给下一个节点 - 若节点是尾节点,则标记最新版本是
clean(此时该版本的写已经提交),并沿链反向传播ACK(包含版本号)给其它节点
- 若节点不是尾节点,则标记最新版本是
-
当节点收到尾节点的
ACK,将最新版本标记为clean,并可以删除旧版本的数据 -
当节点收到读请求
- 若最新版本是
clean,直接返回数据 - 若最新版本是
dirty,则- 先向尾节点询问最新已提交的版本
- 根据尾节点返回的版本,返回对应版本的数据(可以保证该版本肯定没有被删除)
读请求可参考下图:
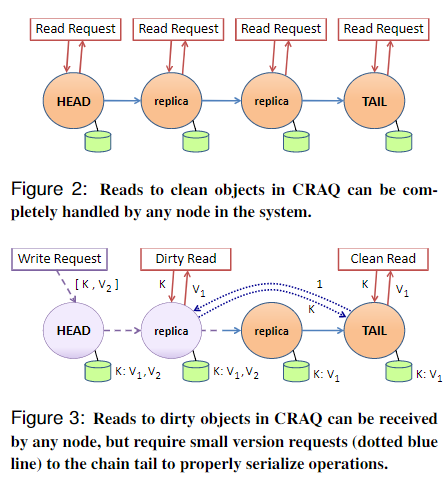
- 若最新版本是
以上对链式复制协议的修改,有下面的好处:
- 对于读多的场景,很容易将读负载分摊到链上所有的节点,达到线性扩展
- 对于写多的场景,即使需要向尾节点询问版本号,但是询问版本号的负载远比完整读请求的负载小,因此总吞吐量依旧比原始的链式复制协议好
2.4. CRAQ的一致性模型
CRAQ相比CR,也支持一些一致性模型:
- 强一致性:同2.1.
- 最终一致性:基本同2.1.,但是相比CR能在特定节点能实现单调读(如会话场景),CRAQ不能实现
- 有限不一致的最终一致性:返回不一致的数据,但有一定的限制,例如时间限制、版本号限制等
- 若链可用,则可能返回新的没提交的数据(请求在链的前面部分)
- 若链被分区了,则可能返回比已提交的更旧的数据(请求在原链分区后的后面部分)
2.5. CRAQ的故障恢复
CRAQ故障恢复和CR类似:
- 链上每个节点知道前驱和后驱节点
- 头节点故障,其后驱节点接管;尾节点故障,其前驱节点接管
- 中间节点故障,则从链中移除;恢复后再插入到链中,且能插到任意部位(而CR只能插到尾部)
详细会在后面第5节叙述。
3. 扩展CRAQ
3.1. 链放置策略
一个对象的标识由“链标识符”和“键标识符”构成:
- 链标识符决定CRAQ中的哪些节点将存储该链中的所有密钥
- 键标识符在每条链内唯一
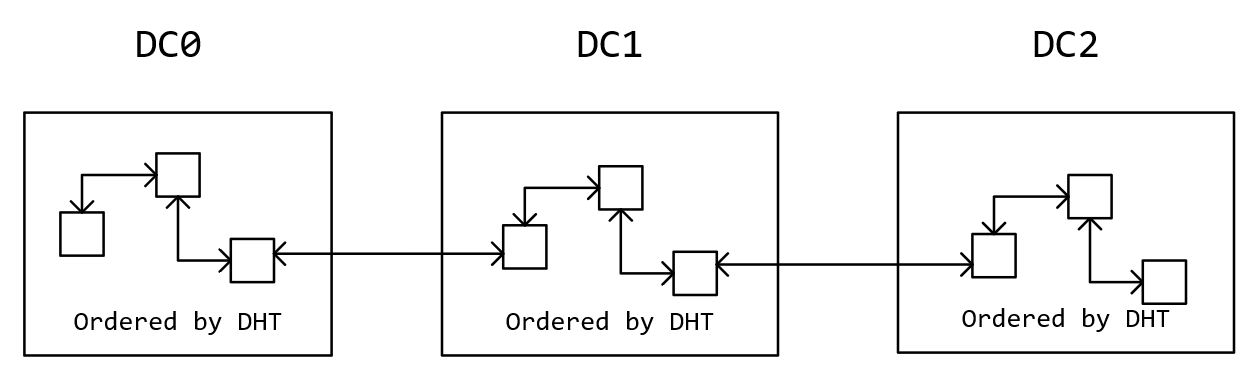
CRAQ可以为不同的数据中心配置不同长度的链,下面展示一个链的几个可用的配置方式:
{num_data_centers, chain_size}:定义了每个数据中心存储链节点的数量,但没指定是哪几个数据中心{chain_size, data_center_id_1, data_center_id_2, ...}:列表中的每个数据中心存储指定数量的链节点,整个链的头在第一个数据中心,整个链的尾在最后一个数据中心,一个数据中心的链头与前一个数据中心的链尾相连,一个数据中心的链尾与后一个数据中心的链头相连{data_center_id_1, chain_size_1, data_center_id_2, chain_size_2, ...}:等效于第2种方式,只是每个数据中心存储链节点的个数可不一样
一条链具体分布在数据中心的哪些节点,默认采用一致性散列(即对多条链进行分片)。
CRAQ支持更复杂的数据中心配置方式,这里省略。
3.2. 数据中心内的CRAQ
数据中心内,通过数据分片提高扩展性。
有多种方法将数据进行分片到多条链上:
- 一致性散列
- 使用成员管理服务来分配
3.3. 跨数据中心的CRAQ
首先是客户端的优化:选择距离最近的数据中心和节点,提高局部性,由于CRAQ没规定只能读尾节点,因此它很容易实现。
因此可以进一步优化链构建时节点的选择,提高局部性,以降低网络开销(一致性散列的方式可能不是最优的)。
3.4. ZooKeeper协调服务
