1. 简介
本文介绍的是FishStore,它是一个存储层,有下面的特点:
- 并发无锁
- 基于动态注册的预测数据子集,构建多链散列索引,使得数据“立刻可用”
1.1. 之前的解决方案
当大数据进来时,通常有下面的解决方案:
- 先保存原始数据,然后周期跑批使得数据可用:高CPU开销,慢
- 接受数据后先进行完全解析,然后将其存储到数据库,或更新索引:完全解析,数据库加载,索引构建也很慢
而目前较新的方案有
- 利用如Mison, Sparser, FAD.js等工具,只解析一部分字段,从而提速:但通常需求要parse所有字段
- 在1的基础上,工具这一部分字段,构建索引:但负载转移到索引构建上(如RocksDB, Bw-Tree等)
- 使用较新的键值存储,如FASTER:但它只针对单点操作优化,对扫描等范围查询支持不好
1.2. 引入FishStore
FishStore是一个新的存储层:
-
支持灵活格式的数据
-
将快速解析和基于散列的子集索引结合,提供快速解析和抽取指定字段的能力
-
支持动态注册预测子集函数(PSF),允许用户获取所有满足给定PSF和值的记录
PSF:一个函数$f: R \rightarrow D$,基于给定的感兴趣的字段集合,将所有记录$r \in R$转换到值$d \in D$
-
基于PSF的索引效率高且扩展性好,并支持多种类型的查询(单点、联合、选择、前缀、预定义范围查询等)
1.3. FishStore组件
主要有2个组件:
-
数据收集和索引:
数据并发进入一个不可变的日志,并维护一个散列索引。对于每个PSF $f$和非空值$v \in D$,创建一个索引项$(f, v)$,指向所有匹配的记录,以一个链表组织。而一个记录往往存于多条链表中,因此这里设计了新的带有PSF注册信息的无锁散列索引和多散列链多无锁数据收集。
-
子集检索
FishStore支持匹配PSF的扫描操作,并返回匹配的记录。FishStore不会为旧数据构建索引,因此检索时,将索引查找和日志扫描结合在一起。
FishStore的数据组织形式是面向行的,带有记录头信息。
2. FishStore概念
FishStore的核心即PSF(Predicated Subset Function),它按照某些相似的特性,在逻辑上将记录进行分组,以供后面的检索。
PSF:
