1. Kubernetes网络模型
即IP-per-Pod模型:
-
每个Pod 1个IP,Pod内容器共享IP
-
Pod之间可以直接通信,不需要NAT
-
Pod内部的应用看到自己的IP和端口,与集群内其它Pod看到的一样,即Pod的IP地址,兼容性好
-
不需NAT转换
-
服务配置简单
-
DNS可适用
-
该模型对集群网络有如下要求:
-
所有Pod可相互通信,不需NAT
-
所有节点的代理程序(如
kubelet等)都可与所有Pod通信,不需NAT -
以
hostNetwork模式运行的Pod能与所有Pod通信,不需NAT
若已有程序在VM运行,VM有独立IP,且相互能直接透明通信,则符合IP-per-Pod模型
公有云:基本符合上述要求(如GCE、AWS、Azure)
私有云:在部署k8s+Docker集群前,需要搭建该网络环境,有很多开源组件可以实现,可根据具体场景选择。
2. 网络基础
Docker等容器依赖Linux内核技术,本节介绍相关主要技术。
2.1. 网络命名空间
用于网络资源的隔离,以虚拟多个不同网络环境。
实际上就是Linux的namespace内核级别的资源隔离机制,其中的包含了网络部分,不同namespace进程彼此见资源互相不可见。
2.2. Veth设备对
用于不同namespace进程的两两网络通信,包括:
-
容器与容器间
-
容器与宿主机间
Veth引入是成对的,将两个namespace连起来,需要把它们分配到不同的namespace中。
类似将2台主机用网线直接相连
2.3. 网桥
用于不同网络间的相互通信。
二层的虚拟网络设备(链路层),将若干网络接口“连接”,并根据目标MAC地址信息,以实现数据传输。
类似二层交换机
和交换机不同,数据传输可能只在网桥内的端口传输,也可能抛到上层处理(网络层)。
例如:3个VM绑定1个网桥
-
Veth设备对,一个绑在VM侧,一个绑在网桥侧
-
绑在网桥的3个VM通信走链路层,否则抛到上层网络栈
-
而外部只需知道网桥即可,不需知道内部桥接细节
网桥的IP地址:
-
可不配,若要外部访问才需要配置
-
为方便通信,一般配置同一网段的IP
-
绑定在网桥的网卡不配IP,但对应主机一般配同一网段IP,以相互
ping通
2.4. iptables与Netfilter
用于自定义处理数据包,包括:过滤、修改、丢弃、转发等。
Netfilter:内核态执行规则
iptables:用户态执行规则
2.5. 路由
Linux系统拥有路由功能(网络层),维护路由表实现。
通过路由表路由,若不匹配则转发到默认路由器。
通过ip route命令查看路由状态。
3. Docker网络实现
Docker支持4种网络模式:
-
host模式:直接使用宿主机网络
-
container模式:和已有容器共享网络
-
none模式:容器与主机、容器之间网络隔离
-
bridge模式:默认,使用网桥
-
创建虚拟网桥
docker0,并给其分配一个子网IP -