分布式容错的协调服务很容易出错,因此CRAQ使用ZooKeeper进行分布式协调服务,包括管理成员、存储元数据等等(因此节点加入/离开时,或元数据改变时,其它节点能收到通知)。
ZooKeeper能干很多事情,详情可见此。
CRAQ引入ZooKeeper的挑战是适应多数据中心的场景(因为ZooKeeper并不是为多数据中心而设计的):
- CRAQ的实现依旧保证了CRAQ节点能收到本集群ZooKeeper节点的通知,此外仅被有关链和与它们相关的节点通知
- 降低跨数据中心的网络开销和冗余
- 构建层次的ZooKeeper部署:每个本地数据中心包含本地的ZooKeeper集群,并选择其中一个实例加入到全局ZooKeeper集群
- 修改ZooKeeper源码,使其能感知网络拓扑
CRAQ修改了ZooKeeper的源码,使其能感知网络拓扑,从而降低跨数据中心的网络冗余和开销。
4. 扩展
4.1. 微事务
CRAQ提供键的扩展以支持事务型操作。
a) 单个键操作
单个键的事务操作很容易实现,CRAQ支持的操作有:
- Prepend/Append
- Increment/Decrement
- Test-and-Set
对于Prepend/Append和Increment/Decrement,直接将变更作用于链头的最新版本,即使它是dirty的,然后生成一个完整的写操作沿链传播。若这种操作很多,链头节点可以缓存操作以执行批量更新。
对于Test-and-Set操作:
- 头节点检查最近提交的版本号和参数版本号是否一致
- 若不一致,或者存在未提交的版本,则拒绝操作
- 若一致,则更新并将变更沿链传播
- 头节点也可以检查值是否一致,但是会引入复杂性:
- 若检查最近已提交的值(通过询问尾节点),则会丢失当前正在执行的写
- 若检查最新未提交的值,则不满足一致性约束
- 因此头节点会临时锁住这个对象,直到它
clean,然后再进行操作- 若不一致,则拒绝操作
- 若一致,则更新并将变更沿链传播
b) 单条链操作
微事务由比较集合、读集合和写集合定义:比较集合测试给定地址的值是否与参数是否一致,若一致则执行读写操作。
微事务使用乐观的2PC协议,适用于少量写的场景:
- prepare:尝试获取所有指定地址数据的锁
- commit:获取所有锁后,执行提交;若没获取所有锁,释放锁,然后重试
CRAQ中单链事务只会涉及到头节点(因此2PC简化到1个节点上),所以获取锁只需要等待对象clean即可(见test-and-set)。
c) 跨多条链操作
跨多条链的操作,也只需要将乐观2PC协议应用到对应的几个头节点即可,头节点锁住所有对象,直到事务提交。
4.2. 通过广播降低写延迟
CRAQ使用广播协议提升写性能,尤其是大对象、长链的写。
每条链会创建一个广播组(因为链成员是稳定的):
- 数据中心内部:使用网络层广播协议
- 跨数据中心:使用应用层广播协议
- 广播不需要有序和可靠
有了广播组后:
- 复制不需要串行沿链传播,而是广播到整个链
- 只有元数据才需要沿链传播,保证所有副本被其它节点
- 若节点没收到广播消息,它会从前驱节点拉数据(收到提交消息后,传播提交消息前)
- 尾节点也广播
ACK消息给前面的节点,若前面的没收到,则会在下一次读时询问尾节点,从而让数据clean
5. 实现细节
5.1. ZooKeeper的集成
CRAQ使用ZooKeeper进行集群管理和协调:
- 初始化,CRAQ节点创建临时节点
/nodes/dc_name/node_id,存储节点的IP和端口- 可查询
/nodes/dc_name以获得某个数据中心的节点列表
- 可查询