给定源数据集$R$,PSF是一个函数$f: R \rightarrow D$,它将$R$中有效的记录,基于$R$中感兴趣的字段,转换成$D$中特定的值。
PSF可以是用户任意指定的函数,例如投影$\Pi_{C}$等。
PSF可用于很多种查询:
- 特定分析:$f$可以是选择函数$\sigma_{C}$,得到了过滤过的数据子集
- 回溯查询:每隔一段查询数据,由于注册$f$,索引会被构建,数据进来后会被索引,因此加速后面的查询
- 单点查询:$f$只要指定某个字段,不做任何改变,让其索引它的所有值即可
- 流式查询:注册$f$后,数据进来,索引构建,构建时,将记录输出到下游
记录属性
假如一个记录$r \in R$拥有属性$(f, v)$,那么有$f$是一个$R \rightarrow D$的映射,且$f(r)=v \in D$。
3. 背景:索引和解析
3.1. FASTER
FASTER的介绍可看:这里,它主要的特点是:
- 存储使用Hybrid Log,兼具追加日志和in-place更新的功能
- 基于Epoch保护框架和CAS等无锁操作,以保证线程安全
下图是FASTER大致的存储架构:
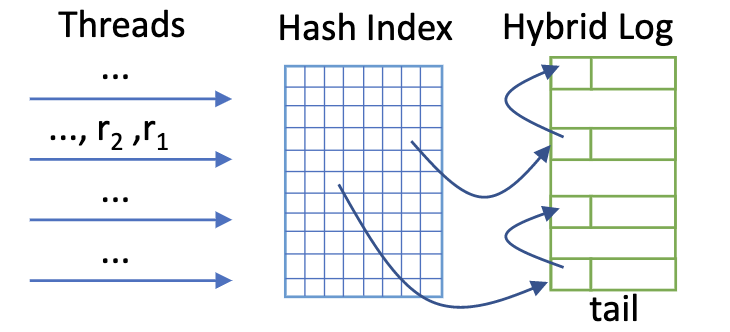
FishStore:
- 借鉴了FASTER的索引架构和Epoch保护框架,
- 扩展记录头,使其变长,以支持多PSF链表连接
- 借鉴FASTER的Hybrid Log分段设计,不过没有mutable region
3.2. Mison
FishStore使用Mison来解析半结构化的数据(如JSON, CSV),它只会解析记录中某些感兴趣的字段,以提高性能。
4. FishStore系统概览
4.1. FishStore中的操作
a) 数据收集
FishStore并行接收一批批的原始记录,然后使用解析器解析指定的字段,接着根据这些字段建立索引,最后插入到存储中。
整个流程无锁。
b) 按需索引
FishStore允许动态加载/卸载PSF。
对于每个活跃的PSF,FishStore会构建一个子集散列索引,它会为每个记录属性$(f, v)$构建索引,构造一个散列环。
FishStore不会为旧数据重新构建索引,因此需要确定索引存在的边界:
- PSF加载时,需要计算安全日志边界(起始边界),这个边界下所有的记录都已被索引
