1. Introduction
Bigtable是一个可扩展、高性能、高可用的分布式数据库。本文主要从下面几个角度说明Bigtable原理:
- 数据模型
- API
- 依赖组件
- 实现
- 优化
- 教训与总结
2. 数据模型
一个Bigtable集群由多个Bigtable进程组成,维护多个表。
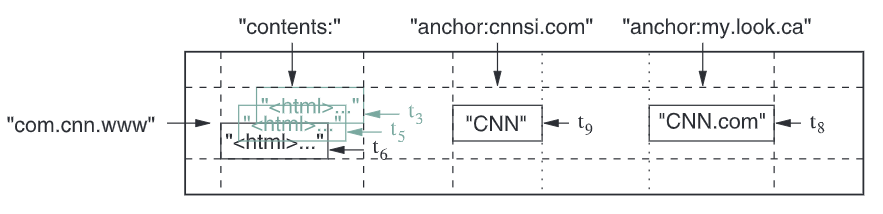
而一张表是一个稀疏、分布式、持久化的多维有序表,维护一个三维的映射,即Cell(表项): \((row:str, coloum:str, time:int64) \rightarrow str\)
-
行:
- 表项按行字典序排序
- 单行的读写是串行化的,即行级事务(类似MongoDB,不支持多行事务)
- 表会切割成多个连续组成的Tablets,用作分片(横向扩展)和负载平衡的基本单位
-
列
- 若干个列会组成一个列族
- 一个列名命名为
<family>:<qualifier>,<family>需要提前声明,<qualifier>可创建任意个
- 一个列名命名为
-
一个列族的数据类型一般一样,且同个列族的列数据会一起压缩
- 访问控制和数据统计在列族层级实现
- 若干个列会组成一个列族
-
时间戳
- 同行同列支持保存多个版本的数据,以时间戳区分
- 时间戳可设置为写入时间,也可自行设定,但需要确保不冲突
- 同行同列下,数据按版本降序排序
- 可设置只保留最近$n$个版本的数据
3. API
API提供CRUD,控制表及其结构,控制集群元数据等功能,此外也支持单行事务、脚本执行(基于Sawzall语言,可用于数据转换、过滤和汇总)。

4. 组件依赖
Bigtable需要依赖:
- GFS:存储日志和数据文件
- SSTable(Sorted String Table):文件存于该数据结构
- 它是持久化、已排序、不可变的键值映射
- 支持单个和范围查询
- 内部一系列数据块,并包含块索引,操作通过索引进行(与LSM-Tree类似)
- Chubby:高可用持久化的分布式锁服务,用于
- Bigtable副本的选主,任何时间下至多1个
- 存储Bigtable的数据引导指令
- 查找Tablet节点,以及节点失效后的处理
- 存储Bigtable的表结构信息
- 存储访问控制配置
5. 实现
包含3个主要部分:
-
客户端库
交互读写,大部分客户端仅和Tablet节点交互
-
一个主节点
用于分配Tablets到Tablet节点,检测Tablet节点的加入和离开,平衡Tablet节点的负载、回收GFS文件、处理表结构的修改
-
多个Tablet节点
存储和管理Tablets,处理读写请求,当Tablet过大则会分割
一个Bigtable集群有很多表,每个表包含多个Tablet。初始下一个表只有1个Tablet,当数据量增长时,则会分割。
5.1. Tablet的位置
Tablet位置信息使用三层结构存储(类似B+树):
-
第一层:存储于Chubby,包含了Root Tablet位置信息
-
第二层:Root Tablet(
METADATA的第一个Tablet),存储了METADATA表其它Tablet的位置Root Tablet有特殊处理:它永远不会被分割
-
第三层:
METADATA表其它Tablet,存储了所有表的Tablet位置
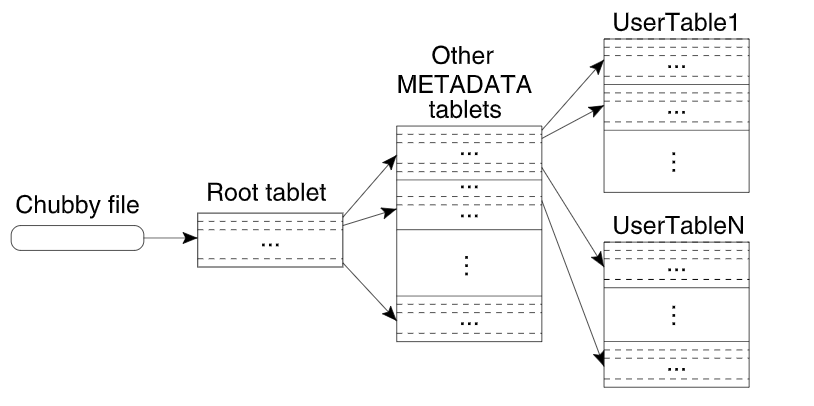
METADATA表:
- 每一行的$row$:目标Tablet所在表的标识符+Tablet最后一行
- 每一行大约1KB,128MB限制下三层架构可以定位$2^{34}$个Tablet
- 还存储了其它信息,如Tablet事件日志等
- 地址信息存于内存中
客户端定位Tablet:
- 从上到下递归查找,并缓存结果
- 若数据过期,则需要重新查找遍历来更新
- 预取Tablet地址来减少访问开销