- CRAQ节点加入集群后,在
/nodes/dc_name创建一个Watch,监听它的子节点列表,以监听节点的加入和离开- 可通过
node_id前缀进行分区,这样CRAQ节点可以监听更少的内容
- 可通过
- 当CRAQ节点收到创建链的请求,则创建
/chains/chain_id(160 bits),内容取决于3.1.的链放置策略,但内容不包含节点列表信息,只包含链的配置信息- 任何加入该链的节点都要查询它,并在它上面创建Watch,以监听链的元数据变化
5.2. 链上节点的功能
链上节点实现了大多数CRAQ的功能,下面是一些实现细节。
加入集群时:
-
节点会生成随机ID,然后根据one-hop DHT一致性散列加入到集群
-
一个节点所在链的前驱和后驱节点,由DHT环顺序决定
- 数据中心子链的头节点:链ID散列值在DHT的后续节点
- 数据中心子链的尾节点:头节点的某个属性$S$散列值在DHT的后续节点,$S$由链的元数据决定
对于网络通信:
- 节点使用TCP协议(关闭Nagle算法)
- 维护前驱、后驱、尾节点的长连接
- 维护连接池,外部请求使用pipe-line的方式,以round-robin策略分配连接
对于存储:对象都存于内存(也可以存于磁盘,如和RocksDB集成)
对于跨数据中心的链:
- 一个数据中心的子链尾与另一个数据中心的子链头(后继节点)维护一个连接
- 若节点和另一个数据中心维护连接,则需要监听对应数据中心的节点列表
- 但是外部数据中心节点变更的通知,会从本数据中心的ZooKeeper上收到(ZooKeeper被CRAQ修改过,3.4.有提及)
5.3. 处理成员变更
注意2.3.的蓝色虚线,即反向传播,它对故障恢复非常重要,能在节点加入/离开时维护一致性。
CRAQ的恢复能在CR的基础上,能在恢复过程中保证一致性,即使恢复过程中又出错。这需要前向和后向的信息传播:
- 后向传播:不仅需要传播最新已提交的版本数据,还要传播后面未提交(newer)的版本数据
- 前向传播:原本只传播最新的版本数据,恢复时/加节点时需要传播所有状态的对象
这里以一个例子说明:
- 定义:以节点$N$的视角,节点$N$对应的链为$C$,它的长度是$L_{C}$
- 添加一个节点$A$:
- 若$A$是$N$的后驱节点:$N$将链$C$的所有对象传给$A$(若$A$曾在$C$里,可只传部分需要的对象)
- 若$A$是$N$的前驱节点:
- 若$N$不是头节点:回传所有对象到$A$
- 若$N$是尾节点:$A$接管$N$称为尾节点
- 若$N$后继节点是尾节点:$N$成为尾节点
- 若$N$是头节点,$A$的散列值位于$C$与$N$之间:$A$成为头节点
- 若$A$是位于$N$之前,距离在$L_{C}$之内:
- 若$N$是尾节点:
- 放弃尾节点的任务,停止参与链的角色
- 标记链$C$的本地对象存储为可删除的
- 然后重新加入链中
- 若$N$后继节点是尾节点:$N$执行尾节点的任务
- 若$N$是尾节点:
- 若都不满足,则不做任何事
- 删除一个节点$D$:
- 若$D$是$N$的后驱节点:$N$将所有对象传给新的后继节点(可优化为传必要的新数据)
- 若$D$是$N$的前驱节点:
- 若新前驱节点不是头:回传所有的对象到新前驱节点
- 若$D$是头节点:$N$接管头节点任务
- 若$N$是尾节点:$N$停止尾节点任务,传播所有的对象给$N$的新后继节点
- 若$A$是位于$N$之前,距离在$L_{C}$之内,且$N$是尾节点:$N$停止尾节点任务,传播所有的对象给$N$的新后继节点
- 若都不满足,则不做任何事