- PSF卸载时,需要计算索引的末尾边界
- 有了边界后,可知道某个区间某个PSF是否可用
c) 记录检索
FishStore支持对某段日志检索满足条件的记录,检索支持2个方式:
- 完整扫描
- 索引扫描
检索优先使用索引。若某段区间,记录被部分索引,则会结合上面两种方法。
4.2. 系统架构
FishStore架构组成有:
- 类Hybrid Log结构,用于存储数据
- 关闭mutable region,只追加记录
- 地址空间管理类似于FASTER提及的
- 追加使用无锁操作
- 散列索引
- 作为数据记录的入口,它记录了记录链表的头指针,链表项拥有一样的$(f, v)$
- 注册服务
- 接收索引请求(PSF),并传播到数据输入器中(基于Epoch线程模型),并开始构建索引
- 数据收集器
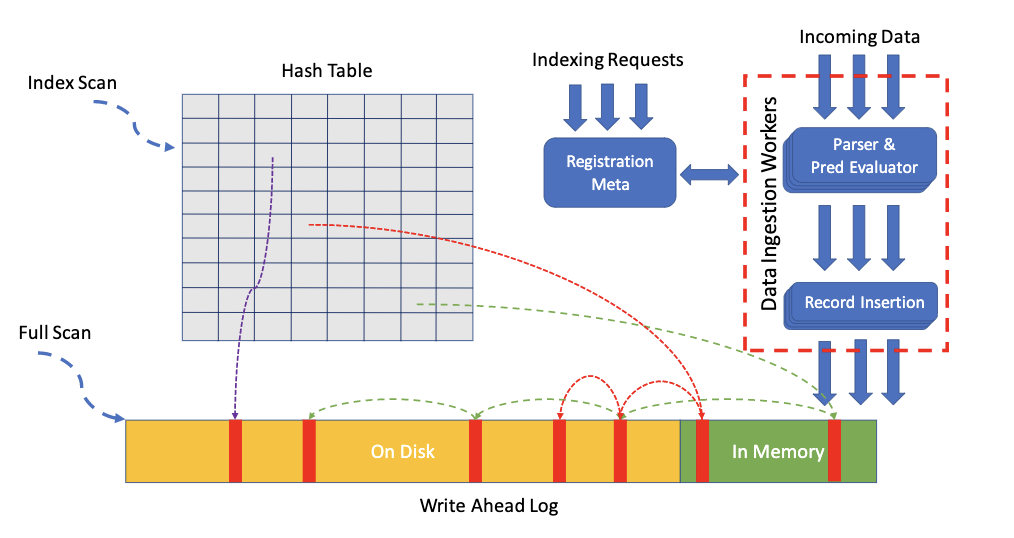
4.3. 挑战
- 实现多PSF的无锁并发索引构建
- 基于Epoch线程模型,计算日志的安全边界,以应对按需索引的需求
- 数据收集和存储需要并发且无锁
- 索引扫描时会触发多次随机I/O,需要引入预读机制,以提高局部性,降低I/O次数
5. 子集散列索引
FishStore引入了子集散列索引:
- 将所有相同记录属性($(f, v)$)的记录构建一个散列环
- 散列环入口(即索引项)位于散列索引表中,可通过计算$(f, v)$的散列签名找到索引项
而FishStore支持多PSF,因此一个记录可以在多条散列环中存在。
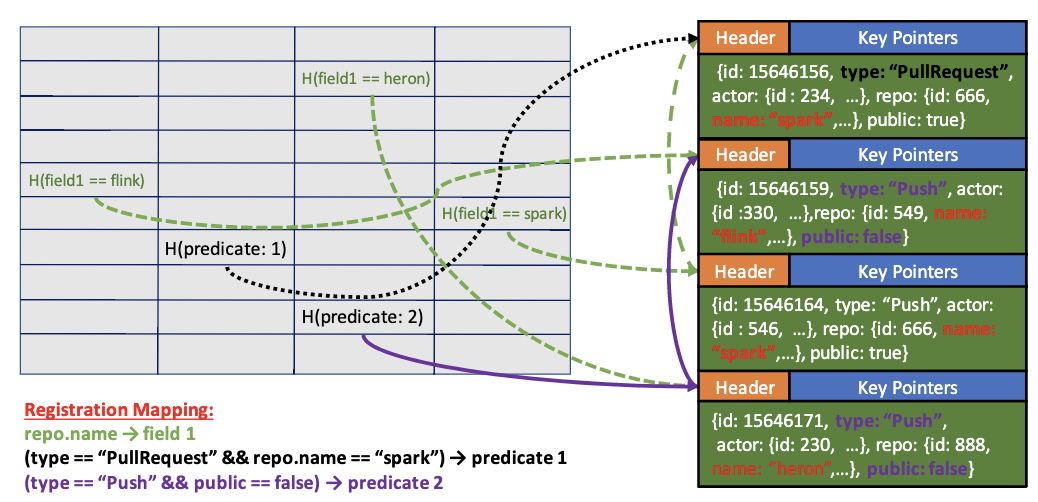
5.1. 记录属性的散列签名
由于不能直接给$f$进行散列,所以引入了命名系统,它会给$f$附上ID。因此计算散列签名$H(f,v)=H(f(r)=v)=Hash(fid(f).concat(v))$。
5.2. 记录存储布局
由于记录会存在多条散列环(索引)中,为了有更好的局部性,FishStore的记录需要将多个散列环的指针存储在一起。
具体结构如下所示:
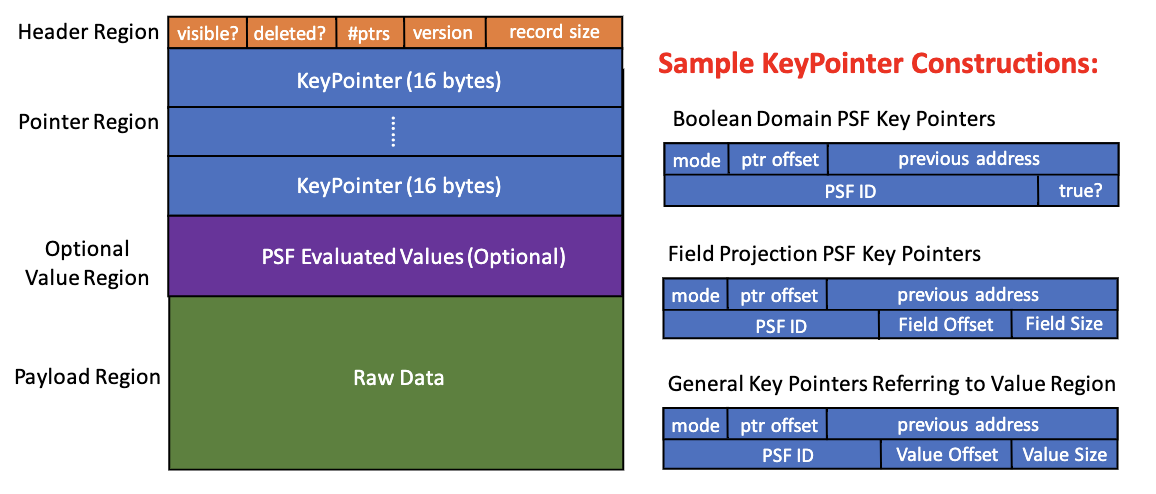
- Header Region:存放一些基本的元数据,如是否可见,是否已经删除,检查点版本,记录大小以及散列环指针的个数