5.2. Tablet分配
分配Tablet由主节点完成:
- 首先主节点需要追踪Tablet节点状态,这需要利用Chubby来了解
- Tablet节点在Chubby上有唯一文件
- Tablet节点启动时会尝试获取Chubby上该文件的互斥锁
- 主节点会监听这些文件:若获取到锁,则Tablet节点加入;若释放锁,则Tablet节点离开;若锁被删除,则Tablet节点会自动关闭
- 然后要分配Tablet到唯一的Tablet节点
- 主节点向Tablet节点发送载入请求,并需要确认
- Tablet节点只会接收主节点的分配请求
- Tablet节点不负责某个Tablet时,会通知主节点
- 当Tablet节点失效时,对应的Tablet需要重新分配
- Master尝试获取Chubby上对应Tablet节点的文件互斥锁
- 获取成功后,删除该文件,保证Tablet节点下线
- 之后重分配Tablet
- 当主节点失效时,需要新的主节点进行恢复,流程如下
- 新主节点获取Chubby上唯一的
master锁,保证有且只有一个主节点 - 新主节点在Chubby上搜索所有活跃的Tablet节点
- 向每个活跃的Tablet节点询问节点被分配了哪些Tablet,并告知它们主节点已变更
- 扫描
METADATA表以得知总共有哪些Tablet,任何没分配的Tablet都会重新分配
- 新主节点获取Chubby上唯一的
而有一些其它操作,会稍微复杂一些:
- 当
METADATA有Tablet没被分配:- 在扫描
METADATA前,询问Tablet节点时,若发现Root Tablet没分配,则主节点会将其分配 - 当Root Tablet表分配后,就得到
METADATA表其它Tablet的名字了
- 在扫描
- 表创建/删除,合并/分割Tablet事件,主节点都能追踪
- Tablet分割复杂一些:
- Tablet节点分割完后,先在
METADATA表记录新的Tablet信息,然后通知主节点; - 若通知不到主节点,主节点要求Tablet装载被分割的子Tablet时会发现新的Tablet,Tablet服务器会发现所需装置的Tablet不完整,然后会重新向主节点发送通知
- Tablet节点分割完后,先在
- Tablet分割复杂一些:
5.3. Tablet服务
一个Tablet的结构如下图所示:
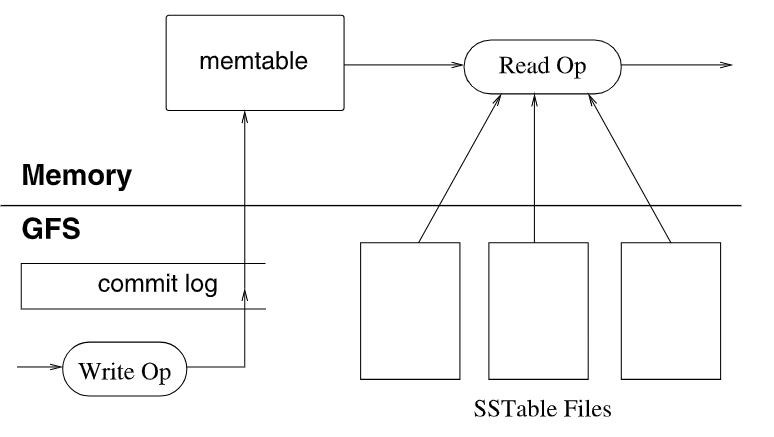
- 持久化信息存于GFS中,使用GFS进行冗余,数据包括:
- commit log(可认为是WAL)
- SSTable(数据文件)
- 最近的变更数据存于memtable,它位于内存,且有序
写操作:
- 首先写WAL,即commit log
- 然后将更新的数据写入memtable中,较早的更新会被持久化到一个个SSTable文件中
读操作:
- 首先进行权限检查
- 先从memtable找,若找不到再从SSTable中找
载入操作:
- 首先从
METADATA表中获取Tablet的SSTable和commit log - 然后根据commit log恢复出memtable
5.4. 空间压缩
Tablet存储类似于LSM Tree: memtable和SSTable都是不可变的,只能进行追加。因此需要压缩操作,以限制空间占用。
-
Minor compaction
memtable不够用时,它首先会被冻结,然后创建一个新memtable,冻结的memtable成为SSTable写入GFS,这里涉及一次记录合并
-
Merging compaction
SSTable会越来越多,会导致读取时需要扫描更多的SSTable,因此需要减少SSTable文件数。Bigtable会周期进行合并,将多个SSTable合并成一个。
-
Major compaction
特殊的Merging compaction,周期执行,会移除由于变更而无效的条目