每个容器创建一个Veth设备对,一端为网桥
docker0,另一端为容器内eth0设备 -
容器内
eth0附上IP,与网桥属于同一个子网
-
3.1. Docker启动时的网络配置变化
-
iptables规则变化
-
docker0网桥和iptables规则在root命名空间下 -
若数据包目的地非
docker0,而是发到外部,则需要通过NAT将IP替换成宿主机 -
docker0发出的包到非docker0网络的设备是允许的,即容器可以访问外部网络 -
docker0的包可被中转到本身,即允许网桥内不同容器可相互通信 -
若接收的数据包属于以前已经建立好的连接,那么允许直接通过
-
-
路由表没特别的变化
3.2. 启动容器后的网络配置变化(无端口映射)
宿主机:
-
路由表和iptables规则无变化
-
宿有一个Veth设备,连接到容器的配对的Veth设备
容器:
-
Veth设备命名为
eth0,IP和docker0网桥属于同一网段 -
路由表:包含一条
docker0子网路由和一条到docker0的默认路由
3.3. 启动容器后的网络配置变化(有端口映射)
其它和3.2.一样,只有宿主机iptable规则发生变化,主要是:
-
增加DNAT规则,修改目标端口和IP,使其和端口映射对应
-
DNAT规则修改后的数据,回重新经过路由进行判断和转发
3.4. Docker网络局限性
未考虑多主机的通信方案。
Docker官方的Libnetwork: https://github.com/moby/libnetwork ,现在也不怎么更新
4. Kubernetes网络实现
4.1. 容器与容器之间的通信
同个Pod中的容器共享1个网络命名空间(即网络资源共享),彼此通信只需要互相访问localhost即可。
4.2. Pod之间的通信
每个Pod拥有1个全局IP地址,不同Pod可之间通过IP通信。
a. 同一Node上的Pod通信
类似Docker网桥:
-
创建网桥
docker0,分配一个子网 -
每个Pod创建一个Veth设备对,一端为网桥
docker0,另一端为Pod内eth0设备 -
Pod
eth0的IP从docker0网段上动态获取,属同一个网段
即Pod间的通信必须经过网桥docker0中转,又属于同一网段,因此能直接通信。
b. 不同Node上的Pod通信
需要满足2个条件:
-
对整个Kubernetes集群的Pod IP进行规划,不能冲突
即对每个Node的
docker0网桥进行IP规划,使其不冲突。可手动,也可程序自动(如Flannel) -
将Pod IP和所在Node IP关联,以实现相互访问
通路:Pod A
eth0-> 宿主机A网桥docker0-> 宿主机A网卡eth0-> 宿主机B网卡eth0-> 宿主机B网桥docker0-> Pod Beth0。宿主机需要实现网络层的路由,将
dstPod IP的流量转发到目标Node上。一个例子见4.3.的图示
将Pod IP和所在Node IP关联,及相关路由,可以由第三方组网组件实现,之后会叙述。
c. Pause容器
用于接管Pod内应用容器的网络,负责Pod的Endpoint。
Pause容器默认以bridge模式运行。
其它容器使用container模式运行,与Pause容器共享一个网络namespace。
实际上,Pause容器运行逻辑为:一启动,就把自己暂停住,什么都不做。
它作为“父容器”的存在,通过管理父容器,子容器可与父容器共享资源,并管理这些容器的生命周期:
- 在 Pod 中它作为共享 Linux Namespace(Network、UTS 等)的基础;
- 启用 PID Namespace 共享,它为每个 Pod 提供1号进程,并收集 Pod 内的僵尸进程。
参考: https://segmentfault.com/a/1190000021710436
4.3. 内部的Service与Pod通信
见前文,关键词:
-
DNS(
core-dns)+ ClusterIP -
kube-proxy
创建Service后
-
会分配一个ClusterIP,不属于
docker0网段与Node网段,以让所有容器的流量都走向docker0网桥 -
iptables创建重定向和DNAT规则,将经过ClusterIP的流量转发到本地
kube-proxy
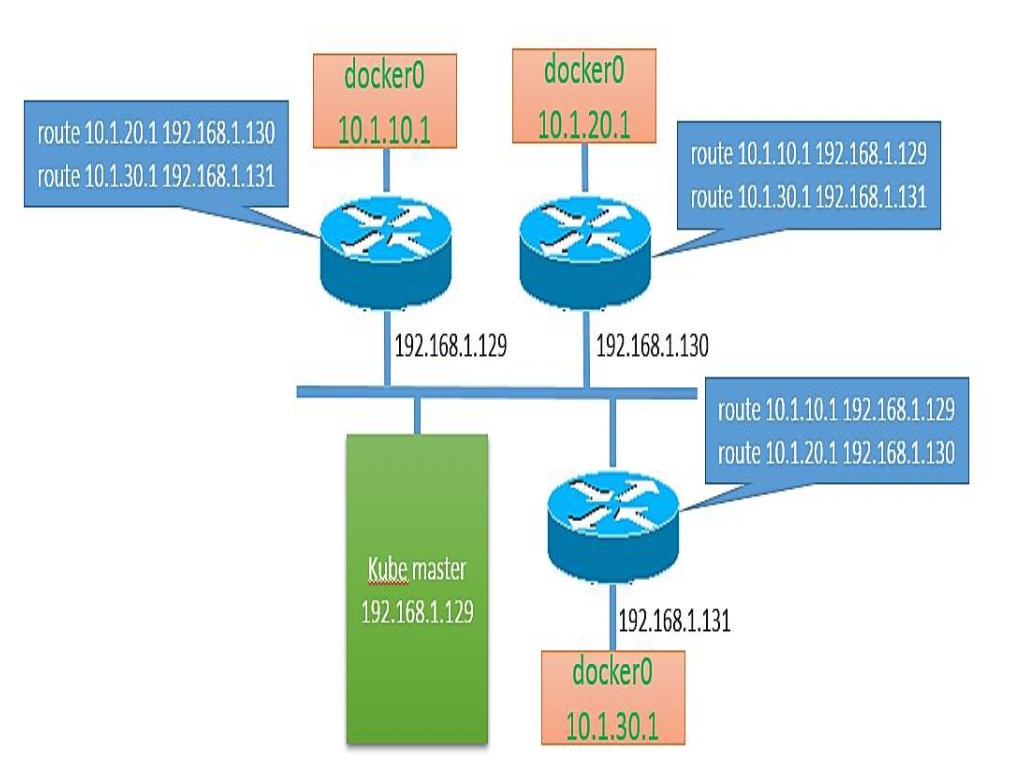
访问服务的网络拓扑配置和流量通路如下:
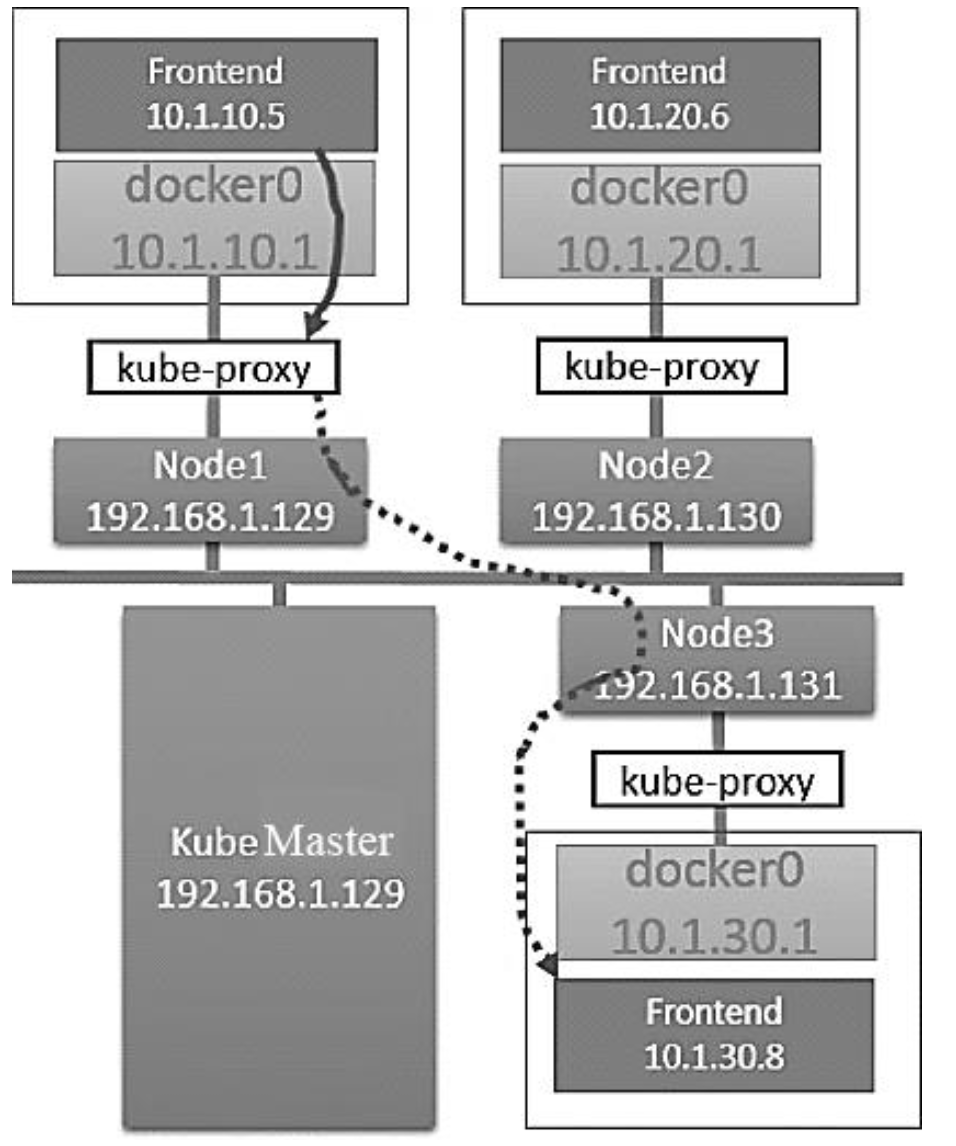
-
Pod访问ClusterIP,流量
dst为ClusterIP,被iptables转发到本地kube-proxy -
kube-proxy负载均衡,直接转发流量到目标Pod上-
流量
dst从ClusterIP换成目标Pod IP(DNAT) -
流量经过网桥
docker0,然后抛到上层宿主机,进行路由
-
-
源Node需配置路由表,流量通过宿主机
eth0,直接路由到目标Node上- 例如Node1:目标为
10.1.30.8的流量需要转发到192.168.1.131
- 例如Node1:目标为
-
目标Node收到流量,
dst为Pod IP,由于在同一台机器上,可直接访问服务 -
返回响应类似,但不需经过
kube-proxy,属于不同Node的Pod之间的通信- 响应的
src从目标Pod IP替换成ClusterIP(Reverse DNAT)
- 响应的
4.4. 集群内部与外部的通信
同样见前文,关键词:
-
NodePort
-
LoadBalancer
-
ExternalName
-
Ingress
建议的参考:Calico
https://projectcalico.docs.tigera.io/about/about-kubernetes-services
Calico把组网的背景、通信图示显示的非常清楚,可以参考