- Pointer Region:存放散列环指针,指向下一条记录,每个指针代表了每个PSF对应的索引,它的个数可变,而指针是定长的
- 指针有多种模式,如上图所示
ptr_offset:可以引导指回记录头;previous_address:指向前一个散列环的记录,但它指向记录的位置也是一个对应PSF的指针;psf_id:指定的PSF ID- 为了解决散列冲突,需要有对应的值信息
- 若值小,则inline存储
- 否则给一个指针,指向这个值(指向Optional Value Region)
- Optional Value Region:可选,可能包含已注册PSF的需要预计算的值
- Payload Region:记录原始数据
5.3. 按需索引
用户可以随时启动或者停止索引的建立,不需要阻塞数据收集。这里使用了Epoch框架,这里和FASTER的类似,不再叙述。
a) 处理索引注册和卸载
当索引注册和卸载时,需要更改其元数据。FishStore使用多阶段方式来更改索引的元数据,如下图所示:
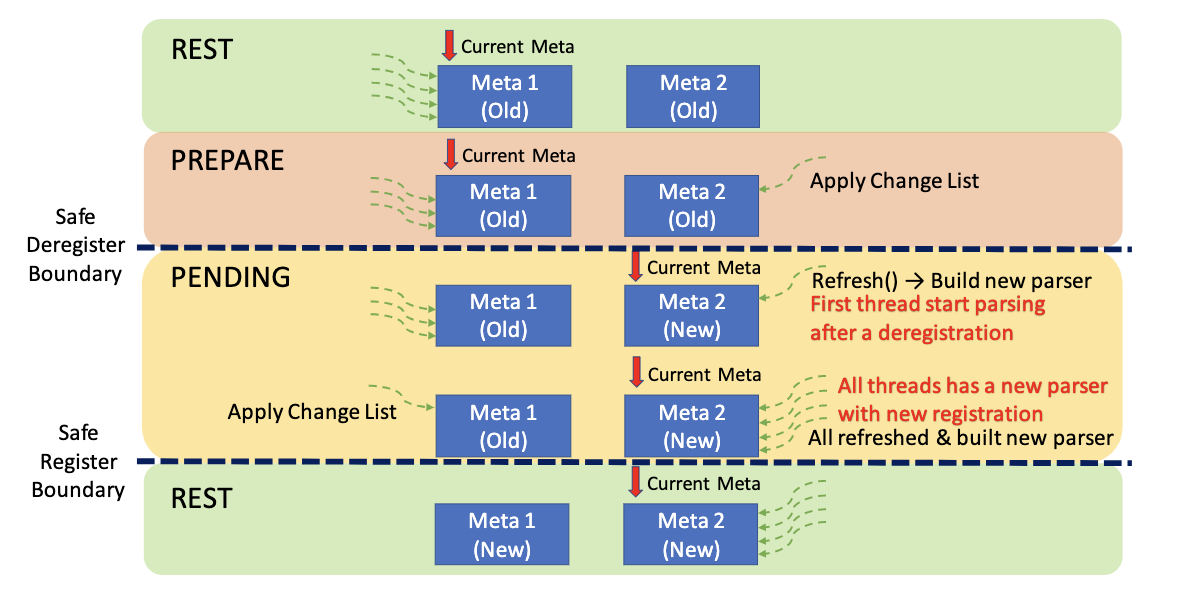
FishStore保存了2个版本的索引元数据:
- 初始时,两份元数据都是
REST状态,它们都没启用 - 当索引请求进来后,状态立刻变成
PREPARE,并立刻将变更应用到某一份元数据中 - 选择已经变更的元数据作为当前元数据,调用
BumpEpoch(Action),Action是应用变更到另一份元数据上,然后将状态变更到PENDING - 当
epoch刷新时,所有线程都看到元数据改变,并重建解析器,以解析新的字段,并将线程内的索引元数据更新 - 当
epoch安全时(即所有线程都看到元数据变更并应用更改后),将变更到另一份元数据上,状态变成REST,变更结束
b) 日志的安全边界
这里需要计算索引加载和索引卸载的两个日志安全边界,在这个边界内,索引有效。
- 加载边界:
PENDING到REST时,保证所有线程都已经看到了新元数据,所以此时作为加载边界 - 卸载边界:
PREPARE到PENDING时,保证所有线程都没有停止构建旧的索引,所以此时作为卸载边界
6. 数据收集与存储
数据收集和存储需要经过4个步骤:解析和PSF计算、记录空间分配、子集散列索引更新、设置记录可见性。
6.1. 解析和PSF计算
首先,原始数据会被解析器(Mison),将原始数据中感兴趣的字段解析出来;
