1. Introduction
Aurora是一个AWS上的分布式OLTP关系数据库,而本文的一个重要观点是:性能瓶颈从CPU和存储变成了网络,因此将计算与存储分离。
- 数据库实例(计算层)和存储层松耦合
- 数据库实例(计算层)仍包含大部分核心功能,如查询、事务、锁、缓存、访问接口、undo日志等
- redo日志相关功能下移到存储,如日志处理、故障恢复、备份还原等
这样的优势有:
- 底层存储层本身是分布式存储服务,可应对故障
- 数据库实例(计算层)只往下面存储层写redo日志,降低两层之间的网络压力
- 部分核心功能(故障恢复、备份还原等)移到存储层,可后台异步执行,不影响前台任务
论文主要包括三大块:
- 如何在云上实现持久化,基于quorum模型,使存储层能弹性容错(第2节)
- 如何将计算层下层的日志处理功能转移到存储层上(第3节)
- 如何在分布式存储中消除多阶段同步,并避免开销巨大的崩溃恢复和检查点操作(第4节)
2. 可伸缩的持久性
本节介绍quorum模型,并介绍存储分段。
Aurora将两者结合,实现持久性、可用性、少抖动,并解决大规模存储的相关问题。
2.1. 复制及其相关的错误
大规模下,错误经常发生,所以需要复制以容错。
Auroma使用基于quorum的复制协议:
- 记副本个数为$V$个,读需要$V_{r}$个副本的投票,写需要$V_{w}$个副本的投票
- 首先要保证必有一个副本是最新的,即$V_{r} + V_{w} > V$
- 写需要有多数的同意,防止写冲突,即$V_{w} > V/2$
常用配置下,Aurora通常将副本分布到3个AZ(可用区),每个AZ有2个副本,即$V=6$,然后设置$V_{r}=3, V_{w}=4$。这样它可以:
- 一个AZ整个故障,依旧不影响写服务(AZ)
- 一个AZ整个故障,另一个AZ一个副本故障,依旧不影响读服务,且不丢失数据(AZ+1)
2.2. 分片存储
以2.1.的AZ+1故障为例,我们需要保证两个完整AZ故障的概率足够低,才能保证quorum有效。
而故障频率(MTTF)不可知,因此需要降低故障修复时间(MTTR),从而降低2个AZ同时故障的概率。
解决方式是分片存储:
- 副本根据固定大小分片(如10GB)
- 以2.1.为例,每个分片被6路复制到3个AZ上,每个AZ有2个,这6个分片组成一个保护组(PG)
Aurora存储由若干个PGs构成,而PGs由EC2+SSD存储节点构成。
分片后,每个分片就是一个故障单位,恢复时只要恢复指定分片即可,速度会非常快。这降低了MTTR,从而提高了可用性。
2.3. 弹性容错的运维优势
Aurora能对长短故障都有弹性,这基于quorum协议和分段存储。
因此,系统可灵活应对故障,且运维方便,如:
- I/O压力过大:可剔除某个分段,通过迁移热点数据到冷节点上,quorum机制可很快地修复
- 系统更新导致的不可用:可临时将节点剔除,待完成后再加入到系统
- 软件更新:同系统更新
以上操作,都是分片粒度滚动进行,对外完全透明。
3. 日志即数据库
“日志即数据库”即:redo日志包含所有数据,因为它可回放。
即数据库就是redo日志数据流
本节介绍Aurora的计算存储分离架构是如何体现这个思想的。
3.1. 写放大问题
在传统关系数据库跨数据中心的复制场景下,会产生非常多的磁盘和网络I/O,性能糟糕。
下图以MySQL为例:
