1. 简介
本文介绍一个键值存储系统FASTER,它有下面的特点:
- 适用于单点读、盲目更新和读-修改-写操作
- 有一个缓存高度优化的散列索引,并和hybrid log(并行的日志结构的存储,跨内存和磁盘)结合
- 支持热点数据的in-place更新
由于上面的特性,它适用于大数据平台(如流式计算)的状态存储。
1.1. 已有解决方案
状态存储有下面的特点:
- 状态数量大
- 更新操作多
- 有热点数据,需要对此有强局部性
- 操作都是单点对,很少有范围查询
- 状态更新能够随时用于后续的离线分析
已有的解决方案有:
- 纯内存的Intel TBB Hash Map:其优化了并行操作且支持in-place更新,但开销昂贵,难以利用资源,数据恢复困难
- 支持存盘的键值存储:如Bw-Tree、LSM-Tree、RocksDB,但它针对盲更新、读和范围扫描优化,对单点操作和读-修改-写的优化不足
- 存储于缓存系统:如Redis, Memcached,但性能不行且依赖外部系统
1.2. 引入FASTER
因此引入了FASTER,兼具1.1.的特性。本文贡献点为:
- 基于标准的epoch-based同步,构建一个框架,该框架通过触发器,懒惰传播全局更新到所有的线程
- 引入一个并行、无锁、可调整大小、缓存友好的散列索引,它可作为内存式的键值存储
- 引入Hyprid Log:它是日志结构的,不仅支持RCU追加更新,且对于热点数据支持in-place更新,此外可以通过内存中的内容进行整形来充当有效的缓存
2. 系统概览
FASTER是一个无锁的并行KV存储,它基于无锁操作(CAS等)和下面提及的epoch-based同步框架,并以此实现in-place更新
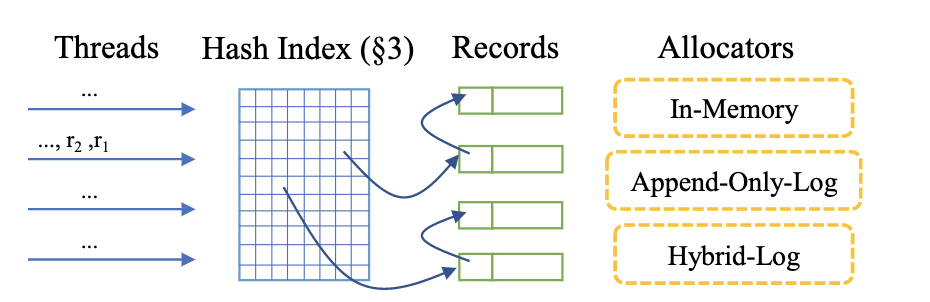
2.1. FASTER架构
架构如下图所示:
- 散列索引:
- 它是连续的一个数组,每个单元等于cache-line的大小
- 维护了指向数据项的指针(数据项通过链表连接)和元数据,但索引项不维护键(减少索引的内存轨迹、索引和数据项分离/解耦)
- 分配器:用于保存和管理数据项,包括内存型、追加日志型、Hybrid Log,后面会详细讲这些类型的分配器
关于分配器的对比,可参考下表:

2.2. 用户接口
这里包括:
Read:读一个键的值Upsert:替代(若存在)或插入(若不存在)一个键值对RMW:基于初始值(可以为空,也可以提供一个初始值),更新一个键的值,可以认为该操作可合并(即操作的数据是CRDT)Delete:删除一个键值对
有些操作并不会立即完成,而是返回PENDING状态。线程会周期调用CompletePending来完成这些PENDING操作。这些和Epoch保护框架有关,后面会说。
2.3. Epoch保护框架
FASTER中的线程一般都是独立运行,通常不需要同步操作。
因此多个线程需要对一个共同的机制达成共识,所以本文扩展了多线程epoch保护机制,使其对任意全局操作都能进行懒惰同步。
-
epoch基础:
系统维护一个原子全局计数器$\bold{E}$,以记录当前epoch,它可被任何线程递增。
每个线程维护一个thread-local版本的$\bold{E}$,即$E_{T}$,它会周期性刷新。而$E_{T}$保存在一个共享的epoch表中,每个线程使用1个cache line大小。
