1. 定义
before-or-after atomicity是一个更加通用的(相对于串行化)并发操作限制,使得对相同数据的并发操作不会互相干扰。
其定义如下:
并发操作满足before-or-after属性,需要:从调用者的角度看(假定有A和B),它们调用的结果与串行执行(A完全在B前,或B完全在A前)一样。
相比于串行限制,before-or-after的并发操作并不需要知道其它操作是否访问的共享数据(虽然可以显式加锁保证),因此并发操作的协调会更加困难。本文会介绍一些机制,它们是自动的、隐式的,确保这些共享数据能够正确处理。
2. 正确性和串行化
2.1. 例子
文中提及了一个例子,并发执行下面的操作:

T1: TRANSFER(A, B, $10)T2: TRANSFER(B, C, $25)
注意,
X = X + Y操作包含多条读写指令,至少涉及对X的1次读和1次写。
为了保证正确,只需要下面2个操作原子化,不需要T1和T2原子化:
T1: credit_account <- credit_account + amountT2: debit_account <- debit_account - amount
2.2. 正确性和串行化
协调的正确性:并发执行的结果与它们按某个序列串行执行的结果一致。
正确性可见下图示意,即最终状态符合任何一条路径即可(不需要追踪中间状态,只需最后状态满足即可)。所以协调的正确性,保证了串行化。
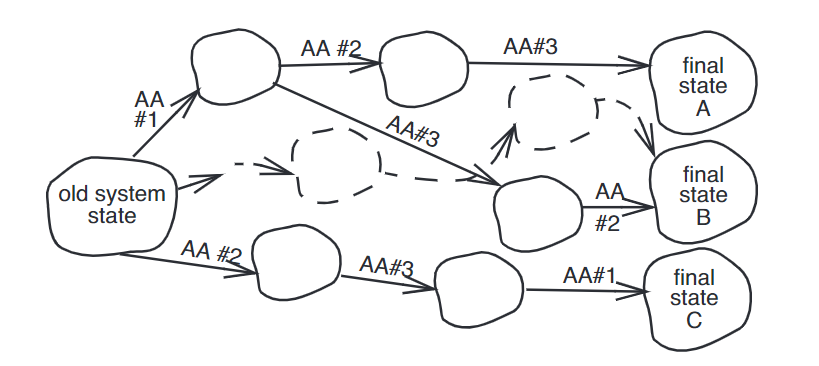
3. 保证Before-or-After Atomicity
上锁是最简单的一个方式。
使用锁保证正确性需要满足下面的步骤:
- 指定上锁规则,指定哪些需要上锁、何时上锁
- 推理,保证这个规则满足并发的before-or-after属性
- 实现一个lock manager,在程序过程中上锁与解锁
对于上锁规则,有很多,这里主要介绍下面几个:
- 全局锁
- 简单锁
- 2PL
3.1. 全局锁
全局锁很简单,就是系统全局一把锁,整个系统同一时间只能执行一个事务。
但是这把锁的粒度太大,极大限制了并发度,因此不常用。
优化点是锁粒度:
- 粒度小:并发度上升,但处理锁的时间上升
- 粒度大:并发度下降,但处理锁的时间下降
我们的目标是获得性能的提升大于处理多个锁的开销
3.2. 简单锁
包含2个规则:
- 每个事务操作共享对象前,先获取该对象的锁
- 每个事务只能在下面的情况下,才能释放锁
- 执行完最后一个更新,并提交
- 完整地执行回滚,并中止
在实现lock manager的时候,可以:
- 在
begin_transaction时,传入需要上锁的对象集合(lock manager可等待它们都可用),强制执行简单锁 - 在所有读/写调用中,将lock manager插入进去,验证它们是否引用了锁集合的变量
- 拦截
commit和abort指令,lock manager自动释放锁
虽然它比全局锁有更高的并发度(锁粒度降低),但是依旧有一定的缺点:因为需要对每个读和写对象获取锁,尤其是读取操作会获取过多的锁,造成性能影响。
3.3. 2PL
2PL应用于大多数的数据库系统。
2PL的规则是:
- 可在事务执行过程中获取锁
- 在lock point后,只需要之后不再访问它,就能释放锁(lock point: 第一次获取所有锁的时刻)
2PL有2个phase:上升期(锁获得数量上升);下降期(锁逐步解锁)。
它在lock point中保证了before-or-after性质。
在实现lock manager的时候,可以:
- 在所有读/写调用中,将lock manager插入进去,若第一次访问对象,尝试获取锁
- 和简单锁一样,在
commit,abort时,释放所有锁