- AZ1和AZ2各部署MySQL实例,进行同步镜像复制
- 底层存储使用EBS,每个EBS还有一个自己的镜像
- 另部署S3执行redo日志和binlog的归档,以实现基于特定时间点的恢复
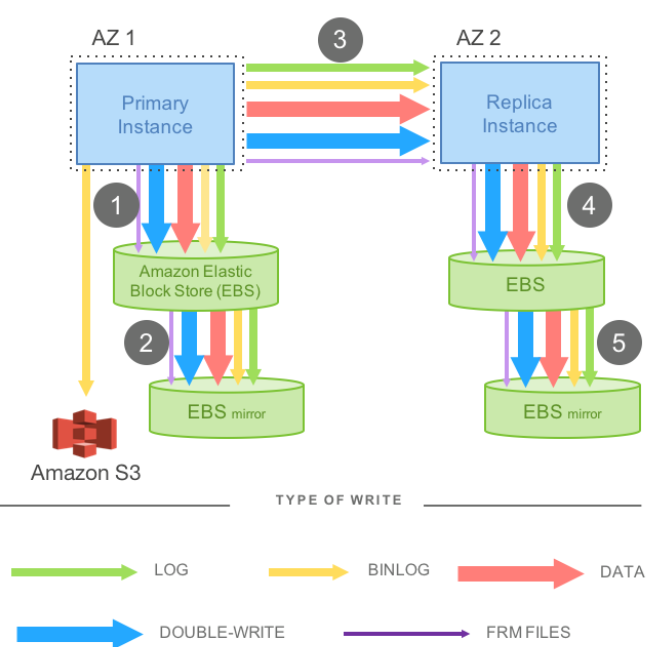
那么一个写操作需要5步,1、3、5是串行同步的,因此性能很差。以分布式观点,它是一个4/4的write quorum(4个EBS镜像),写性能可见也是很差的。
3.2. 将Redo日志处理下放到存储层
传统数据库中:
- 写操作不仅修改数据页,修改后同步产生redo日志项
- 提交事务时,将redo日志刷屏成功才能返回
Aurora中:
- 写操作只产生redo日志项
- 存储层收到redo日志项,回放日志得到新数据页
- 避免从头回放,存储层定期物化数据页版本
架构如下所示:
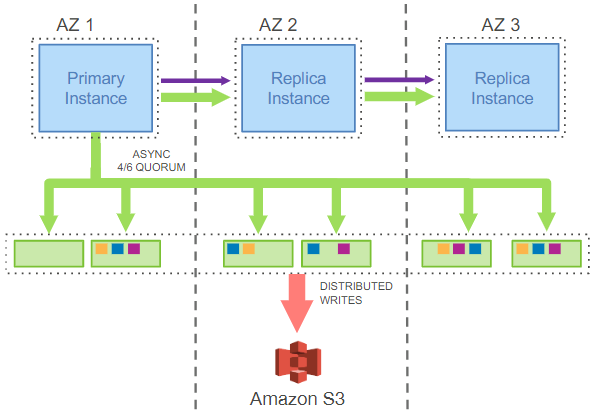
- 三个AZ中,AZ1是主,其它AZ是从
- (计算层)实例和存储层只传递redo日志和元数据
- 写时主实例向6个存储节点发送redo日志,需要4个应答才认为日志持久化了
- 回放日志可在后台就行,若读操作得到的是旧数据页,则会触发日志回放
- 存储节点定期物化数据页,恢复时只需回放很少的日志,非常快速
3.3. 存储服务设计的关键点
Aurora设计的关键原则是减少前台响应时间,所以尽可能将操作在后台异步执行,并根据压力自适应分配资源。
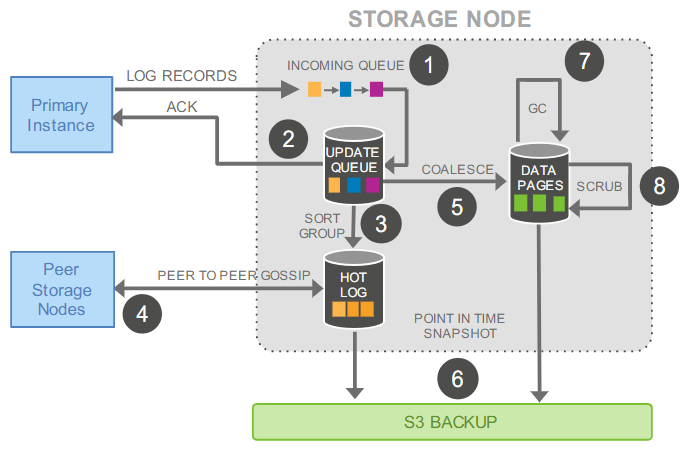
下面是一个写操作的具体流程:
- 数据库实例(计算层)收到写请求,生成redo日志项,发送给存储节点,存储节点将日志项添加到内存队列中
- 存储节点本地持久化redo日志项,并响应数据库实例
- 整理日志,检查日志缺失
- 和其它存储节点gossip,填补日志缺失
- 回访redo日志,生成新数据页
- 周期生成快照,备份数据页和日志到S3系统
- 周期回收过期版本的数据页/快照
- 周期对数据页进行校验
整个过程中,只有1和2是前台串行的(会影响延迟),其它都是后台操作。
4. 日志延伸:一致性
本节介绍如何不用2PC提交协议下,如何生成redo日志,以保证持久化状态、运行时状态和副本状态的一致性。
具体如下:
- 在崩溃恢复时,如何避免昂贵的回放开销
- 解释常规操作,并解释如何维护运行时和副本的一致性
- 提供恢复过程的具体细节
4.1. 异步日志处理
首先介绍一些概念:
- LSN:每个redo日志全局唯一且单调递增的序列号
- VCL:表示LSN在VCL之前,收到的日志在本存储节点是完整的
- 故障恢复时,VCL之后的日志都要截断
- CPLs:事务可分成多个最小原子的mini-transaction(MTR),每个都有对应的最后一条日志LSN,这就是CPL;一个事务有多个CPL,所以叫做CPLs
- VDL:最大已持久化的LSN,满足
- VDL $\le$ VCL
- VDL是CPLs中最大的一个
从上面可知,日志完整性和日志持久化是不一样的。
易知VDL表示了数据库处于持久化一致的位点,所以在故障恢复时:数据库以PG为单位,确认VDL,截断大于VDL的日志。
4.2. 标准操作
a) 写
数据库实例向存储节点传递redo日志,收到足够的票数后,标记事务提交,VDL增加,从而进入新的一致状态。
不过由于系统并发执行很多事务,所以要避免VDL追不上LSN,有:
- 定义并设置LAL,即LSN与VDL差值的上限,避免存储层成为瓶颈
而由于底层存储是分片的,每个PG/每个分片只能见到部分日志,为保证PG/分片上日志的完整性,有:
-
每条日志有当前PG前一条日志的指针
-
定义SCL,表示LSN在SCL之前,收到的日志在本PG是完整的,存储节点通过gossip填补缺失的日志,以推进SCL
b) 提交
提交是异步的:
- 每个事务包含commit LSN,当VDL大于事务的commit LSN时,表示事务redo日志都已经持久化,则向客户端回复事务已成功执行
- 处理回复是由单独线程执行的,因此整个提交流程不会阻塞
异步提交极大提高了系统的吞吐。
c) 读
读先从缓冲池获取,若缓冲池满才读盘,此时会挑选并淘汰数据页。
但是对于淘汰的数据页,Aurora直接丢弃,不会刷盘。所以需要保证被淘汰的数据页page LSN要不超过VDL,这就需要两个约束:
- 数据页上的修改都已经持久化了
- 缓存未命中是,通过数据页和VDL总能得到最新的数据页版本
对于读操作,正常情况下,不需要quorum:选定一个存储节点进行读取,它需要满足有最新VDL的数据。
d) 复制
写副本实例(主实例)可与至多15个读副本实例(从实例)共享一套分布式存储,因此增加读副本(从实例)不会消耗I/O资源,即零成本。
从上文可知,写副本会向读副本发送日志,读副本会回放日志,它需要满足,若不满足则忽略日志项:
- 回放日志的LSN不超过VDL
- 回放日志要以MTR为单位,确保副本能看到一致性视图
4.3. 故障恢复
常规数据库采用基于ARIES协议进行故障恢复:
- 周期性做checkpoint
- 从上一个checkpoint回放redo日志
- 根据undo日志回滚未提交的事务
这需要检查点频率和故障恢复时间做权衡,但Aurora不需要。
Aurora虽然也采用类似的方法,但是基于计算存储分离以及分片的设计:
- 存储层部分失效时,能快速恢复
- 数据库实例宕机后:
- 故障恢复只需要通过与存储节点read quorum,即可读到最新数据,并得到VDL以截断后面的日志
- 由于LSN与VDL有差值限制,undo操作不会很多,且可在后台进行
5. 集成
整体在云上集成的架构如下所示:
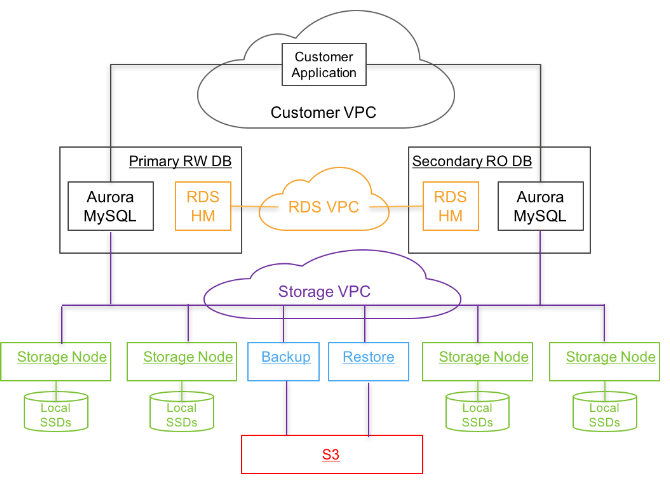
- 应用层:部署应用程序,与数据库实例交互
- 数据库实例层:部署数据库实例(Aurora MySQL)
- 数据库实例包含一个主实例(读写)和多个从实例(只读),位于同一个物理区域,跨AZ部署
- 使用RDS管理元数据,每个数据库实例部署一个RDS HM,监控集群健康度,确定实例是否要切换或重建等
- 存储层:部署存储节点
- 存储节点尾与同一物理区域,跨AZ部署(如至少跨3个AZ)
- 其中部分节点和S3相连,后台备份数据,必要时还原数据
- 使用Amazon DynamoDB持久化存储配置、元数据信息、S3备份信息
- 所有关键操作都会被监控,若性能和可用性不达标,则会触发警报
6. 总结
本文的主要贡献点在于:
- 重提“数据库即日志”的观念
- 基于quorum机制,和下放redo日志处理,使用“计算和存储分离”的架构,减少I/O开销,提高吞吐,可用性增加,且能保证一致性
- 提出分片存储,降低存储层恢复的时间,提高可用性
- 大部分关键操作异步化、后台化,极大降低前台任务的延迟