当epoch $c$是安全时,任意线程的$E_{T} \gt c$。而系统会维护一个最大的安全epoch $\bold{E_{s}}$。
因此有$\bold{E_{s}} \lt E_{T} \le \bold{E}$。
-
触发器动作:
当epoch变得安全时,框架可以通过触发器执行任意的全局操作。
当增加当前epoch时(如从$c \rightarrow c+1$),线程可以绑定一个回调,当某个时刻$c$安全时,可以触发该操作。这个绑定维护在drain-list列表中,每一项为
(epoch, action)。该表用小数组实现,并用CAS保证线程安全。当前epoch改变时,$\bold{E_{s}}$会被重新计算,而该表会被扫描,回调会被触发。
2.4. 使用Epoch保护框架
该框架暴露给线程$T$的接口有:
Acquire:添加$E_{T}$项到epoch表中,并更新$E_{T}$到$\bold{E}$Refresh:更新$E_{T}$到$\bold{E}$,更新$\bold{E_{s}}$到最大安全epoch,并扫描drain-list触发回调BumpEpoch(Action):将$\bold{E}$从$c$递增到$c+1$,并添加(c, Action)到drain-listRelease:将$E_{T}$项从epoch表中移除
本文用这个框架进行系统协调操作,例如内存安全的垃圾回收、索引大小调整、环形缓冲管理与页刷新、共享日志页的边界管理、检查点。有了该框架,线程可以不需要使用锁,并发访问共享内存数据。
2.5. FASTER线程的生命周期
本文用该框架实现了一个计数存储。FASTER线程:
- 调用
Acquire注册$E_{T}$ - 处理请求(调用
BumpEpoch(Action)),并每隔一定数量的操作后调用Refresh以更新$E_{T}$和$\bold{E_{s}}$,并扫描drain-list以触发CompletePending来完成请求 - 最后调用
Release结束生命周期
3. FASTER的散列索引
该组件是FASTER的关键部分,它是无锁、并行、可扩展且可调整大小的散列索引。
3.1. 索引组织
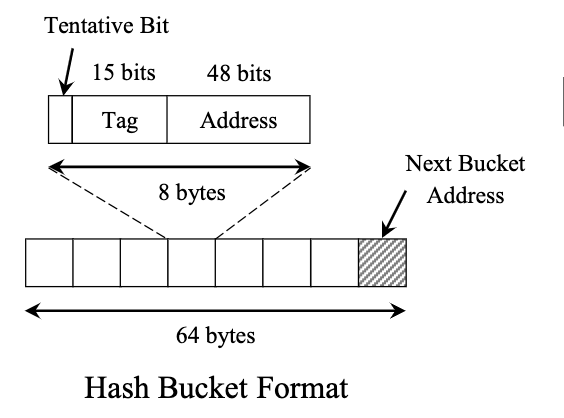
FASTER索引是一个连续数组,存储在内存中。它共有$2^k$个散列桶,每个散列桶大小等于一个cache-line,操作的时候直接读取整个散列桶(以64-bit机器为例,一个索引项大小为64字节):
- 7个8字节:用于存储索引项
- 剩下1字节:溢出的散列桶指针(溢出的散列桶的格式和普通散列桶一样)
而每个索引项的格式如下(以x86为例):
- 1位:tentative bit,用于保证插入等CAS操作等安全性(无锁链表也采用了该思路)
- 15位:tag,用于存储散列值的$k$ ~ $k+15$位
- 前$k$位用于定位哪个散列桶,它也被记为散列索引的偏移量
- 使用tag可以提高散列的分辨率,它大小可以调整到更小甚至没有
- 48位:键值对指针
3.2. 索引操作
每个(offset, tag)都有一个唯一索引项,它指向了一个记录集合,这些记录的键散列值和(offset, tag)匹配。
a) 查找和删除索引项
查找很简单:
- 先计算散列值
- 根据$k$位散列值,找到散列桶
- 读取整个散列桶,扫描所有索引项,找到匹配的即可
删除也很简单,在查找的基础上,利用CAS将索引项置0。
b) 插入索引项
使用两阶段插入算法,使用CAS,并引入了tentative bit。
对于每个线程:
- 扫描整个散列桶,要找到一个空索引项,并设置索引,置tentative bit为1
- 重新扫描整个散列桶,检查是否有索引项有相同的tag且tentative bit为1,若有则需要回滚重试
- 置tentative bit为0
3.3. 调整索引大小和检查点
索引是支持扩充的(类似rehash)。扩充利用了Epoch保护框架和状态机转换,让扩充变得安全且开销低。
而有趣的是,即使存在并发操作,这些无锁操作也始终将索引保持在一致的状态,因此索引可以执行异步的模糊检查点操作,不需要获取读锁,从而简化了恢复操作。
4. 内存键值存储
如2.1.节所述,键值对记录用一个链表存储,链表头(也即索引)指向是最新的键值对。
每个键值对记录的格式如下图所示:
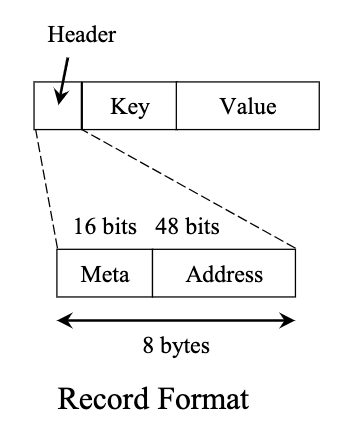
而底层的内存分配器比较简单,使用的是现成有的,如jemalloc。
内存存储的操作
不同线程的操作安全性基于Epoch保护框架,并发控制(使用用户指定的逻辑)的粒度在键值对的级别。
下面是各个操作的说明。
a) 读
如3.2.a)所述,根据散列值找到索引项,扫描整个链表找出匹配键值对即可。
b) 更新和插入
首先按3.2.a)所述,先找索引项,若没有则按3.2.b)进行二阶段创建,然后直接返回即可。
然后扫描整个链表:
-
若记录存在,则执行in-place更新
只要线程不刷新epoch,那么就可以保证对记录的内存位置访问
-
若记录不存在,则创建一项,使用CAS放置到链表头
c) 删除
首先也按3.2.a)方式查找,若找到则用CAS方式将键值对从链表中移除。若链表被删完,那么根据3.2.a)同样要删除索引项。
而删除后,对应的内存不能立刻还给分配器,因此使用Epoch保护框架解决问题:每个线程维护一个线程内列表,存储(epoch, address),当epoch安全后,即可将address的地址返回给内存分配器。
5. 追加式日志存储
这里和4一样,底层的存储是append-only的,也使用了现有的组件(如LSM-tree)。
实测下来它的吞吐并不好,且多线程扩展性不好,但它的设计思路对构建Hybrid Log有很大的帮助。
5.1. 逻辑地址空间
不同于内存存储,当使用追加日志存储时,存储的是逻辑地址,它横跨内存和二级存储。
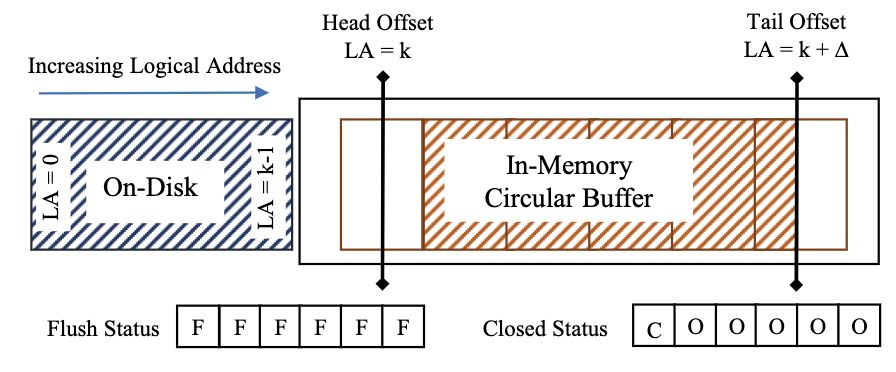
逻辑地址空间使用两个偏移量维护:
- 尾偏移量(tail offset):它指向日志尾的下一个空闲地址,地址用2个字段描述:页编号、偏移量
- 分配器对偏移量执行CAS分配,若该页满,则递增页编号并重置偏移量;其他线程看到这个情况后会等待偏移量合法,然后重试
- 头偏移量(head offset):它指向内存中最低的可用逻辑地址
- 它和尾偏移量保持大致相等的滞后,等于日志在内存中可用的大小
- 头偏移量只会在尾偏移量跨越页边界时才会更新
上述两个偏移量指向的位置位于一个环形缓冲区中:它是一个数组,包含多个固定大小的页帧,每个页帧大小为$2^F$字节。