每个线程都有一个解析器,当PSF加载和卸载时,解析器会重新创建
接着,根据解析出的值,为每个记录计算PSF的值,为索引构建提供足够信息。
6.2. 记录空间分配
首先,根据6.1.计算分配空间的大小:若原始数据大小为$s$,有$k$个属性,那么至少需要$8+16k+\lceil \frac{s}{8} \rceil \times 8$字节(若Optional Value Region为空);
接着,原子性将日志尾往后移动,日志尾在环形缓冲中,和FASTER类似;
然后,拷贝原始数据到Payload Region,并填充Header Region,并设置visible = false(因为没有设置索引,所以不可见)
下面就需要构建索引。
6.3. 子集散列索引的更新并设置记录可见性
FishStore的散列表结构和指针设置,与FASTER非常的类似,其操作在FASTER的文中已经提及, 这里不再叙述。
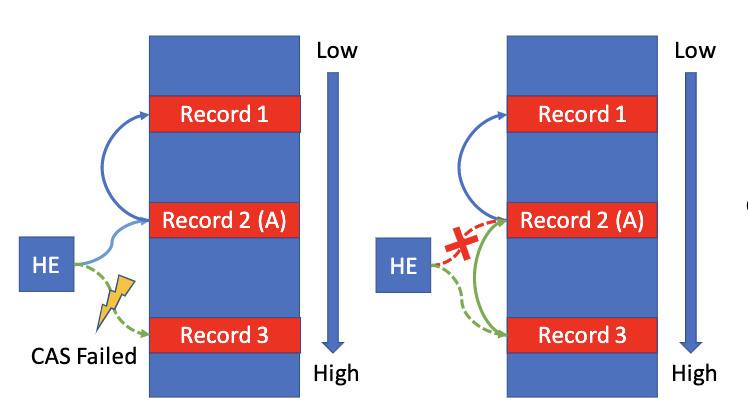
不过需要注意,当CAS设置索引或指针失败后,需要标记记录为无效,并重新执行6.2.,在日志尾分配新的空间。不过这引入了一些问题,造成写放大的问题:
- 很多记录会有一样的$(f, v)$,CAS失败次数会很多
- 记录会存在于多个散列环,而任意散列环上的CAS失败都会导致新的空间分配
解决上面的问题,FishStore对CAS的使用进行了修改,解决写放大的问题:
-
当索引指向的记录地址小于当前记录的地址:直接CAS重试修改即可,不需要分配新的空间
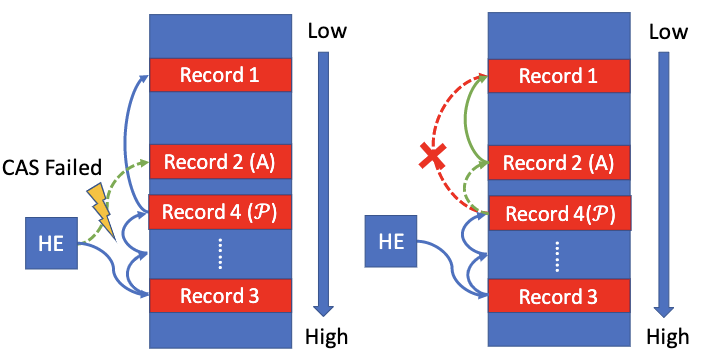
-
当索引指向的记录地址大雨当前记录的地址:
- 从散列索引开始,沿着散列环扫描,找到一个记录$\mathcal{P}$,它的指针指向下一项的地址小于当前记录$A$的地址,而记录$\mathcal{P}$的地址要大于当前记录$A$
- 然后CAS设置指针,将记录$A$的指针指向$\mathcal{P}.next$,然后将$\mathcal{P}.next$指向$A$
-
若2点情况下,CAS还是失败:还是在2点情况下,直接按2重试即可
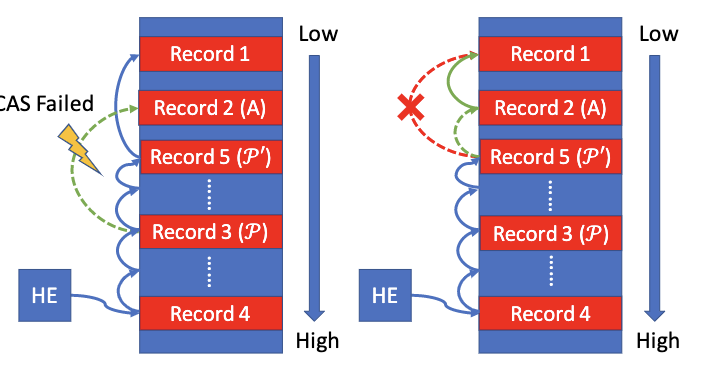
索引和散列环设置完成后,设置visible = true,让记录可见即可。