SSTable存于GFS,而为了提高局部性,压缩后的SSTable会在本地磁盘保留一份,以提供更快的数据访问。
5.5. 表结构管理
表结构存于Chubby,且有序存储。
Chubby类似于ZooKeeper,主节点可以访问Chubby以管理表结构。类似于ZooKeeper,由于其强一致性保证,当Chubby上存储表结构改变时,其它Tablet节点都能收到变更通知。
6. 优化
6.1. 局部性群组
客户端可以将多个列族组合成局部性群组。
压缩时,每个局部性群组有一个单独的SSTable。所以,将不会一起访问的列族分割成不同的局部性群组,可以提高读取的效率。
此外,局部性群组还有其它参数设置,如可设置将一个局部性群组全部存储于内存,因此不需访问硬盘(METADATA表就是这么设置的)
6.2. 压缩
每个局部性群组可设置是否压缩,以及压缩格式。其优势在于:
- 节省空间
- 读取数据,进行解压缩时,只需解压缩表的一部分数据,提高读取速度
6.3. 缓存以提高读性能
由于Bigtable存储方式等效于LSM Tree,它写快(全是顺序写),但是读取慢(需要扫描多个SSTable)。因此需要提高读性能。
最先想到的办法就是读缓存。
读缓存采用二级缓存策略:
- 第一级:Scan cache,缓存从Tablet获取的K-V对
- 第二季:Block cache,缓存从GFS读取的SSTable Block
对于读刚刚读过的数据,Scan cache有效;对于读刚刚读过的附近数据,Block cache有效。
6.4. Bloom Filter
Bloom Filter原理不再叙述。它可以明确知道哪些数据不存在,这样就可以不用访问磁盘,且内存代价小。
一般,使用Bloom Filter查询SSTable是否包含了特定行和列的数据。
6.5. 提交日志的实现
由于写入需要写commit log,因此这也是优化点。
首先,对于每个Tablet节点,所有的Tablet写入同一个commit log中,以减少寻址次数,提高写效率。
然后,由于一个commit log有多个Tablet信息,当恢复时,一些Tablet不属于自己管理,造成恢复时需要读全部的日志。解决方式如下:
- Tablet节点向主节点发送信号,
- 主节点发起对commit log的并行排序
- 将日志分割成64MB的段
- 不同的Tablet节点对这些段进行并行排序,按照$(table, row, log_seq_num)$排序
- 排好序后,Tablet读取所需的数据即可
最后,为了避免写日志的颠簸,设置写日志线程有2个,其中只有1个工作,每个线程对应有一个日志文件。当写入慢时,切换线程。
6.6. 加速Tablet恢复
当把Tablet从一个节点转移到另一个节点时:
- 源节点对该Tablet做一次Minor compaction,消除日志文件未归并的记录
- 源节点停止对该Tablet服务
- 源节点再次对该Tablet做一次Minor compaction,消除第一步压缩时产生的未合并的记录
- 源节点卸载该Tablet,新节点可加载该Tablet,且不需要从日志中恢复
6.7. 利用不可变性
由于SSTable文件是不变的,因此可以利用其不变性:
- 记录删除,只需要标记即可,之后后台就可以进行垃圾回收
- 分割Tablet时,不需要创建新的SSTable集合,只需要共享原来的即可
而memtable是唯一一个并发读写的可变数据结构,为了减少读竞争,使用copy-on-write机制。
7. 总结
以上就是Bigtable的设计,可见都是一些目前看来非常优秀的设计,非常值得我们借鉴和学习,如:
- 简单的数据模型
- 基于LSM的存储
- 基于Chubby的集群管理(类似的有ZooKeeper)
- 基于Tablet的数据分片和负载均衡
- 多种优化(如压缩、缓存、顺序读写)
当然这些方面底层的细节问题还是极多的,但是有了非常好的优化方向。