5.2. 环形缓冲管理
我们需要使用无锁的方式将环形缓冲的数据刷盘,因此这里维护2个状态数组:
flush-status数组:追踪该页是否已经刷入磁盘closed-status数组:追踪该页是否可以清理以重用
当日志尾进入新页$p+1$时,调用BumpEpoch(Action),动作为“发起异步请求,将页$p$刷盘”。当刷盘完成后,设置该页的flush-status为flushed。
由于头偏移量跨越页边界时,会调用
Refresh,因此可以保证前页$p$已经完成,刷盘是安全的。
当日志尾不断增加时,我们需要将环形缓冲头移除,以便于日志尾重用。当日志头需要往前时,先将头偏移量递增,然后调用BumpEpoch(Action),动作为“设置该页的closed-status为closed”。
当该
epoch安全时,所有线程都会看到头偏移量递增(多个线程肯定调用了Refresh,drain-list回调被触发),就不会访问旧页了。注意,在递增头偏移量时,必须保证移除的页已经完成刷盘。
5.3. 追加日志存储的操作
a) 盲更新
直接追加键值对到日志,然后使用CAS更新索引,若失败则标记追加到键值对为“无效”(使用键值对的头几位),然后重试
b) 删除
插入一个墓碑记录(同样适用键值对的头几位),然后发起日志垃圾回收
c) 读与读-修改-写
和4.a)类似,不过更新时,需要追加日志并连接到后一个键值对记录(修改链表),然后CAS更新索引项(失败时同a))。
这里涉及到逻辑地址的读取:
-
先判断地址是否超过头偏移量,若超过,则直接从内存读取,否则向磁盘发起异步读请求
-
读取时,不读取整个页,而是只读取记录本身
由于这里涉及到很多异步I/O,因此每个FASTER线程会维护一个队列,保存已经完成的I/O操作,当周期的CompletePending被调用时,会将这些已完成的操作弹出并执行下一步的操作。
6. Hybrid Log存储
追加日志虽然能容纳更多的记录,但每次更新开销很大,都要涉及:原子尾偏移量的递增(用于新记录的创建)、数据的拷贝、原子修改键值对链表指针、原子修改散列索引。此外,日志会不断递增时,导致磁盘I/O瓶颈。
因此需要对追加式日志引入in-place更新功能,解决上面的问题,它有以下优点:
- 常更新的记录更有可能出现在上层缓存中(局部性强)
- 更新大键值对更加有效率,因为不需要拷贝整个记录,也不需要修改键值对之间的链表
- 不需要更新散列索引
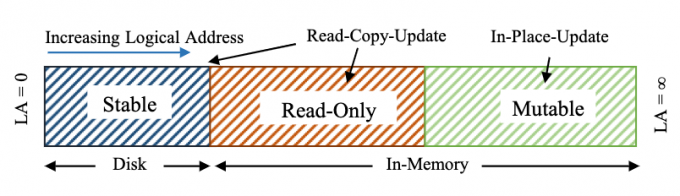
6.1. Hybrid Log介绍
Hybrid Log结合了in-place更新(内存)和日志结构(磁盘),并提供无锁并发访问的支持。此外,内存中的数据可作为热点数据的缓存,提高了局部性。
Hybrid Log地址空间分为3个部分:
- stable region:位于磁盘
- read-only region:位于内存,这个区域的键值对是只读的,即不能in-place更新,而使用RCU(读取-拷贝-修改,然后追加到mutable region)
- mutable region:位于内存,这个区域的键值对可以in-place更新
Hybrid Log地址空间使用3个偏移量管理:
- 尾偏移量、头偏移量:同5.1.