7. 子集检索
7.1. 子集检索接口
FishStore可以检索某个日志范围内,满足给定属性$(f, v)$的所有记录。
而由于按需索引,日志范围内的记录可能部分索引,因此检索记录时,基于索引加载和卸载边界,将日志扫描和索引扫描结合起来。
日志扫描需要解析每条记录并计算PSF
用户也可以在外部停止扫描,使用Touch函数。
7.2. 适应性预读
执行索引扫描时,若记录在磁盘,会造成大量的I/O,且I/O几乎是随机的,这会导致性能损耗。
原因:
- 大量I/O即大量系统调用,陷入内核会有额外开销
- 每次I/O的数据量非常小,导致I/O队列几乎是空的,且无法利用SSD内部的并行特性
因此FishStore提出了适应性预读,检测散列环的局部性,并预读更多的日志数据,从而减少随机I/O的次数。下图中,红色框框即通过散列环的局部性,进行预读的内容,可见显著降低了随机I/O的次数。

预读的总体思路是:
- 对于当前记录,若下一个记录的位置和本记录的位置相差不大(满足一定的局部性),则一直顺序读下去
- 顺序读时,直到下一个记录的位置和本记录的位置相差很大的时候,退回随机读取
预读的阈值计算如下:
- 计算减少一次随机预读的性能节省开销:$\Phi = (cost_{syscall}+latency_{rand}) \times throughput_{seq}$
- $cost_{syscall}$:经验值
- $latency_{rand}$和$throughput_{seq}$:从磁盘说明中获取
- 计算阈值:$\tau = \Phi + avg_{rec_size}$
- $avg_{rec_size}$:对进入系统对记录进行profiling,然后进行大小的估计
8. 总结
整体而言,我个人认为本文工作基于FASTER之上,它最主要的创新点在于索引的部分,将$(f,v)$作为索引而非记录的键,从而可以快速地按照$f$的方式进行范围检索和处理。本质上,它是对散列索引对象的泛化。而这种泛化,使得其在单点查询的基础上,提供了其他非常多的查询模式下的高性能。
其他的创新点就是预读了,它根据散列环上2个记录的距离,判断是否线性读,它显著降低了I/O,尤其是随机I/O的次数,提高了性能。
缺点也有,主要在于它的存储不支持in-place更新,会导致一些存储瓶颈,不过文中说未来会实现。