- 只读偏移量:位于尾偏移量和头偏移量之间,分割read-only region和mutable region
- 和头偏移量类似,它和尾偏移量也保持大致相等的滞后,更新也在尾偏移量跨越页边界时进行
- 只读偏移量往前时,其后面的数据可以刷盘,刷盘完毕后即可从环形缓冲中移除,管理方式和5.2.所述的类似
- 只读偏移量充当了刷盘点,只读区域是可以刷盘的,但该区域数据存在时,还是能充当一个二级缓存,这部分详细会在后面讲

6.2. 丢失更新的异常
考虑这样的情况:
- 键值对
(k, v)位于只读偏移量r1后,偏移量记为l - 线程$T_1$和线程$T_3$同时获取了
l - 线程$T_1$比较
l < r1,准备执行in-place更新 - 线程$T_2$执行了其他更新操作,将尾偏移量往后递增,并将只读偏移量递增到
r2 - 线程$T_3$比较
l < r3,执行RCU,拷贝并追加了(k, v + 1) - 线程$T_1$才开始执行in-place更新,将
l上的(k, v) -> (k, v + 1),但实际上应该为(k, v + 2),更新丢失
上述问题出现是因为只读偏移量被修改,但对其他线程不可见,线程读到了旧的只读偏移量,导致了更新策略的错误。
解决方式是引入“安全只读偏移量”,通过触发epoch action让该偏移量对所有线程可见:
-
它追踪所有线程可见的只读偏移量,取其中最小的
-
使用Epoch保护框架进行更新:
-
当只读偏移量更新时,调用
BumpEpoch(Action)注册回调,更新安全只读偏移量到新的值 -
其他线程若跨越了上面调用时的epoch,则会触发安全只读偏移量的刷新,那么安全只读偏移量就可见了
-
-
当键值对地址小于“安全只读偏移量”,则需要执行RCU更新
引入了“安全只读偏移量”后,在一个线程视角中,就引入了第4个区域:fuzzy region,该区域是安全只读偏移量到只读偏移量的区域。
如下图所示:
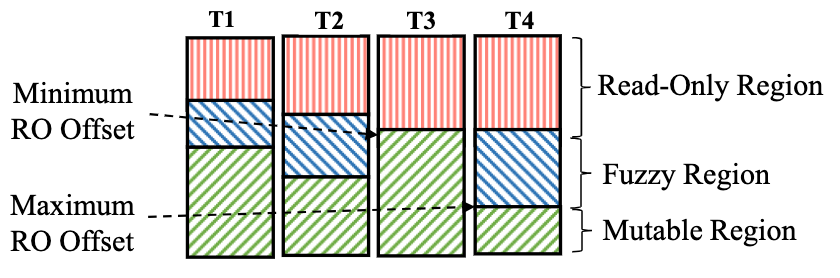
- 蓝色框框中是每个线程视角中的fuzzy region
- 下面:每个线程视角中的只读偏移量
- 上面:每个线程视角中的安全只读偏移量
- 全局的安全只读偏移量,取的是每个线程视角中只读偏移量的最小值
- 视角会有滞后,导致每个线程中的“安全只读偏移量”和“只读偏移量”会有滞后,因为线程可能没有及时刷新,例如$T_4$是刚刷新过的,而$T_3$没有及时刷新
6.3. Fuzzy Region
该区域下不同的写入操作会有不同的动作,如下表所示:

对于mutable region的部分,更新操作都使用in-place更新;而无效部分,直接追加新记录。
而其他部分:
- 盲更新:不需要读旧值,因此只要小于只读偏移量,就直接RCU追加新纪录到尾部
- 读-修改-写:这里不能直接执行RCU,因为可能会丢失更新(6.2.),因此:
- 若小于头偏移量:发起异步磁盘I/O请求,读取旧值,然后进行下一步
- 若小于安全读偏移量:将更新操作随着上下文放入队列中,延迟执行,执行的是下一步
- 若小于只读偏移量:创建新的记录到尾部
- CRDT:由于更新可合并,所以直接创建一个delta记录到尾部,并将其和前值用链表链起来即可,读取时扫描链表即可得到结果
6.4. Hybrid Log分析
a) 缓存行为和日志整形
FASTER的Hybrid Log缓冲实际上是一个新的缓冲替换协议,它很像Second-Chance FIFO协议。而它和其他传统协议相比,做到了更细粒度的控制(键值对级别),且并没有过大的开销。
而由于上面的缓存特性,在有热点且写高负载的情况下,日志的大小不会很快的增加,因为热点数据在内存中in-place更新。
b) Hybrid Log不同Region的大小
确定mutable region和read-only region大小很重要:
- 更小的read-only region/更大的mutable region:更新性能更高(因为更容易in-place更新),但热点数据更容易被刷盘(假如一段时间内没访问)
- 更大的read-only region/更小的mutable region:更新性能相对差,日志会更快增长(因为更容易RCU),但由于RCU复制,减少了内存中缓存的大小
实验得到mutable和read-only在9:1的比例时,性能最好。
6.5. FASTER的恢复和一致性
宕机时,Hybrid Log中没刷盘的部分会丢数据。一种解决方式是使用WAL,并周期形执行内存中的模糊检查点。
但WAL会引入性能瓶颈,因此这里不会使用它。本文提供了一个思路,但没有实现:让Hybrid Log充当WAL,并在有限的时间窗口中延迟提交更新,从而允许in-place更新。
FASTER的检查点
FASTER为检查点提供了思路,但没有完全实现。
FASTER会有一个后台检查点线程,它会异步读取散列索引,不需要读锁,并写入检查点文件。不过由于并发更新的存在,这个检查点是“模糊”的。
具体这么做:
-
开始($t_1$)和结束($t_2$)时,分别记录尾偏移量
恢复时,扫描这个时间区间的偏移量范围,恢复散列索引到时间点$t_2$
-
移动只读偏移量到$t_2$对应的偏移量,并将前面的数据刷盘,从而获取$t_2$前的日志检查点
这些检查点是增量式的
7. 评估
这里略,看论文即可。
8. 总结
本文主要的创新点有:
- Epoch Protection Framework,感觉本质上使用计数器给并行操作指定了一个排序,再利用CAS保证线程安全
- 散列索引是cache-friendly,而环形缓冲也是适配了磁盘和内存分页特性
- Hybrid Log在追加日志的基础上,引入了in-place更新的功能,提高了性能,其核心感觉还是在对环形缓冲区分了可变和不可变部分,而缓冲同样起到了缓存作用,降低了磁盘的负载
而Hybrid Log相关的算法张贴如下:




